





用于深度学习的图嵌入
有很多方法可以将机器学习应用于图形。最简单的方法之一是将图形转换为更易于理解的ML格式。
图嵌入是一种将节点、边及其特征转换为向量空间(较低维)的方法,同时最大限度地保留图结构和信息等属性。
图很棘手,因为它们在规模、特异性和主题方面会有所不同。
分子可以用一个小的、稀疏的、静态的图来表示,而社会网络可以用一个大的、密集的、动态的图来表示。最终,很难找到通用的嵌入方法。每一种方法在不同的数据集上会有不同的性能,但它们在深度学习中使用最广泛。
嵌入网络图
如果我们把嵌入看作是向低维的转换,那么嵌入方法本身就不是一种神经网络模型。相反,它们是一种用于图预处理的算法,其目标是将图转换为计算上易于理解的格式。这是因为图类型数据本质上是离散的。
机器学习算法是为连续数据而调整的,这就是为什么嵌入总是在连续向量空间。
正如最近的工作所显示的,有各种各样的方法去嵌入图,每一种都有不同的粒度级别。嵌入可以在节点级、子图级或通过图遍历等策略执行。下面介绍一些流行的方法。
DeepWalk - Perozzi等人
Deepwalk并不是第一个这样的方法,但它是第一个被广泛用作与其他图学习方法比较的基准的方法。Deepwalk属于使用walk的图嵌入大家族,这是图论中的一个概念,只要连接到公共边,就可以通过从一个节点移动到另一个节点来遍历图。
如果用任意表示向量表示图中的每个节点,则可以遍历图。该遍历的步骤可以通过在矩阵中排列相邻的节点表示向量来进行聚合。然后你可以把这个表示图形的矩阵输入到递归神经网络中。也就是说可以使用图形遍历的截断步骤作为RNN的输入。这类似于句子中单词向量的组合方式。
至于随机游走产生的网络嵌入为什么能与语言模型中的词嵌入的联系在一起,是因为在现实生活中,随机游走中节点的幂律分布和自然语言中词的幂律分布十分相似
DeepWalk所采用的方法是利用以下方程完成一系列随机漫步:
目标是估计的可能性观察节点
代表了潜在的表示与
潜表示是神经网络的输入。神经网络,基于什么节点和节点在行走过程中遇到的频率,可以做出关于节点特征或分类的预测。
Deepwalk采用了词嵌入技术中的Skip-gram方法思想:(1)不再使用上下文来预测一个缺失词,而是使用缺失词来预测上下文。(2)上下文由目标词的左右两侧组成,不仅仅是一边。(3)最大化词在上下文中出现的概率,并且不需要知道对于给定词的相对偏移位置。新的优化目标总结如下:
