








作者:Jason Brownlee
编译:Florence Wong – AICUG
本文系AICUG翻译原创,如需转载请联系(微信号:834436689)以获得授权
不平衡的分类,涉及在具有严重的类别不平衡的分类数据集上,开发预测模型。
使用不平衡数据集的挑战在于,大多数机器学习技术将忽略少数类,并且在少数类上表现不佳,然而,通常最重要的其实是在少数类上的表现。
解决不平衡数据集的一种方法是对少数群体进行过度采样。最简单的方法是在少数类中复制实例,尽管这些实例不会向模型添加任何新信息。相反,可以从现有实例中合成新实例。这是针对少数群体类别的一种数据增强类型,被称为“ 综合少数群体过采样技术(Synthetic Minority Oversampling Technique)”,简称SMOTE。
在本教程中,您将学习用SMOTE,对不平衡分类数据集进行过采样。
完成本教程后,您将知道:
- SMOTE如何为少数群体综合新的例子。
- 如何在SMOTE转换后的训练数据集上正确拟合和评估机器学习模型。
- 如何使用SMOTE的扩展,这些扩展会配合类决策边界生成综合实例。
教程概述
本教程分为五个部分。他们是:
- SMOTE
- 不平衡学习库(Imbalanced-Learn Library)
- 平衡数据的SMOTE
- 面向分类的SMOTE
- 具有选择性综合样本生成功能(Selective Synthetic Sample Generation)的SMOTE
- 边界线-SMOTE(Borderline-SMOTE)
- 边界线-SMOTE支持SVM
- 自适应合成采样(ADASYN)
SMOTE
分类不平衡的问题在于,少数类的例子对于模型而言太少,无法有效地学习决策边界。
解决此问题的一种方法是对少数类中的实例进行过度采样。这可以通过在拟合模型之前,简单地从训练数据集中,复制少数类的实例来实现。这样可以平衡类的分布,同事不向模型提供任何其他附件信息。
对少数群体中复制实例方法的一个改进是,从少数类中综合新实例。这是面向列表数据的一种数据扩充,非常有效。
综合新实例的最广泛使用的方法也许叫做“ 综合少数类过采样技术”,简称SMOTE。Nitesh Chawla等人描述了此技术。在他们2002年的论文中,为该技术命名,题为“ SMOTE:综合少数族类的过采样技术”。
SMOTE的工作方式是选择特征空间中较近的实例,从而在特征空间中的实例之间绘制一条线,并沿着该线的一点绘制一个新样本。
具体而言,首先从少数类中选择一个随机实例。然后去发现,该实例中的最近的邻居数k(通常K = 5)。选择一个随机选择的邻居,并在特征空间中两个实例之间的,一个随机选择的点上,创建一个综合实例。
“…SMOTE首先随机选择一个少数类实例a,然后找到它的k个最近的少数群体邻居。然后,通过随机从k个最近的邻居选择一个b,并将a和b连接以在特征空间中形成线段,从而来创建综合实例。综合实例将作为两个选定实例a和b的凸组合生成。”
—第47页,不平衡的学习:基础,算法和应用,2013年。
此过程可用于为所需的少数类创建尽可能多的综合实例。如上述提及的论文所述,建议首先使用随机欠采样,来“修剪”多数类中的样本数量,然后使用SMOTE对少数类进行过采样以平衡类分布。
“SMOTE和欠采样的组合比纯欠采样性能更好。”
— SMOTE:综合少数类过采样技术,2011年。
该方法之所以有效,是因为创建了来自少数派类别的新的综合实例,这些实例应该是合理的,也就是说,他们在特征空间上与现有的来自少数类的实例相对较近。
“我们的综合过采样方法,可以使分类器建立包含附近少数类点的,较大决策区域。”
— SMOTE:综合少数类过采样技术,2011年。
该方法的缺点是,在不考虑多数类的情况下创建了综合实例,如果这些类之间存在很强的重叠,则可能导致歧义实例。
现在我们已经熟悉了该技术,下面让我们来看一个解决不平衡分类问题的实例。
Imbalanced-Learn Library
在这些实例中,我们将使用不平衡学习Python库提供的实现,可以通过pip如下安装:
sudo pip install imbalanced-learn您可以通过打印已安装的库的版本来确认安装成功:
# check version number
import imblearn
print(imblearn.__version__)运行示例将打印已安装库的版本号;例如:
0.5.0平衡数据的SMOTE
在本节中,我们通过将SMOTE应用于不平衡的二元分类问题,从而初步认识SMOTE。
首先,我们可以使用make_classification()scikit-learn函数,创建具有10,000个实例,1:100类分布的,综合二进制分类数据集。
...
