






SparkSQL根据IP计算归属地(多版本性能测试)
一、数据集说明
- ip规则表,该规则表记录了在世界范围内的不同的IP段的分配情况,一般不同的公司会维护一份最新的规则表,层级可达到国家->省->市->县(区)等层级,可根据用户访问应用的IP地址确切地定位到该用户的地理位置信息,常用用于构建用户画像与基于用户的行为进行分析。本人是从某宝上花20元钱购得,不是最新的,但是作为大数据研究与学习来说足够。基本的构成如下:
-
- 第一列是记录的序号
- 第二列是IP的起始地址
- 第三列是IP的终止地址
- 第四列是IP的起始地址(十进制)
- 第五列是IP的终始地址(十进制)
- 第六列是国家省市等地区信息
- 第七列是IP的运营商
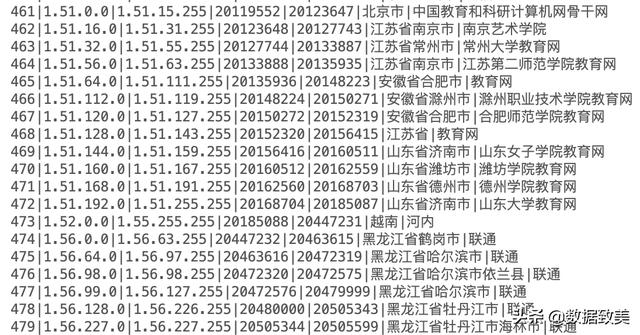
IP 规则表
- 访问日志
该数据集是用户访问应用或网站的数据,多由公司开发的应用进行数据埋点获取,然后通过数据采集工具采集、转换、清洗进行存储或由下游应用进行动态采集。这里我有程序生成,生成测试数据和代码主要如下:
- 第一列:访问用户的IP地址
- 第二列:访问日期
- 第三列:时间戳
- 第四列:用户ID或设备ID
- 第五列:访问的网址
- 第六列:用户的操作, 有register, login, logout, view, click等行为
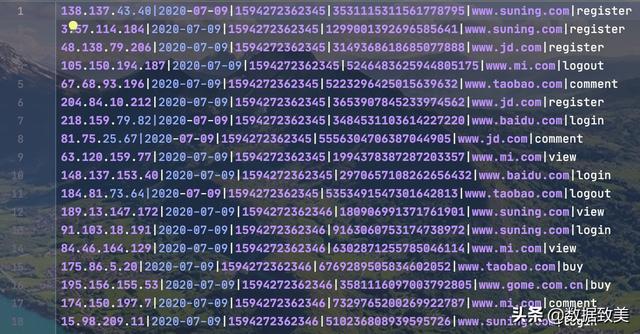
测试数据
import java.io.{File, FileOutputStream, OutputStreamWriter, PrintWriter}import java.text.SimpleDateFormatimport java.util.Dateimport scala.util.Randomobject MockPvAndUvData { //定义IP val IP = 223 //日期 val DATE: String = new SimpleDateFormat("yyyy-MM-dd").format(new Date()) //时间戳 val TIMESTAMP = 0L //用户ID val USER = 0L //网站 val WEBSITES: Array[String] = Array("www.baidu.com", "www.taobao.com", "www.dangdang.com", "www.jd.com", "www.suning.com", "www.mi.com", "www.gome.com.cn") //操作 val ACTIONS: Array[String] = Array("register", "comment", "view", "login", "buy", "click", "logout") def createFile(fileName: String): Boolean = {...省略 } def main(args: Array[String]): Unit = { val prefix = "website-access_" val suffix = ".log" val fileName: String = prefix + DATE + suffix val filePathName: String = "./dataset/pvuv/" + fileName //创建文件 val isFileCreated: Boolean = createFile(filePathName) //向文件中写入数据 val file = new File(filePathName) val fos = new FileOutputStream(file, true) val osw = new OutputStreamWriter(fos, "UTF-8") val pw = new PrintWriter(osw) if (isFileCreated) { var i = 0 //产生50000条数据 while (i < 50000) { val random = new Random() //随机生成一个IP val ip: String = random.nextInt(IP) + "." + random.nextInt(IP) + "." + random.nextInt(IP) + "." + random.nextInt(IP)// // 随机生成一个地址// val address: String = ADDRESS(random.nextInt(address.length)) //日期 val activityDate: String = DATE //模拟用户ID val userId: Long = Math.abs(random.nextLong()) /** * 这里模拟一个用户在不同的时间点访问不同的网址 */ var j = 0 var timestamp = 0L var website = "Unknown Website" var action = "Unknown Activity" val flag: Int = random.nextInt(5) | 1 if (j < flag) { //操作时间戳 timestamp = new Date().getTime //网址 website = WEBSITES(random.nextInt(WEBSITES.length)) //行为 action = ACTIONS(random.nextInt(ACTIONS.length)) j += 1 /** * 拼装 */ val content: String = ip + "|" + activityDate + "|" + timestamp + "|" + userId + "|" + website + "|" + action println(content) pw.write(content + "") } i += 1 } } //关闭文件流 pw.close() osw.close() fos.close() }二、数据处理与分析