当解决了这个优化问题时,我们将获得在局部节点之间存在相似性的潜在社会表示,即当两个节点有相同的邻居节点时,这两个节点将获得相同的表示,并且这性质还可以进行推广到更大的范围中。
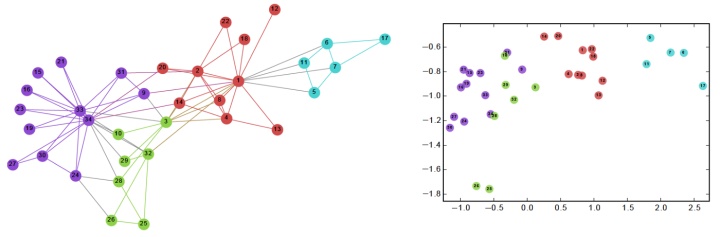
就像用于文本的Word2vec体系结构一样。DeepWalk不是沿着文本语料库运行,而是沿着图来学习嵌入。该模型可以利用目标节点来预测其“上下文”,在图的情况下,这意味着它的连通性、结构角色和节点特征。
虽然DeepWalk的效率相对较高,得分为o(|V|),但这种方法具有转导性,这意味着无论何时添加新节点,都必须对模型进行重新训练,以嵌入并从新节点学习。
Node2vec - Grover等
你已经听说过Word2vec,现在准备Node2vec
作为一种比较流行的图形学习方法,Node2vec是最早的从图形结构数据中学习的深度学习尝试之一。直觉与DeepWalk相似:
如果你把图中的每个节点都变成嵌入,就像你在句子中的单词一样,神经网络可以学习每个节点的表示。
Node2vec和DeepWalk之间的区别很细微,但很重要。Node2vec有一个行走偏置变量,由p和q参数化,参数p优先级是宽度优先级搜索(BFS)过程,参数q优先级是深度优先级搜索(DFS)过程。因此,下一步到哪里走的决定受到概率1/p或1/q的影响。
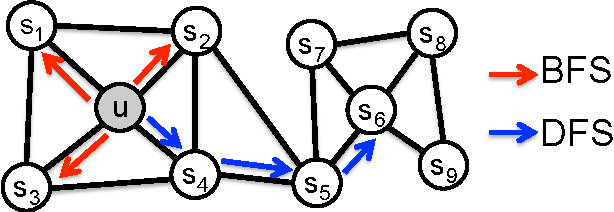
正如可视化所示,BFS是学习局部邻居的理想选择,而DFS更适合学习全局变量。Node2vec可以根据任务来切换这两个优先级。这意味着对于单个图,Node2vec可以根据参数的值返回不同的结果。根据DeepWalk, Node2vec也将walk的潜在嵌入作为神经网络的输入进行节点分类。
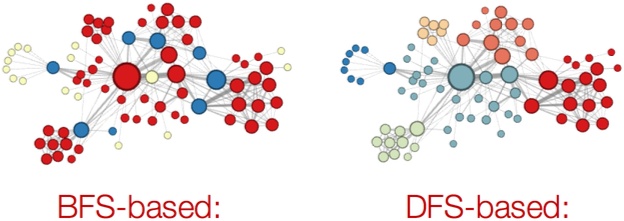
实验表明,BFS能够更好地根据结构角色(枢纽、桥梁、离群点等)进行分类,而DFS返回的是一种更加社区驱动的分类方案。
Node2vec是斯坦福大学致力于图形分析的SNAP研究小组开发的众多图形学习项目之一。他们的许多作品是几何深度学习许多重大进展的起源。
Graph2vec - Narayanan等
作为对node2vec变体的修改,graph2vec基本上学会了嵌入图的子图。doc2vec中使用的一个方程证明了这一点,这是一个密切相关的变体,也是本文的一个灵感点。
这个方程可以写成: 这个词在给定上下文文档出现的概率(