# define dataset
X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0,
n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1)我们可以使用Counter object来汇总每个类中的实例数量,以确认正确创建了数据集。
...
# summarize class distribution
counter = Counter(y)
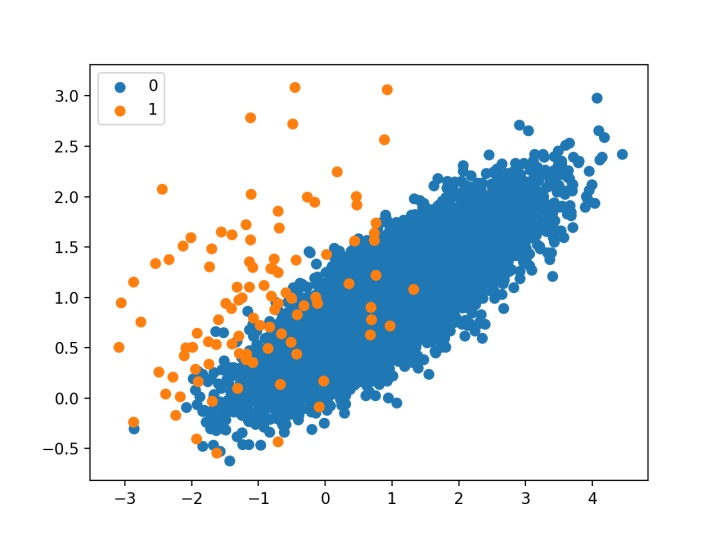
print(counter)最后,我们可以创建数据集的散点图,并为每个类的实例着不同的颜色,以清楚地看到类不平衡的空间性质。
...
# scatter plot of examples by class label
for label, _ in counter.items():
row_ix = where(y == label)[0]
pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
pyplot.legend()
pyplot.show()综上所述,下面列出了生成和绘制综合二进制分类问题的完整示例。
# Generate and plot a synthetic imbalanced classification dataset
from collections import Counter
from sklearn.datasets import make_classification
from matplotlib import pyplot
from numpy import where
# define dataset
X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0,
n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1)
# summarize class distribution
counter = Counter(y)
print(counter)
# scatter plot of examples by class label
for label, _ in counter.items():
row_ix = where(y == label)[0]
pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
pyplot.legend()
pyplot.show()运行示例,首先总结类的分布,并确认1:100的比例,在这种情况下,多数类中有大约9,900个实例,少数类中有100个实例。
Counter({0: 9900, 1: 100})创建了数据集的散点图,显示了属于多数类的大量点(蓝色)和属于少数类的,分散的少量点(橙色)。我们可以看到两个类之间有某种程度的重叠。
接下来,我们可以使用SMOTE对少数类进行过采样,并绘制转换后的数据集。
我们可以使用SMOTE class中不平衡学习Python库(imbalanced-learn Python library)提供的SMOTE实现。
SMOTE函数,就像来自scikit-learn的数据转换对象一样,必须定义和配置它,使其适合数据集,然后应用于创建数据集的一个新转换版本。
例如,我们可以使用默认参数定义一个SMOTE实例,该实例将平衡少数类,然后一步完成拟合并应用,以创建我们的数据集的转换版本。
...
# transform the dataset
oversample = SMOTE()
X, y = oversample.fit_resample(X, y)转换后,我们可以总结新转换后的数据集的类分布,现在希望可以通过在少数类中创建许多新的综合实例来实现平
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 346
346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