1.利用SparkSQL中的sql的join方式
- 主要步骤
-
- 1.读取IP规则生成Dataset
- 2.整理IP规则数据,提取起始的ip,终止的ip和区域信息
- 3.IP规则生成DataFrame并注册临时视图
- 4.读取访问日志生成Dataset, 提取ip生成DataFrame, 并注册临时视图
- 5.利用访问日志视图join IP规则生成的视图,统计归属地信息, 即每个归属地有多少用户
- 代码实现
import com.dvtn.spark.utils.IpUtilsimport org.apache.spark.sql.{DataFrame, Dataset, SparkSession}object SparkSqlIpLocationAnalyse { def main(args: Array[String]): Unit = { //创建统一入口 val spark: SparkSession = SparkSession.builder() .master("local[4]") .appName(SparkSqlIpLocationAnalyse.getClass.getSimpleName) .getOrCreate() //设置log的级别 spark.sparkContext.setLogLevel("WARN") //需要导入隐式转换用于操作Dataset import spark.implicits._ //读取IP规则: ip_rule_db.txt val ipRuleDS: Dataset[String] = spark.read.textFile("./dataset/pvuv/ip_rule_db.txt") //整理IP规则数据 val ipRuleDataFrame: DataFrame = ipRuleDS.map(line => { val fields: Array[String] = line.split("[|]") val startNum: Long = fields(3).toLong val endNum: Long = fields(4).toLong val region: String = fields(5) (startNum, endNum, region) }).toDF("start_num", "end_num", "region") //读取访问日志:website-access_2020-07-09.log val logDs: Dataset[String] = spark.read.textFile("./dataset/pvuv/website-access_2020-07-09.log") //整理数据 val terminalIpsDataFrame: DataFrame = logDs.map(line => { val fields: Array[String] = line.split("[|]") val ip: String = fields(0) val ipNum: Long = IpUtils.ip2Long(ip) ipNum }).toDF("ip_num") /** * 以SparkSQL中sql的方式根据IP地址去规则中找到归属地 */ //首先根据DataFrame注册临时视图 ipRuleDataFrame.createOrReplaceTempView("v_rules") terminalIpsDataFrame.createOrReplaceTempView("v_terminal_ips") //构建查询语句 val sql = "SELECT r.region, count(*) cnt " + " FROM v_terminal_ips p join v_rules r " + " ON (p.ip_num >=r.start_num AND p.ip_num <=r.end_num) " + " GROUP BY r.region" + " SORT BY cnt DESC " val locationsDF: DataFrame = spark.sql(sql) locationsDF.show(10) spark.stop() }}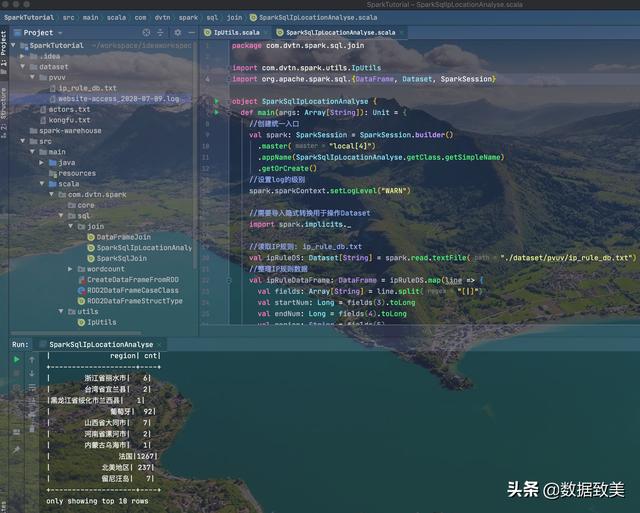
运行结果
- 存在的问题
1. 对于每一条访问用户的IP, 都要到规则表中进行关联查找,效率比较低2. 当数据量很大时,在本地上如果没有IP规则,会进行网络传输,倒致性能极具下降3. 对于规则表是45M, 访问日志的大小是4M, 运行时就要耗费5分钟以上,效率低,非常慢2.使用广播变量进行Map端的join
- 主要步骤
- 1.读取IP规则文件ip_rules_db.txt,将结果收集到Driver端进行广播
- 2.读取访问日志, 转换DataFrame, 并注册临时视图
