





永远在你身后:自己动手写深度神经网络框架(八)
上面的链接是卷积网络的基本介绍,本篇主要讨论卷积层的反向传播过程(backward)中损失对于卷积核的梯度计算
因为正向传播(forward)时可能有多个样本(输入),并且每个样本也可能不止一个通道,卷积核也可能有多个,所以backward传进来的上一层的梯度也可能是批量,多通道的
首先从单个样本,单通道单栗子来入手,比如forward如下图所示:
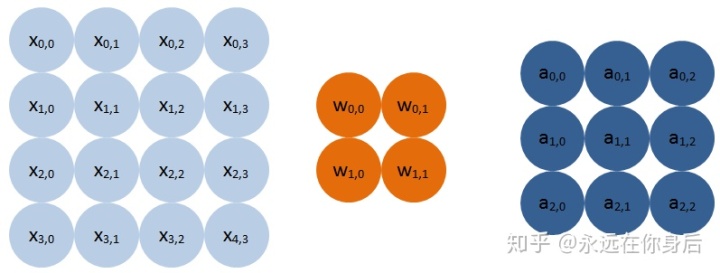
上图中X是卷积的输入(样本)大小为4x4,卷积核大小是2x2,卷积结果(输出)大小为3x3,关于卷积的实现可以参考这一篇文章:im2col方法实现卷积算法
在反向传播过程中,求损失对于参数的梯度,根据链式法则:
其中
现在需要做的只是求
先求单个输出对任意一个参数(这里表示为
从前面的公式中可以看到,对于任一参数而言,每一个输出都有它参与计算,所以,整个输出(A)对于该参数的梯度(
就拿

