





前言
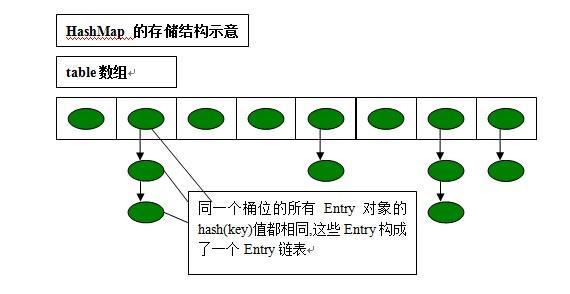
HashMap的主干是一个数组,假设我们有3个键值对dnf:1,cf:2,lol:3,每次放的时候会根据hash函数来确定这个键值对应该放在数组的哪个位置,即index = hash(key)
1 = hash(dnf),我们将键值对放在数组下标为1的位置

3 = hash(cf)
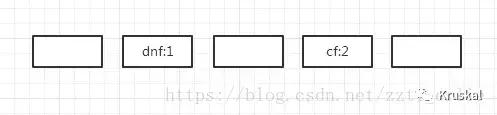
1 = hash(lol),这时发现数组下标为1的位置已经有值了,我们就可以用链表的形式将这个键值对放到dnf键值对的下面
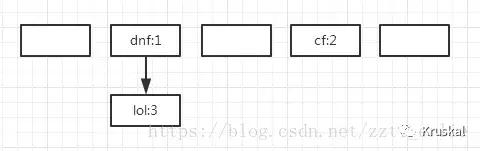
1.7 HashMap采用的是头插法,所以lol:3在数组为1的位置,dnf:1以链表的形式跟在lol:3的下面
在获取key为lol的键值对时,1=hash(lol),得到这个键值对在数组下标为1的位置,lol和dnf不相等,和下一个元素比较,相等返回
源码
基于jdk1.7.0_80,1.8和1.7相比 差不多,1.8只是多了一个新特性,当链表的长度>=8的时候,链表转换为红黑树提高查询的效率,1.7解读起来更容易
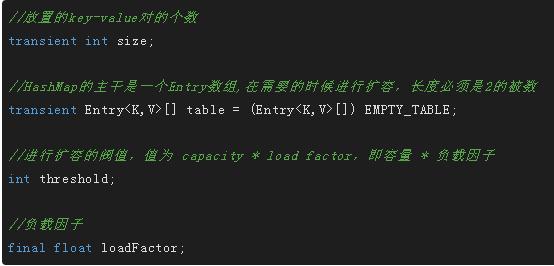
各种默认参数不再细说,这里说一下threshold和loadFactor,
threshold = capacity * load factor,即扩容的阀值=容量*负载因子,
比如HashMap的容量为16,负载因子为0.75,则阀值为16*0.75=12,
当HashMap中放入12个元素时(size=12),就会进行扩容
1.负载因子越小,容易扩容,浪费空间,但查找效率高
2.负载因子越大,不易扩容,对空间的利用更加充分,查找效率低(链表拉长)
上述中的键值对是存放在一个静态的内部类中,即数组中存放的元素

