







引言:
社交媒体及其与心理健康相关的论坛已经成为计算语言学的一个新兴研究领域。它为开发新的技术方法和改进提供了一个有价值的研究平台,可以为自杀检测和进一步预防自杀风险带来新颖性[8]。它可以作为一个很好的干预点。Kumar等[9]研究了关注名人自杀新闻的Reddit SuicideWatch用户的发帖活动。他介绍了一种可以有效防止高调自杀的方法。Choudhury等人[7]研究了Reddit社交媒体中从心理健康话语到自杀意念的转变。他开发了一种基于倾向得分匹配的统计方法来得出这种转变的独特标志。最近,Ji等人[10]开发了一种新的数据保护方案和高级优化策略(AvgDiffLDP),用于自杀意念的早期检测。
除了传统的文本分类方法,深度学习方法已经在计算机视觉和模式识别领域取得了令人印象深刻的进步。传统的机器学习方法严重依赖耗时且往往不完整的手工特征,而基于密集向量表示的神经网络可以在各种自然语言处理(NLP)任务上产生优异的结果[11]。词嵌入[12,13]和深度神经网络的日益成功反映在自杀风险评估方面优于更传统的机器学习系统。
我们研究的主要目的是从数据分析的角度,利用有效的深度学习架构,在Reddit社交媒体论坛上分享自杀意念的知识。我们的主要任务是探索长短期记忆(LSTM)、卷积神经网络(CNN)及其组合模型在自杀意念斗争多分类任务中的应用潜力。我们试图测试将CNN和LSTM分类器实现到一个模型中是否可以提高语言建模和文本分类性能。我们将尝试证明LSTM-CNN模型在自杀相关主题方面的表现优于其单独的CNN和LSTM分类器以及更传统的机器学习系统。潜在地,它可以嵌入任何在线论坛和博客的数据集。在我们的实验中,我们首先选择数据源,定义我们提出的模型,并分析基线特征。然后,我们计算数据集中n-gram的频率,例如unigrams和biggram,以检测自杀想法的存在。我们基于基线和我们提出的模型来评估实验方法。最后,我们使用10倍交叉验证来训练LSTM-CNN模型,以确定自杀意念检测的最佳超参数选择。对于我们的数据集,我们应用从Reddit社交媒体收集的数据,允许其用户创建更长的帖子。
我们的研究有具体的三方面贡献:•N-gram分析:我们评估N-gram分析,以表明自杀倾向的表达和减少的社会参与经常在自杀相关论坛上讨论。我们将向社会观念的过渡与不同的心理阶段相关联,如高度的自我关注,绝望、沮丧、焦虑或孤独的表现。•经典特征分析:使用CNN、LSTM和LSTM-CNN组合模型分析,我们评估了词包、TF-IDF和统计特征在词嵌入上的性能。•比较评价:我们探索了LSTM-CNN组合类深度神经网络作为我们提出的自杀意念任务检测模型的性能,以改进最先进的方法。在评估指标方面,我们比较了它的强度和潜力