关于偏置(b)的梯度,因为
且偏置只有一个(偏置个数与卷积核相同):
初步用python实现如下:
def backward(self, eta):
# eta.shape: (oh, ow) # eta是损失对于卷积输出的梯度,由前一层的backward负责计算
# self.x.shape: (H, W) # self.x 是保存forward的输入
# self.W.shape: (kh, k) # self.W 就是卷积核
oh, ow = eta.shape
kh, kw = self.W.shape
gradb = eta.sum()
gradW = np.zeros(self.W.shape)
for h in range(kh):
for w in range(kw):
gradW[h,w] = np.tensordot(eta, self.x[h:h+oh, w:w+ow], ([0,1], [0,1]))上面的代码使用的是tensendot,numpy库自带的张量乘法函数,可以参考:卷积算法另一种高效实现,as_strided详解,最后面有该函数的讲解
下面讨论当输入是多通道的情况(卷积核自然也要变成多通道),如下图:
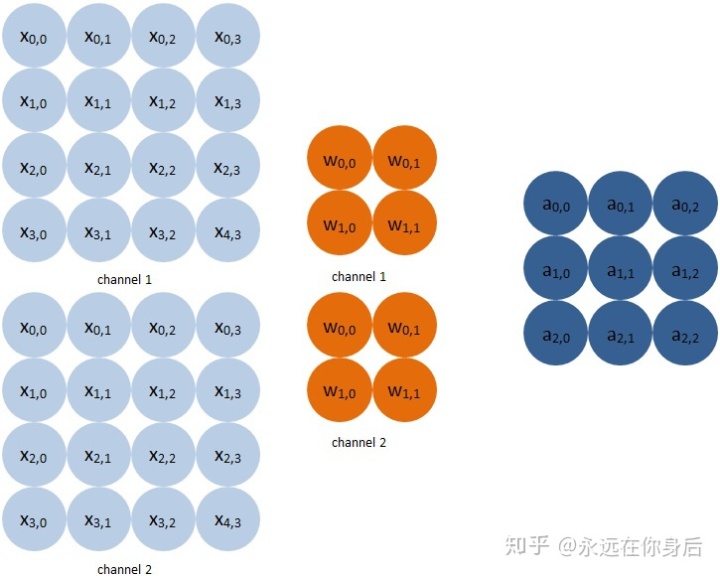
前向计算公式:
然后是求梯度,注意上面的公式中,卷积的输入和卷积核都多出了一个通道下标:
实现起来也和上面差不多:
def backward(self, eta):
# eta.shape: (oh, ow)
# self.x.shape: (H, W, c)
# self.W.shape: (kh, kw, c)
oh, ow = eta.shape
kh, kw = self.W.shape[:-1]
gradb = eta.sum()
gradW = np.zeros(self.W.shape)
for h in range(kh):
for w in range(kw):
gradW[h,w,:] = np.tensordot(eta, self.x[h:h+oh, w:w+ow, :], ([0,1], [0,1]))接下来,进一步升级,来考虑卷积核有多个的情况,公式为:
此时卷积核是一个四维的,而卷积的输入与输出都是三维:
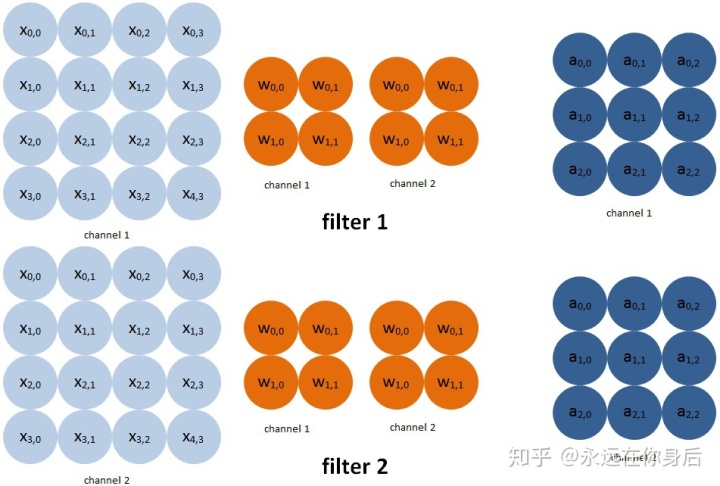
如图所示,每多一个卷积核,输出就多一个通道,它们之间的关系在前面链接的卷积算法的文章中已经讨论过了,现在来计算梯度:
需要注意的是,因为一个卷积核只与一个输出的通道有关,举个栗子,第一个核与输入卷积的结果就是输出的第一个通道,第二个核与输入卷积的结果就是输出的第二个通道,以此类推
所以每个卷积核只与它相关的通道计算梯度:
还有一个是偏置(b)的变化,因为一个卷积核有一个偏置,现在多卷积核自然有多个偏置了,所以公式稍微改一下:
然后是实现的代码:
def backward(self, eta):
# eta.shape: (oh, ow, d)
# self.x.shape: (H, W, c)
# self.W.shape: (d, kh, kw, c)
oh, ow = eta.shape[:-1]
kh, kw = self.W.shape[:-1]
gradb = eta.sum(axis=(0,1))
gradW = np.zeros(self.W.shape)
for h in range(kh):
for w in range(kw):
gradW[:, h, w, :] = np.tensordot(eta, self.x[h:h+oh, w:w+ow, :], ([0,1], [0,1]))至此,多卷积核多通道输入的卷积层求梯度也就解决了,但是以上都是单个样本的情况,还需要解决同时训练多个样本的问题,还是一样,先把公式亮出来:
还是一样,先求单个卷积结果对任一参数的偏导:
在进行接来下的推导之前,先捋顺各个卷积核与输出之间的关系;对于一个输出,它包含若干个通道,数量和卷积核的数量一致,每一个卷积核都只参与了一个通道的计算
但是,当有N个样本的时候,其实就是把一个样本计算过程重复N便罢了,所以,每一个卷积核都会参与所有样本的计算
所以,计算梯度时要把所有的样本的损失梯度累加起来
最后是实现:
def backward(self, eta):
# eta.shape: (n, oh, ow, d)
# self.x.shape: (n, H, W, c)
# self.W.shape: (d, kh, kw, c)
oh, ow = eta.shape[1:-1]
kh, kw = self.W.shape[1:-1]
gradb = eta.sum(axis=(0,1,2))
gradW = np.zeros(self.W.shape)
for h in range(kh):
for w in range(kw):
gradW[:,h,w,:] = np.tensordot(eta, self.x[:,h:h+oh, w:w+ow, :], ([0,1,2], [0,1,2]))以上,就是最终的实现了















 234
234











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









