









Hello,
这里是行上行下,我是张光耀~
本文最早发布在本人的GitHub上,后来在R语言中文社区的公共号上发布过。在之后对其内容进行过几次更新,这一版为最新版(2019年6月7日),修改了一些错误的地方,增添了新的内容。
R 中混合线性模型可依靠lme4或者lmerTest数据包(强烈推荐后者,因为会输出显著性)
library(lmerTest)
基本表达式
fit = lmer(data = , formula = DV ~ Fixed_Factor + (Random_intercept + Random_Slope | Random_Factor))
#data - 要处理的数据集;
#formula - 表达式;
#DV - 因变量;
#Fixed_Factor - 固定因子,即考察的自变量;
#Random_intercept - 随机截距,即认为不同群体的因变量的分布不同 (可以理解成有些人出生就在终点,而你是在起点......);
#Random_Slope - 随机斜率,即认为不同群体受固定因子的影响是不同的 (可以理解成别人花两个小时能赚10000元,而你只能挣个被试费......);
#Random_Factor - 随机因子;
数据整理形式
数据整理可参考data1:
data1 = readr::read_csv('https://raw.githubusercontent.com/usplos/Eye-movement-related/master/DemoData.csv')
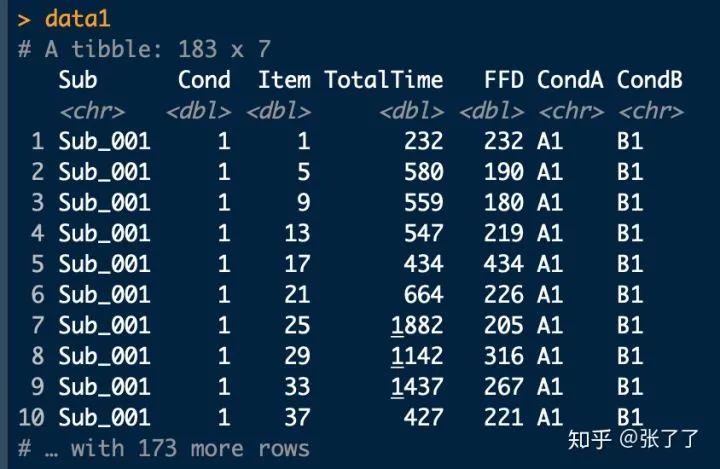
该数据收集了若干被试(Sub)在两种条件下(CondA,CondB)的首次注视时间(FFD)。这是一个典型的被试内设计(2 × 2设计)。
结果查看
以data1为例, 首先将CondA和CondB设置为因子变量,加载lmerTest数据包。
data1$CondA = factor(data1$CondA)
data1$CondB = factor(data1$CondB)
data1$Item = factor(data1$Item)
data1$Sub = factor(data1$Sub)
library(lmerTest)
建立模型,用summary()函数查看结果, 这里需要注意:
如果自变量是群体(个体)间的设计,就不能添加随机斜率,这里的两个条件是被试内的;
所以可以设置为随机斜率,而像年龄(每个被试只有一个确定的年龄)、性别(被试不可能既是男的又是女的)等变量不可以作为随机斜率;
如果设置随机效应,模型可能无法收敛或者自由度溢出(见 《随机斜率的取舍》部分),这个时候需要调整或者取消随机效应;
一般同时加Sub和Item的斜率,但是固定因子和因变量间的关系在不同项目间的差异是较小的,而在不同被试间的差异是比较大的;
所以在模型无法收敛时,可以采取优先舍掉Item上斜率的方法(有待讨论):
fit1 = lmer(data = data1, FFD ~ CondA * CondB + (1 + CondA*CondB | Sub) + (1|Item))
summary(fit1)
结果为:
Linear mixed model fit by REML. t-tests use Satterthwaite's method ['lmerModLmerTest']
Formula: FFD ~ CondA * CondB + (1 + CondA * CondB | Sub) + (1 | Item)
Data: data1
REML criterion at convergence: 2201.9
Scaled residuals:
Min 1Q Median 3Q Max
-1.9039 -0.6365 -0.2383 0.4440 3.3754
Random effects:
Groups Name Variance Std.Dev. Corr
Item (Intercept) 1622.5 40.28
Sub (Intercept) 1457.5 38.18
CondAA2 781.2 27.95 -1.00
CondBB2 644.5 25.39 -1.00 1.00
CondAA2:CondBB2 358.5 18.93 1.00 -1.00 -1.00
Residual 10237.5 101.18
Number of obs: 183, groups: Item, 64; Sub, 3
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 268.066 27.629 2.116 9.702 0.00867 **
CondAA2 17.743 27.270 2.787 0.651 0.56489
CondBB2 -2.847 26.495 3.524 -0.107 0.92026
CondAA2:CondBB2 1.259 32.534 8.143 0.039 0.97006
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Correlation of Fixed Effects:
(Intr) CndAA2 CndBB2
CondAA2 -0.808
CondBB2 -0.789 0.679
CndAA2:CBB2 0.549 -0.745 -0.750
convergence code: 0
Model failed to converge with max|grad| = 0.0116944 (tol = 0.002, component 1)
其中,随机效应的结果如下,可以看到确实每个被试的首次注视时间是有差别的;
但是这里看到相关系数为1或-1,说明模型过度拟合,这时需对模型进行简化(见 《随机斜率的取舍》部分):
Random effects:
Groups Name Variance Std.Dev. Corr
Item (Intercept) 1622.5 40.28
Sub (Intercept) 1457.5 38.18
CondAA2 781.2 27.95 -1.00
CondBB2 644.5 25.39 -1.00 1.00
CondAA2:CondBB2 358.5 18.93 1.00 -1.00 -1.00
Residual 10237.5 101.18
Number of obs: 183, groups: Item, 64; Sub, 3
固定效应的结果如下,这里是把A1 和 B1分别设为CondA和CondB的基线;
然后CondAA2这一行的意思是CondA在CondB的B1条件下的主效应,也就是简单主效应,同理CondBB2也是在CondA的A1条件下的简单主效应。
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 268.066 27.629 2.116 9.702 0.00867 **
CondAA2 17.743 27.270 2.787 0.651 0.56489
CondBB2 -2.847 26.495 3.524 -0.107 0.92026
CondAA2:CondBB2 1.259 32.534 8.143 0.039 0.97006
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
注意,固定效应不是主效应和交互作用,要查看主效应和交互作用需要用anova()函数:
anova(fit1)
结果如下,看出主效应和交互作用都不显著。
Type III Analysis of Variance Table with Satterthwaite's method
Sum Sq Mean Sq NumDF DenDF F value Pr(>F)
CondA 9941.7 9941.7 1 2.7714 0.9711
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1116
1116











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









