





今天我们来进行一个python机器学习项目的实战,我们后面都会使用这样的模式,先实战,后进行详细的讲解,话不多说,开工。原创不易,麻烦大家给个关注。
项目需求
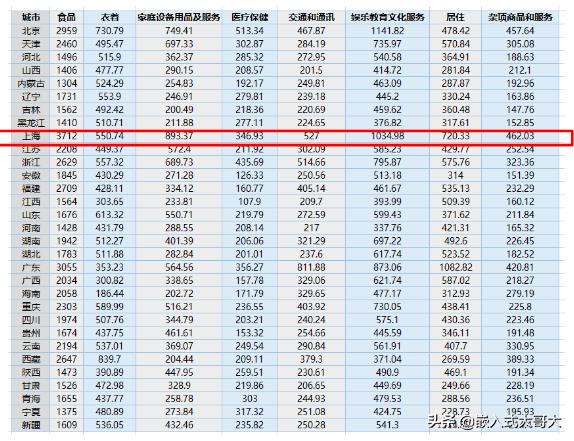
通过机器学习算法来对1999年各省份的消费水平进行分类,主要参数为食品、交通、医疗、住房、娱乐、杂项等八个变量,用以了解各省的经济实力。
基本思路
这个需求是一个很典型的聚类算法应用,我们使用K-means算法来实现这个项目,技术路线python + sklearn。
KMeans算法
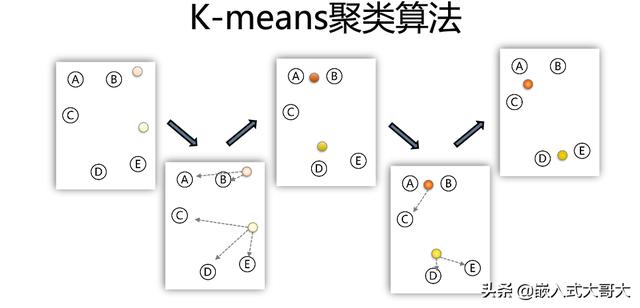
KMeans算法输入参数K即我们想要把n个对象分为K类,我们称之为簇,过程如下
1、随机选择K个点作为聚类中心。
2、分别计算剩下的点与K个点的距离,选择距离最小的中心点归为一簇。
3、计算每个簇中所有点的均值作为新的簇中心。
4、循环计算,直到簇中心不再有大的变化。
实现过程
1、导入numpy
import numpy as np2、导入sklearn库的KMeans包,这个库是用于机器学习的常用库,下期我们重点讲解。
from sklearn.cluster import KMeans3、加载训练数据,这里我们单独写一个函数来加载数据
def loadData(filePath):
fr = open(filePath,'r+')#打开文件
lines = fr.readlines()#读取文件
retData=[]
retCityName = []
for line in lines:
print(line)
items = line.strip().split(















 601
601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









