






机器学习:
1.回归问题:线性回归、多项式回归
2.分类问题:逻辑回归(二分分类)、softmax回归(多分类)
3.聚类问题:K-means
4.降维问题
一、
1.Seaborn是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,在大多数情况下使用seaborn能做出很具有吸引力的图,而使用matplotlib就能制作具有更多特色的图。应该把Seaborn视为matplotlib的补充,而不是替代物。同时它能高度兼容numpy与pandas数据结构以及scipy与statsmodels等统计模式。
2.scikit-learn已经成为Python重要的机器学习库了,scikit-learn简称sklearn,支持包括分类,回归,降维和聚类四大机器学习算法。还包括了特征提取,数据处理和模型评估者三大模块
3.plt.scatter 散点图
4.
rc.fit 拟合
rc.coef_ 查看W
rc.intercept_ 查看W0
5.numpy.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
在指定的间隔范围内返回均匀间隔的数字。
一句话解释numpy.meshgrid()——生成网格点坐标矩阵。
6.predict_proba返回的是一个 n 行 k 列的数组,第 i 行 第 j 列上的数值是模型预测 第 i 个预测样本为某个标签的概率,并且每一行的概率和为1。
7.np.r_是按列连接两个矩阵,就是把两矩阵上下相加,要求列数相等。
np.c_是按行连接两个矩阵,就是把两矩阵左右相加,要求行数相等。
8.numpy中的ravel()、flatten()、squeeze()都有将多维数组转换为一维数组的功能,区别:
ravel():如果没有必要,不会产生源数据的副本
flatten():返回源数据的副本
squeeze():只能对维数为1的维度降维
9.contour绘制等高线
10.plt.annotate()函数用于标注文字
11.pairplot:pair是成对的意思,即是说这个用来展现变量两两之间的关系,线性、非线性、相关等等
12.loc函数:通过行索引 "Index" 中的具体值来取行数据(如取"Index"为"A"的行)
iloc函数:通过行号来取行数据(如取第二行的数据)
13.randon_state:控制随机状态
固定random_state后,每次构建的模型是相同的、生成的数据集是相同的、每次的拆分结果也是相同的。
14.牛顿法求根
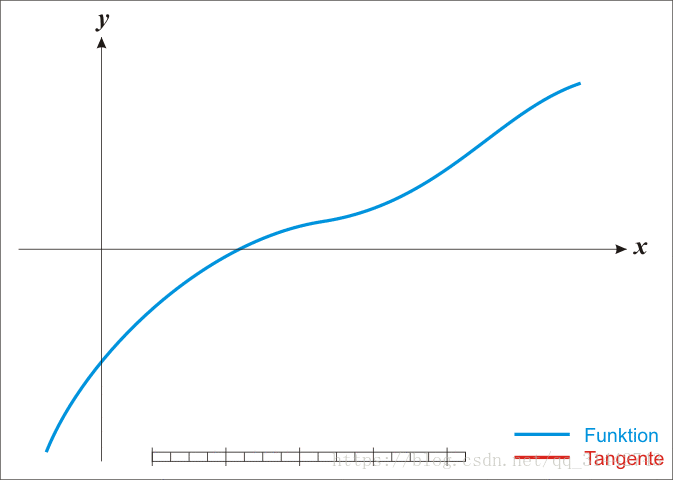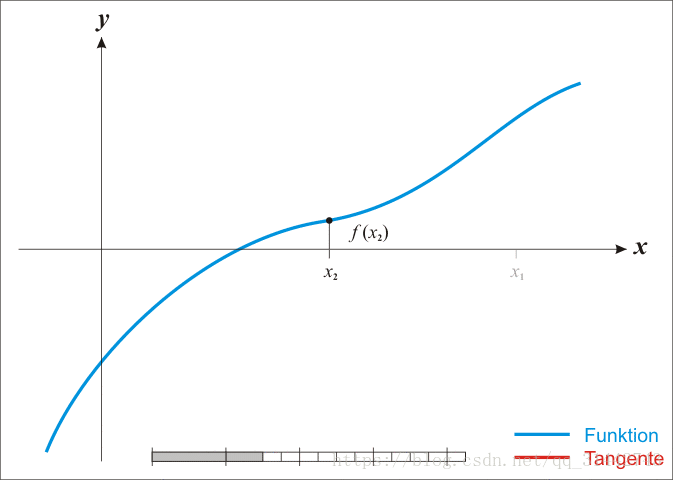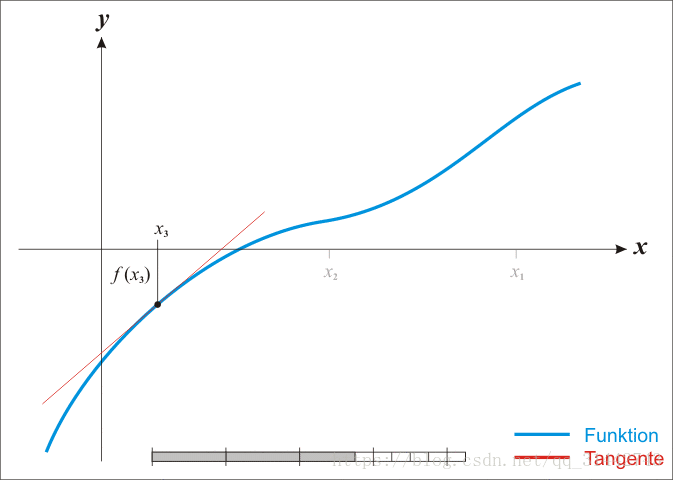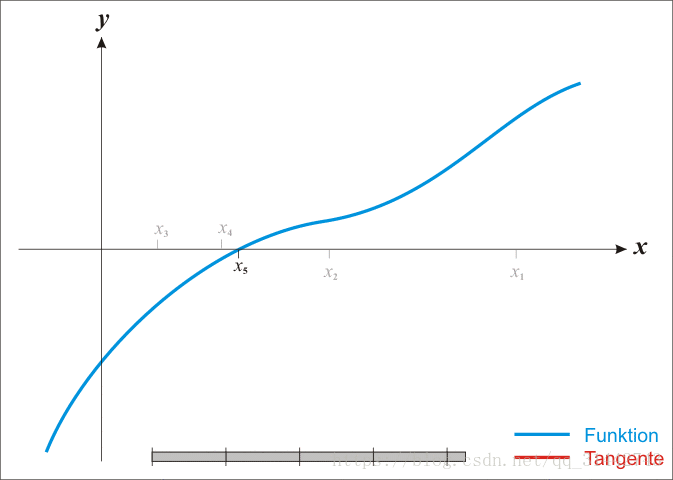
15.LBFGS算法
16.
sklearn - metrics 模型评价指标
17.混淆矩阵
混淆矩阵也称误差矩阵,是表示精度评价的一种标准格式,用n行n列的矩阵形式来表示。















 9388
9388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









