






太长不看版:
- Excel可以用
数据>删除重复项把一组数据里面的重复单元格删掉, 但是这种操作要依靠手动, 不能自动更新, 所以如果你的数据来源发生更新的时候要自己重新做一遍, 容易出错 - 要想能够自动完成
数据>删除重复项的功能, 用下面这个公式就可以了. 假设需要删除重复项的这组单元格是A2:A11, 删除重复项以后的唯一值列表放在C列, 在C2放置这个公式, CTRL+SHIFT+ENTER完成输入, 之后把单元格向下填充
=IFERROR(INDEX($A$2:$A$11,MATCH(0,COUNTIF($C$1:C1,$A$2:$A$11),0)),"")搞定.
我们都知道可以用数据>删除重复项获得一个唯一元素列表。很多时候这个操作已经够我们用了,但是其实呢,就像筛选可以用公式实现一样,删除重复项这个操作也一样可以用公式搞定。
方法就是把index, match还有countif连起来用,当然iferror也要用上。
内容来源:How to Get Unique Items from a List in Excel Using Formulas
比如A2:A11是这么一组数据:1,1,1,2,2,3,4,5,5,6
然后做一个删除重复项就成了C2:C7的这一些东西:1,2,3,4,5,6
公式长成这样:=IFERROR(INDEX($A$2:$A$11,MATCH(0,COUNTIF($C$1:C1,$A$2:$A$11),0)),"")
上面的公式可以拆成下面几块:
countif($C$1:C1,$A$2:$A$11),这个记作countif(...)match(0, countif(...),0),这个记作match(...)index($A$2:$A$11, match(...)), 这个记作index(...)- match找不到的时候会报错,所以最外面再套一个
iferror(index(...),"")
上面这个公式是一个数组公式,完成输入以后要按ctrl+shift+enter,而不是enter。
1. countif
这个地方最绕的应该还是countif. 我尽量说明一下.
首先如果是=countif($A$2:$A$11,$A$2:$A$11) 如果在excel里面用数组形式输入这个公式, 返回的结果是 3. 这个3指的是$A$2:$A$11 1这个值出现了3次. 如果我们把A2:A11的数据重新排列一下顺序: 2, 1, 3, 4, 1, 2, 5, 1, 5, 6, 这个公式就会返回2, 因为2这个值出现了2次. 如果我们在公式外面再套一个其他的公式, 然后用公式> 公式求值去看一下计算过程的话就会看到:
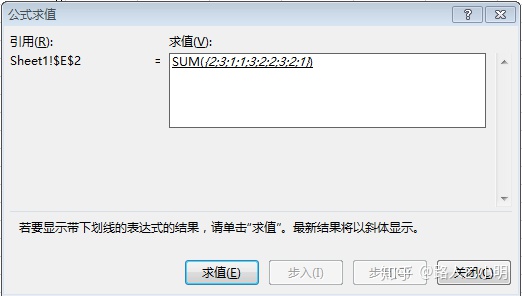
可以看到对=countif($A$2:$A$11,$A$2:$A$11)求值的结果是:{2;3;1;1;3;2;2;3;2;1} , 也就是这个数组里面, 2出现了2次,1出现了3次,3出现了1次,4出现了1次,1出现了3次,2出现了2次,5出现了2次,1出现了3次,5出现了2次,6出现了1次.
这就是当我们把criteria设置成一个范围内的单元格的时候会产生的结果.
2. match和index
接下来看看第二层, match. 还是借助公式求值这个工具, 这次我们在C2这个单元格输入
=MATCH(0,COUNTIF($C$1:C1,$A$2:$A$11),0)记得按CTRL+SHIFT+ENTER! 返回结果是1
然后在C2这里做一个公式求值, 求值结果是: =MATCH(0,{0;0;0;0;0;0;0;0;0;0},0)
从这个公式来说, MATCH返回1是没问题的, 毕竟这个数组第一个就是0. 但是现在还是看不出来和我们向问题有什么关联. 但是接下来把index再套上去就不一样了, 这个时候返回的结果是2. 如果我们把A2:A11里面所有的2都替换成Feb呢? C2这个时候也会变成Feb. 这是肯定的, 毕竟=index($A$2:$A$11,1) 肯定就是返回这写个单元格里的第一个嘛.
现在还不太看得出来为什么这么干就能获得唯一值列表, 所以让我们把C2往下填充, 哎, 居然真的就成了唯一值了!