- 3.在Driver端利用spark.udf.register()定义并注册自定义函数
- 4.编写查询,并用自定义的UDF函数传入IP返回区域region
- 5.输出或保存结果
- 代码实现(主要代码)
import com.dvtn.spark.utils.IpUtilsimport org.apache.spark.broadcast.Broadcastimport org.apache.spark.sql.{DataFrame, Dataset, SparkSession}object BroadcastIpLocationAnalyse { def main(args: Array[String]): Unit = { //创建统一入口 val spark: SparkSession = SparkSession.builder() .master("local[1]") .appName(SparkSqlIpLocationAnalyse.getClass.getSimpleName) .getOrCreate() //设置log的级别 spark.sparkContext.setLogLevel("WARN") //需要导入隐式转换用于操作Dataset import spark.implicits._ //读取IP规则: ip_rule_db.txt val ipRuleDS: Dataset[String] = spark.read.textFile("./dataset/pvuv/ip_rule_db.txt") //整理IP规则数据 val ruleDS: Dataset[(Long, Long, String)] = ipRuleDS.map(line => { val fields: Array[String] = line.split("[|]") val startNum: Long = fields(3).toLong val endNum: Long = fields(4).toLong val region: String = fields(5) (startNum, endNum, region) }) //收集规则到Driver端 val rulesInDriver: Array[(Long, Long, String)] = ruleDS.collect() //将规则广播出去 val broadcastRef: Broadcast[Array[(Long, Long, String)]] = spark.sparkContext.broadcast(rulesInDriver) //读取访问日志:website-access_2020-07-09.log val logDs: Dataset[String] = spark.read.textFile("./dataset/pvuv/website-access_2020-07-09.log") //整理数据 val terminalIpsDataFrame: DataFrame = logDs.map(line => { val fields: Array[String] = line.split("[|]") val ip: String = fields(0) val ipNum: Long = IpUtils.ip2Long(ip) ipNum }).toDF("ip_num") //将访问日志的IP注册临时视图 terminalIpsDataFrame.createOrReplaceTempView("v_terminal_ips") /** * 使用SQL方式 */ //自定义函数UDF并注册, 根据IP地址获取区域, 在Driver端定义 spark.udf.register("getRegionByIp", (ipNum: Long) =>{ //查找IP规则,事先已通过广播变量广播到Executor端了 //函数的逻辑代码是在Executor中执行的 //通过广播变量的引用就可以得到 val rulesInExecutor: Array[(Long, Long, String)] = broadcastRef.value //根据IP地址对应的十进制找到区域,通过二分法查找 val index: Int = IpUtils.binarySearch(rulesInExecutor, ipNum) var region = "未知" if(index != -1){ region = rulesInExecutor(index)._3 } region }) val locationDF: DataFrame = spark.sql("SELECT getRegionByIp(p.ip_num) region, COUNT(*) AS cnt FROM v_terminal_ips p GROUP BY region ORDER BY cnt DESC") locationDF.show(10) spark.stop() }}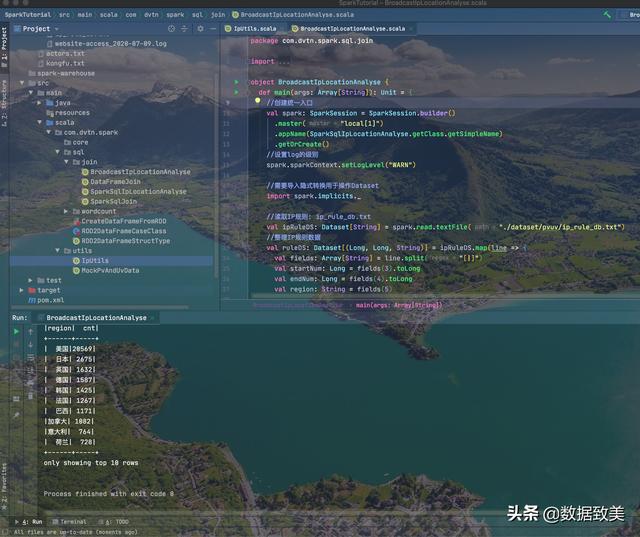
结果
- 结果分析
- 优化成使用广播变量的Map端join后,效率从原来的5分多钟到现在的不到1s, 性能得到了很大的提升。

下文将对SparkSQL中的三种join的原理剖析















 282
282











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