相关工作:
近年来,有相当多的实验都在强调社交媒体对自杀意念的影响。Choudhury等人[7]开发了一种基于分数匹配模型的统计方法,以获得一些不同的标记,检测从心理健康话语到自杀意念的转变。根据作者的说法,这种转变可以伴随着三个特定的心理阶段:思考、矛盾和决策。第一阶段包括焦虑、绝望和痛苦的想法。第二阶段与自尊心降低和社会凝聚力降低有关。第三阶段伴随着攻击性和自杀承诺计划。类似地,Coppersmith等人[14]研究了在自杀企图前几周内,发现有悲伤情绪的推文显著增加的用户的行为转变。
此外,在自杀未遂后的几周内,发现带有愤怒情绪的推文显著增加。一些研究主张社交网络相互连接对用户自杀意念的影响。Hsiung[15]观察了社交媒体群内发生的一起自杀事件后用户的行为变化。Jashinsky等[16]强调了推文中自杀死亡率与危险因素发生的地理相关性。Colombo等[17]根据用户在社交网络互动中的行为,对包含自杀意念的推文进行了研究,导致了高度的相互连接,加强了用户之间的联系。
另一个有趣的观察是名人自杀对网络社区成员自杀意念发展的影响。Kumar等人[9]研究了Reddit用户的自杀兴趣属性与模仿者或维特效应的关系[18]。他的研究表明,在名人自杀的报道之后,用户的发帖频率显著增加,他们的语言行为也发生了变化。人们观察到这种转变的方向是更消极、更关注自我、社会融合程度更低的职位。同样,Ueda等人[19]对2010年至2014年日本26位知名人士自杀后的100万条Twitter帖子进行了深入研究。
识别社交媒体文本中的常规语言模式可以更有效地识别自杀倾向。它通常通过在不同的NLP技术上应用各种机器学习方法来支持。Desmet等[20]利用二值支持向量机(SVM)分类器构建了一种检测自杀意念的遗书分析方法。Huang等人[21]基于中文情感词典(知网)创建了一个心理词典。他应用支持向量机方法识别分类,用于开发部署在中文微博上的实时自杀意念检测系统。Braithwaite等人[22]证明,机器学习算法在区分有和没有自杀风险的人方面是有效的。Sueki等人[23]研究了日本20多岁Twitter用户的自杀意图,他指出语言框架对于识别文本中的自杀标记很重要。例如,“想自杀”的表达比“想死”的表达更常与一生的自杀意图联系在一起。