让我们对C7这个单元格做一下公式求值吧:countif(...) 求值以后变成了{1;1;1;1;1;1;1;1;1;0} . 这个时候只有最后一个元素是0, 自然match的时候就会返回最后一个元素的位置, 接下来用index再把位置转换成元素, 也就是6.
下面那一堆#N/A 通过iferror就可以干掉了.
所以最关键的地方还是在countif,拿一系列的单元格来做countif的criteria可以说是一个奇技淫巧了, 在没有写这篇专栏文章以前我真完全没有想到还可以这么干, 下面我画一个图解尝试解释一下吧.
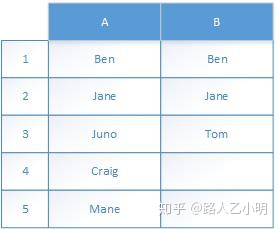
比如在上面这个数据表里面, B列有三个数据:Ben, Jane, Tom,那么现在下面这个公式返回的是几呢?
=countif(B:B,A1) 用A1的值(Ben)作为标准去数B列, B列就只有一个Ben, 那当然就是返回1了啦.
同样的, =countif(B:B, A2)呢?B列有一个Jane, 所以也是1.
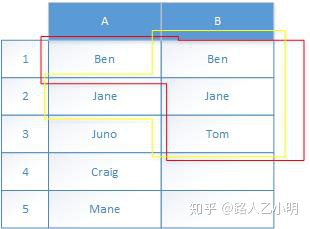
在上面的两个例子里, 被搜索的范围是没有改变的, 都是B列的Ben, Jane, Tom着三个单元格, 但是搜索的标准变了. 那么如果我们把这两次搜索合并成一次搜索是否可行呢? 当然是可以的:
=countif(B:B,A1:A2) 按ctrl+shift+enter转换为数组公式, 这个时候返回的值实际上就是{1;1} 了, 这个结果的意思就是第一次搜索(用A1作标准), 找到了1个, 第二次搜索(用A2作标准), 也找到了1个. 这个就是拿一组数据做countif的criteria时候发生的事情.
那么回到我们的公式
=INDEX($A$2:$A$11,MATCH(0,COUNTIF($C$1:C1,$A$2:$A$11),0))这里面很关键的一点, 就是我们被搜索范围的设定: 从当前列第一个单元格开始($C$1)到当前单元格上一个格子(对C2单元格, 我们设置成了C1, 这个相对关系在向下填充的时候被保留了).
对于C2单元格来说,它上面什么都没有,所以countif(...) 返回的肯定是一堆{0;0....;0},所以呢这个时候=match(0,countif(...),0)跟着返回的就是1, 那再交给index就会把用作criteria的这堆单元格的第一个拿来填到C2里面去.
接下来到C3单元格, 对它来说, 上面已经有了A2:A11这组单元格里面的第一个, 这样一来再去作countif(...) 的时候自然就不会全是0了, A2:A11里面所有值和A2相同的单元格, 对应的countif结果都会变成1. 对于前面提到的Feb, 1, 3, ...这组数据, 到C3的时候countif(...)返回的结果就会是{1;0;0;...} ,那match(...) 返回的结果也就成了2, 再用index就可以获得排在第二的单元格的值1
至于C4单元格,前面两个单元格都已经分别是Feb和1了,那countif的结果肯定会有更多的1,至于下一个0就只会出现在既不是Feb也不是1的单元格, 把这个位置用match拿出来, 再用index转成对应的值, 也就是3. 下面的都是以此类推.
这个想法还真是听精妙的, 而且让我觉得对Excel的功能有了新的认识

















 2443
2443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