构造函数只做2件事,初始化数组大小和负载因子,要么自己指定,有么用默认值,可能有人会说threshold是扩容阀值不是数组的长度啊,我们一会细说,(代码省去一部分校验内容)
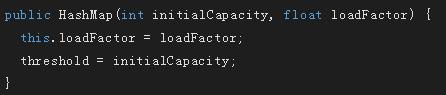
put操作
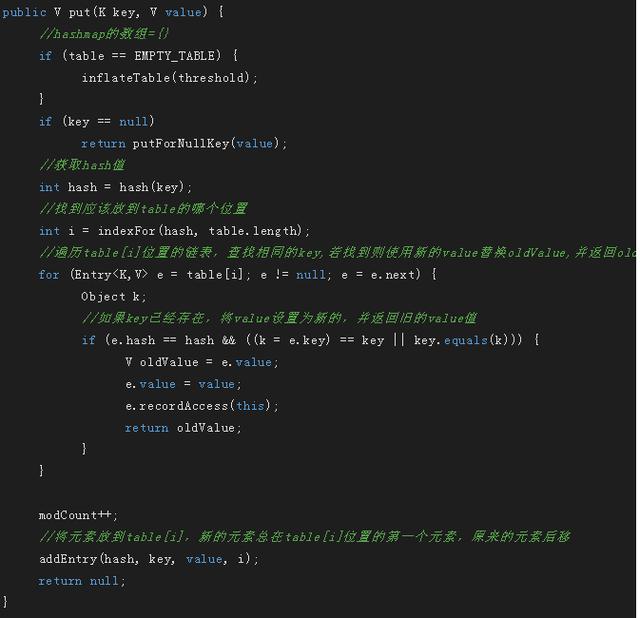
这里面试一般会问到为什么HashMap不能存放2个key相等的元素,因为放置key相等的元素时,新值会替换旧值,并且返回旧值
这里我们分析inflateTable,putForNullKey,addEntry方法,hash方法不进行分析,indexFor方法最后进行分析
传入的参数是构造函数初始化的threshold,将数组的长度变为>=size,并且是2的倍数的长度,这样即使初始化数组长度不是2的倍数,也会在第一次放值时变为2的倍数,并且对threshold重新设值
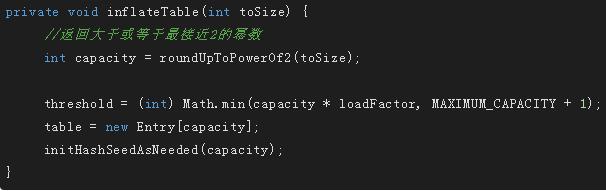
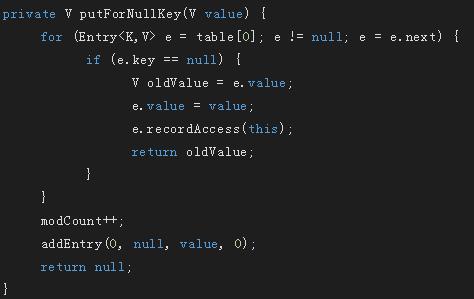
若key为null,则将值放在table[0]这个链上,这样key为null的时候直接从table[0]处取值即可
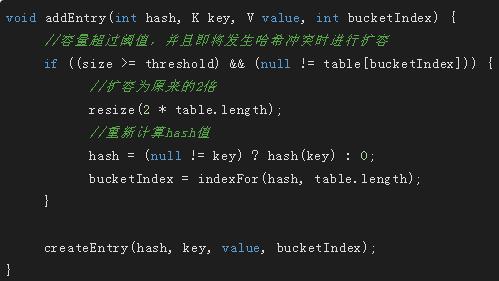
这里需要注意一下扩容的时机和扩容的大小,以后会和Hashtable,ConcurrentHashMap进行比较
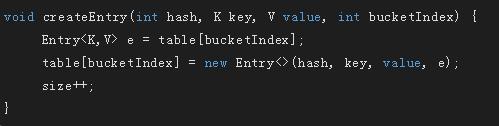
将新增加的元素放到链表的第一位,并且将其他元素跟在第一个元素后面,即头插法
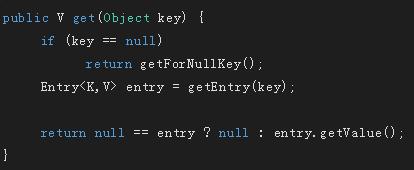
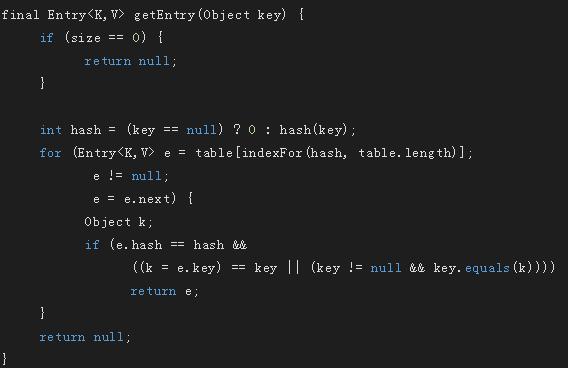
get方法
从table[0]初获取key为null的值

key不为null时
HashMap的大小为什么是2的倍数
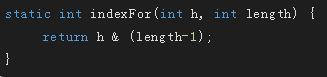
h是hashcode,length时数组长度,下面这个方法是根据hashcode求出对象在数组中放置的位置
h & (length - 1) 等价于 h % length,我们假设数组的长度为15和16,hashcide为8和9
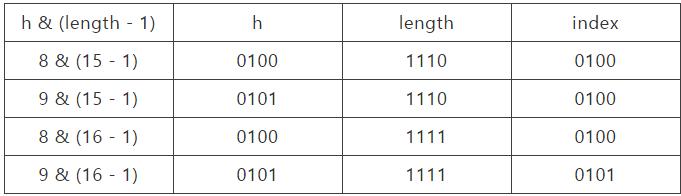
可以看出数组长度为15的时候,hash码为8和9的元素被放到数组中的同一个位置形成链表,键低了查询效率,当hahs码和15-1(1110)进行&时,最后一位永远是0,这样0001,0011,0101,1001,1011,0111,1101这些位置永远不会被放置元素,这样会导致1.空间浪费大,2.增加了碰撞的几率,减慢查询的效率。当数组长度为2的n次方时,2的n次方−1的所有位都是1,如8-1=7即111,那么进行低位&运算时,值总与原来的hash值相同,降低了碰撞的概率















 2549
2549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