O ' Dea等人[24]证明,使用TF-IDF特征上的人类代码和自动机器学习分类器(LR、SVM),可以区分与自杀相关的算法和19个帖子中的关注程度。Wood等人[25]确定了125名Twitter用户,并在他们试图自杀之前追踪他们的推文。使用简单的线性分类器,他们发现70%的用户有自杀企图,并以91.9%的准确率确定了他们的性别。Okhapkina等人[26]研究了信息检索方法在识别社会网络中破坏性信息影响方面的适应性。他编了一本关于自杀内容的词典。他介绍了TF-IDF矩阵及其奇异向量分解。Sawhney等人[27]改进了随机森林(Random Forest, RF)分类器识别推文中自杀意念的性能。Aladag等人[28]使用的逻辑回归分类算法在检测自杀内容方面显示出良好的效果,准确率为80-92%。
随着神经网络模型在自然语言处理中的最新进展,在自杀意念检测方面的新贡献已经从更复杂的深度学习架构的实现中出现,以超越更传统的机器学习系统。递归神经网络(RNN)被很好地设计用于序列建模[29]。其中,长短期记忆(LSTM)被认为是一种有效的记忆模型,能够将有用的信息从长期依赖中分离出来。Sawhney等人[30]的工作揭示了与其他深度学习和机器学习分类器相比,基于c - lstm的模型在自杀意念识别方面的优势和能力。Ji等[31]将LSTM分类器与其他五种机器学习模型进行了比较,证明了方法的可行性和实用性。他的研究为Reddit和Twitter上的自杀意念检测提供了一个主要基准。
近年来,具有卷积层、非线性层和池化层的CNN神经网络已成功应用于广泛的NLP任务,并被证明比传统的NLP方法获得更好的性能[29]。然而,它强调局部n-gram特征,并阻止捕获远程交互。Kalchbrenner等[32]主张CNN在不同句子位置的n-gram特征上的强度。Yin和Schutze[33]引入了多通道词嵌入和无监督预训练模型来提高分类精度。Gehrmann等人[34]使用带有n-gram特征的ctake和LR方法将CNN模型与更传统的基于规则的实体提取系统进行比较。他的研究结果表明,CNN在预测10种表型方面优于其他酚分型算法。Morales等人[35]展示了CNN和LSTM模型在自杀风险评估中的优势,提出了一种全新的人格和语调特征测试结果。Bhat等人[36]和[37]强调了CNN在识别青少年自杀倾向方面优于其他方法的表现。Du等人[38]应用深度学习方法检测社交媒体中自杀识别的精神压力源。利用CNN网络,他建立了一个二元分类器来区分自杀推文和非自杀推文。最近的其他研究[39]揭示了CNN在SuicideWatch论坛上实施的积极结果,该论坛作为我们研究论文的数据集。