与word2vec类似,如果文档由句子组成(然后由单词组成),则图由子图组成(然后由节点组成)。
这些预先确定的子图有一组边,由用户指定。再一次,它是潜在的子图嵌入被传递到神经网络分类。
结构深度网络嵌入(SDNE)——Wang等
与之前的嵌入技术不同,SDNE不使用随机游走。相反,它试图从两个不同的度量标准中学习:
- 一阶接近度:如果两个节点共享一条边,则认为它们相似(成对相似)
- 二级邻近性:如果两个节点共享许多相邻节点,则认为它们是相似的
最终目标是捕捉高度非线性的结构。这是通过使用深度自动编码器(半监督)来保持一阶(监督)和二阶(无监督)网络的近似性来实现的。
为了保持一阶近似性,该模型还采用了拉普拉斯特征图的变化,即图嵌入/降维技术。在Laplacian特征映射算法中,当相似节点在嵌入空间中映射到距离很远的位置时,会产生惩罚,从而通过最小化相似节点之间的空间进行优化。
通过将te图的邻接矩阵传递给一个必须最小化重构损失函数的无监督自编码器来保持二阶邻近性。
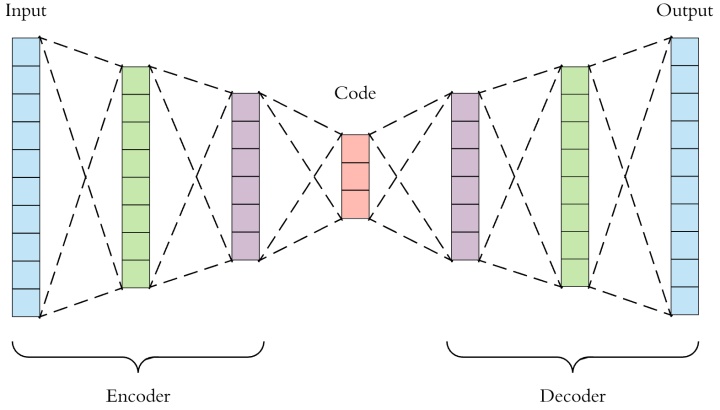
一阶近似损失函数和二阶重构损失函数共同最小化,以返回一个嵌入图。这种嵌入是通过神经网络来学习的。
大规模信息网络嵌入(LINE) - Tang等
LINE (Jian Tang等)明确定义了两个函数;一个是一阶近似另一个是二阶近似。在原始研究所进行的实验中,二阶近似度的表现明显好于一级近似度,这暗示了包括更高阶近似度可能会使精度的提高趋于平稳。
LINE的目标是最小化输入分布和嵌入分布之间的差异。这是利用KL散度实现的:
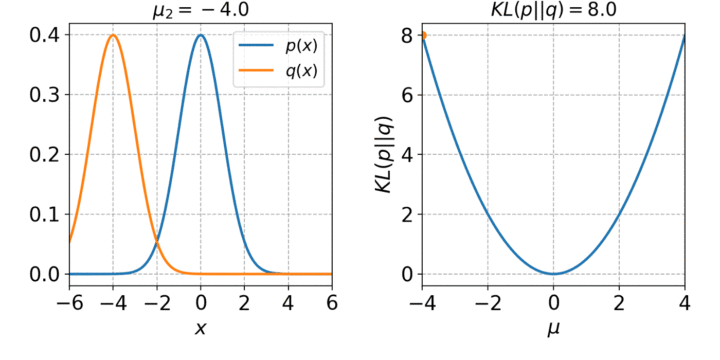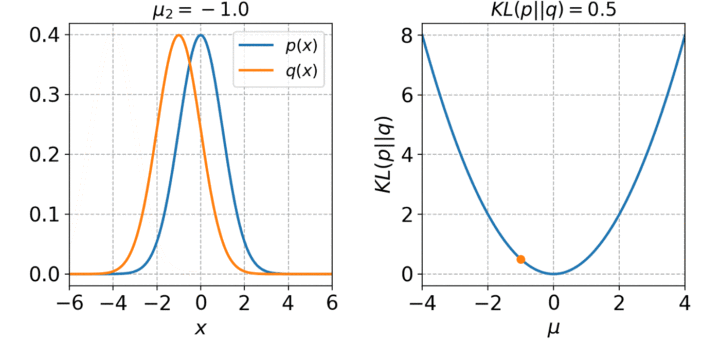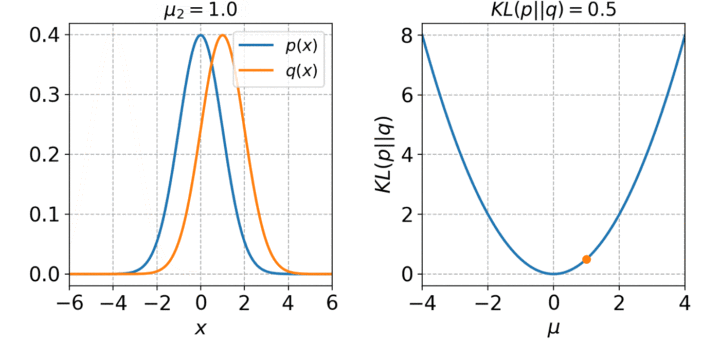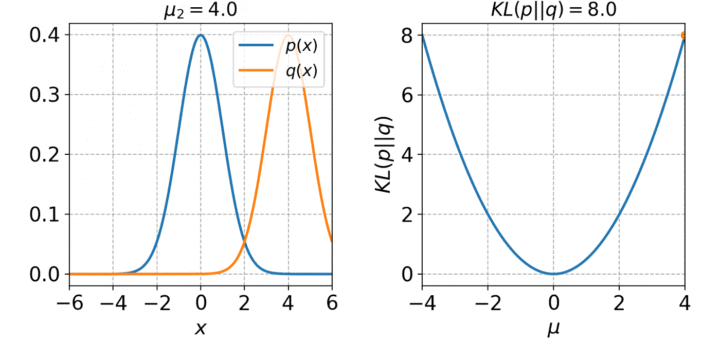
可视化很简单,数学就不那么简单了。
LINE为每对节点定义两个联合概率分布,然后最小化分布的KL散度。这两个分布分别是邻接矩阵和节点嵌入的点积。KL散度是信息论和熵中一个重要的相似性度量。该算法用于概率生成模型,如变分自编码器,它将自编码器的输入嵌入到潜在空间中,从而成为分布。
由于算法必须为每个递增的邻近顺序定义新函数,因此如果应用程序需要理解节点社区结构,LINE的性能就不是很好。
