





数据增强是在有限数据集上进行人工扩张产生更多等价的数据。它能有效弥补现有训练数据的不足,防止模型出现过拟合现象,增强模型的泛化能力。
数据增强和其防止过拟合的方法的区别:
1. dropout,正则化等等方法限制了模型参数分布,用于减少过拟合。改变了模型结构或者模型空间,降低模型复杂度。
2. 数据增强没有降低网络的复杂度,也不增加计算复杂度和调参工程量,是隐式的规整化方法。实际应用中更有意义,数据才是核心。
1. 单样本
1.1 像素级变换
- 模糊 高斯模糊、平均模糊、中值模糊、GlassBluer(毛玻璃效果)、MotionBlur、ElasticTransformation(扭曲平滑)
- 均衡化 CLAHE、AHE、HE
- 颜色空间变换 ChannelDropout(随机选择通道像素失活,和Dropout层类似) CoarseDropout区域随机失活(擦除/高亮) ChannelShuffle(颜色空间随机交换)
- 噪声 高斯噪声 椒盐噪声 camera sensor noise FrequencyNoiseAlpha:在频域中用随机指数对噪声映射进行加权,再转换到空间域。在不同图像中,随着指数值逐渐增大,依次出现平滑的大斑点、多云模式、重复出现的小斑块
- 颜色干扰 对比度、饱和度、亮度
- 增强 FancyPCA(检测图像中的所有边缘,将它们标记为黑白图像,再将结果与原始图像叠加) EdgeDetect、浮雕、锐化、Superpixel、黑白转置、雾化、雨化、阴影、雪、太阳耀斑
1.2 空间级变换
crop Resize 旋转 Flip 仿射变换 弹性变换ElasticTransform Pad(常数、边界、反射) 网格畸变GridDistortion 光学畸变OpticalDistortion
2 多样本合成
2.1 mixup
2.1.1. 简介
论文:https://arxiv.org/abs/1710.09412
code: https://github.com/facebookresearch/mixup-cifar10
2.1.2. 原理
基于邻域风险最小化原则,使用线性插值的方法扩展数据.在图像领域用大白话讲大白话就是随即将两张图片按一定比例混合。
需要注意label的软化,平滑标签
2.2 CutMix
随机选择一部分区域并且填充训练集中的其他数据的区域像素值,分类标签按一定的比例进行平滑软化(smooth label)

2.3 Augmix(来源于DeepMInd)
2.3.1. mixup缺点:就是无法保证合成的图片的语义信息.
2.3.2. augmix简介
pape: https://arxiv.org/pdf/1912.02781v1.pdf
code:https://github.com/google-research/augmix
2.3.3. 原理
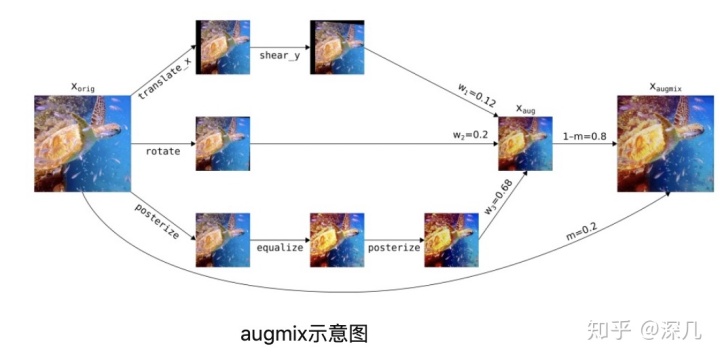
步骤:
1. 首先使用传统的增强方法如平移、旋转、均衡化等生成三张图
2. 融合。使用Dirichlet(1,1,1)分布随机抽取3个权值wi,根据Dirichlet分布的性质,权值和为1.之后按照权值wi将三条链按权相加得到
3. 作者还对loss做了改进,引入了Jensen-Shannon divergence(KL Loss改进版),详见论文
2.4 mosaic
2.4.1 简介
paper: YOLOV4
code: https://github.com/ultralytics/yolov3/blob/master/utils/datasets.py
2.4.2 原理
参考了CutMix数据增强方式。
步骤如下:
1. 从数据集中每次随机读取四张图片
2. 分别对四张图片进行翻转(对原始图片进行左右的翻转)、缩放(对原始图片进行大小的缩放)、色域变化(对原始图片的明亮度、饱和度、色调进行改变)等操作
3. 拼接。操作完成之后然后再将原始图片按照 第一张图片摆放在左上,第二张图片摆放在左下,第三张图片摆放在右下,第四张图片摆放在右上四个方向位置摆好
4、进行图片的组合和框的组合 完成四张图片的摆放之后,我们利用矩阵的方式将四张图片它固定的区域截取下来,然后将它们拼接起来,拼接成一 张新的图片,新的图片上含有框框等一系列的内容
3. 无监督数据增强
3.1 GAN生成样本
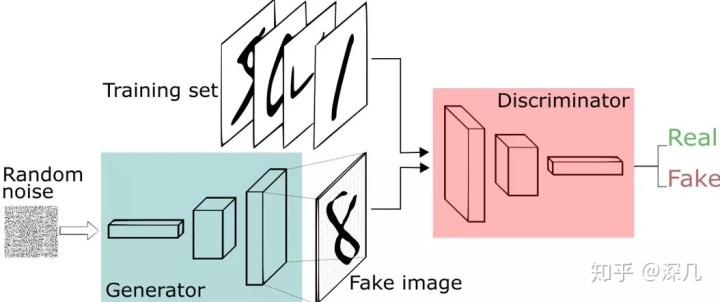
它包含两个网络,一个是生成网络,一个是对抗网络,基本原理如下:
1. G是一个生成图片的网络,它接收随机的噪声z,通过噪声生成图片,记做G(z) 。
2. D是一个判别网络,判别一张图片是不是“真实的”,即是真实的图片,还是由G生成的图片。
3.2 Autoaugmentation
3.2.1 原理
利用强化学习自动搜索最有效的数据增强策略 基本步骤:
1. 搜索空间总控包括16个传统数据增强操作
2. 一个策略(一个策略用于训练一个子模型)由5个子策略组成,每个子策略由两个按顺序执行的图像操作组成,每个操作还与两个超参数相关联:执行操作的概率和执行操作的幅度。
3. 对训练过程中mini-batch中的每个样本片,随机采用5个子策略操作中的一种来进行增强。 4. 在验证集上评估子模型精度 (
5.搜索结束时,将来自5个最佳策略的子策略合并为单个策略再进行最后的训练。
3.2.2 一些改进方法
Fast AutoAugment
PBA
RandAugment
Adversarial AutoAugment
基本上都是对AutoAugment的优化版本,有兴趣的可以展开阅读。
4 开源库
imgaug:https://github.com/aleju/imgaug
Albumentations:https://github.com/albumentations-team/albumentations
Augmentor:https://github.com/mdbloice/Augmentor















 1144
1144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