从根本上说,将单个循环和卷积神经网络作为向量来编码整个序列往往不足以捕获所有重要的信息序列[40,41]。因此,已经有几个实验来开发一个混合框架,用于cnn和rnn的相干组合,以应用两者的优点。例如,He等人[42]引入了一种基于ConvNet和bi - lstm混合的新型神经网络模型来解决语义文本相似度的测量问题。Matsumoto等人[43]提出了一种高效的混合模型,将快速深度模型与初始信息检索模型相结合,有效高效地处理AS。在我们的研究中,我们提出了一个基于LSTM和CNN组合模型集成的框架来识别社交媒体中的自杀意念。
数据集:
为了检测自杀意念,我们在Reddit社交媒体数据集上训练我们的分类模型,其中用户可以通过文本帖子、链接或投票机制帖子表达他们的观点。它们通过附在每个帖子上的评论线程相互参与算法2020、13、75和19[9]。我们实验中使用的数据集是由Ji等人[31]建立的,包括自杀指示性和非自杀帖子的列表。为了保护用户的隐私,他们的个人信息被替换为唯一的ID。由于用户倾向于参与不同类型的subreddits,因此每个分组由来自不同主题的相应随机数量的消息组成。我们的数据集是由3549个自杀指示帖子和3652个非自杀帖子创建的,这些帖子来自于相对较大的致力于支持潜在风险个体的子reddit。
方法:
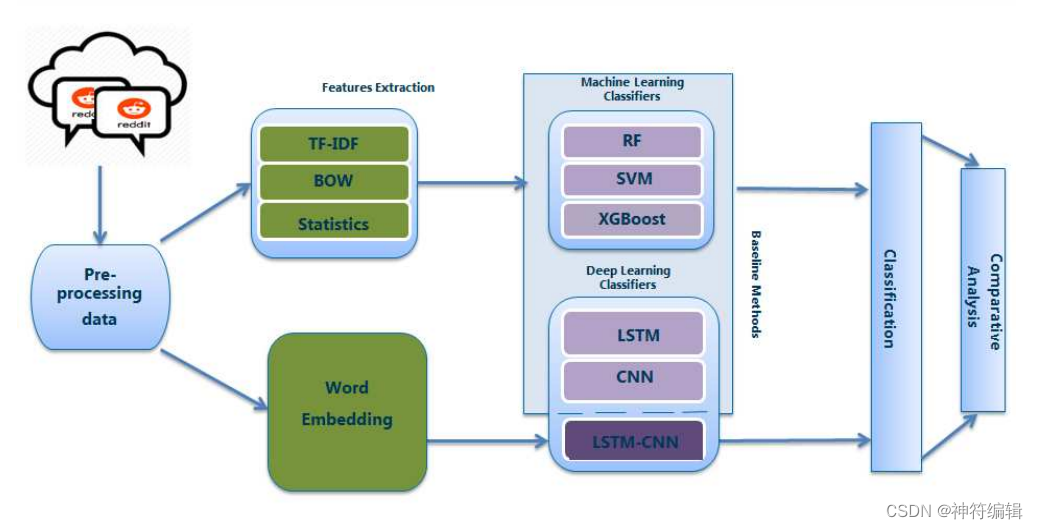
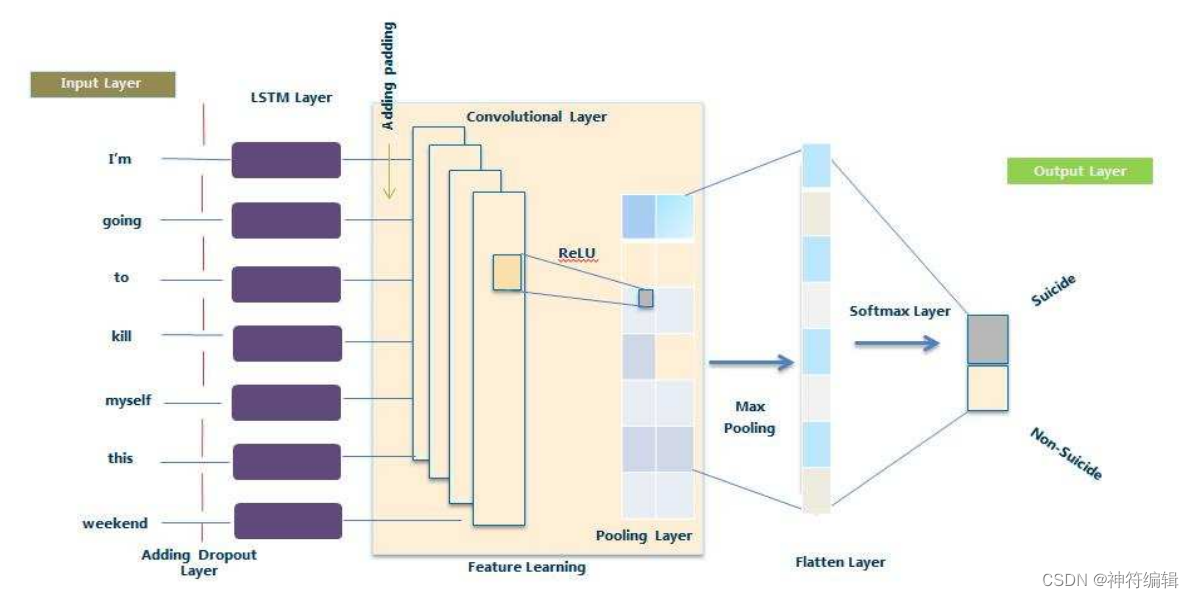
本研究的目的是实现一个组合的深度学习分类器,以提高语言建模和文本分类的性能,用于检测Reddit社交媒体中的自杀意念。在我们的实验中,我们结合了使用各种NLP和文本来分类技术的方法的技术描述。图1显示了我们提议的框架的总体概述。它包括两个方向的文本数据挖掘方法。第一个包括数据预处理,使用NLP技术(TF-IDF, BOW和统计特征)进行特征提取,用于编码单词,然后由传统机器学习系统进一步进行基线方法。第二个框架是通过数据预处理,使用词嵌入提取特征,然后是深度学习分类器创建的,一个用于基线方法,一个用于提议的模型。
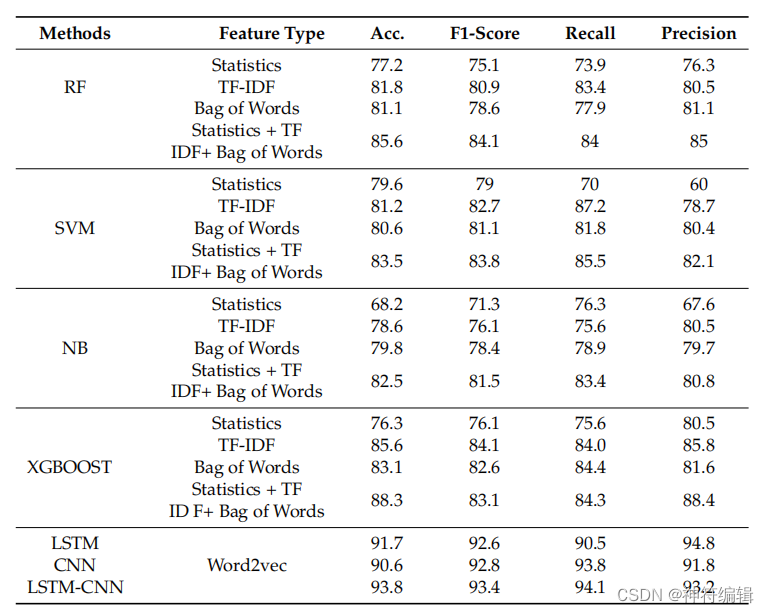
实验结果:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