然而,LINE的简单性和有效性只是它成为2015年WWW上被引用次数最多的几个原因。这项工作帮助激发了人们对图形学习的兴趣,将其作为机器学习的利基,并最终在具体的深度学习。
网络的层次表示学习- Chen等
HARP是对前面提到的基于嵌入/行走的模型的改进。以前的模型有陷入局部最优的风险,因为它们的目标函数是非凸的。基本上,这意味着球不能滚到山的绝对底部。
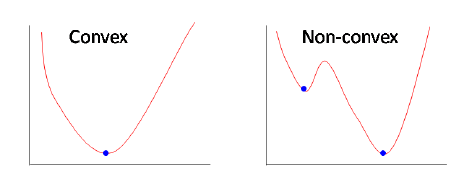
因此,预期动机:
通过更好的权值归化,改进了解,避免了局部最优。 所提方法为: 使用粗化图将相关节点聚合为“超级节点” 。 HARP本质上是一个图形预处理步骤,它简化了图形以加快训练速度。 在粗化图之后,它会生成一个最粗的“超级节点”的嵌入,然后嵌入整个图(它本身就是由超级节点组成的)。
对于整个图中的每个“超节点”都遵循此策略。
因为竖琴可以与以前的嵌入算法如LINE, Node2vec和DeepWalk一起使用。在原论文中,将HARP与各种图形嵌入方法相结合,分类任务得到了高达14%的显著改进,这是一个显著的飞跃。
结语
这篇文章确实漏掉了一些算法和模型,尤其是最近人们对几何深度学习和图形学习的兴趣激增,几乎每天都有新的文章出现在出版物中。
在任何情况下,图嵌入方法都是一种简单但非常有效的方法,可以将图转换为机器学习任务的最优格式。由于其简单性,它们通常具有相当的可伸缩性(至少与卷积对应项相比),并且易于实现。它们可以应用于大多数网络和图形而不牺牲性能或效率。
但我们能做得更好吗? 接下来,我们将深入复杂而优雅的图形卷积世界!
关键点
- 图嵌入技术将图嵌入到一个低维连续的潜在空间中,然后通过机器学习模型将其表示出来。
- 遍历嵌入方法执行图的遍历,目的是保持结构和特征,并将这些遍历集合起来,然后通过递归神经网络进行遍历。
- 接近嵌入方法使用深度学习方法和/或接近损失函数来优化接近度,这样原始图中靠近的节点在嵌入时也同样如此。
- 其他方法在对图应用嵌入技术之前,使用图粗化等方法来简化图,在保持结构和信息的同时降低复杂性。
[1] https://towardsdatascience.com/overview-of-deep-learning-on-graph-embeddings-4305c10ad4a4















 598
598











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









