






一,项目背景和分析目的
近几年淘宝的发展,或者说电商行业的发展是“爆炸”式的。大量用户每天穿梭于各个淘宝店铺,有些是有明确的购买目的,有些只是随便逛逛看看有没有喜欢的商品。对于商家而言,利用网站可以统计到用户访问、收藏、加购物车和购买等一系列行为数据。
本文是用Mysql对淘宝用户行为数据进行整理分析,目的是分析这些行为数据背后隐藏的信息和规律,给网站或者店铺用户运营提供数据参考。
二,搜集数据
1,数据来源:数集可以在网站直接下载
User Behavior Data from Taobao for Recommendation-数据集-阿里云天池tianchi.aliyun.com
2,理解数据:
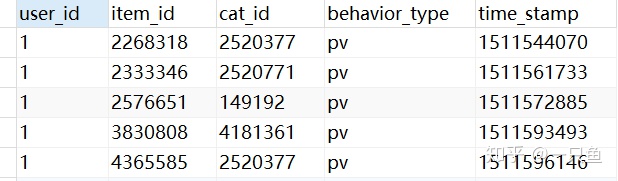
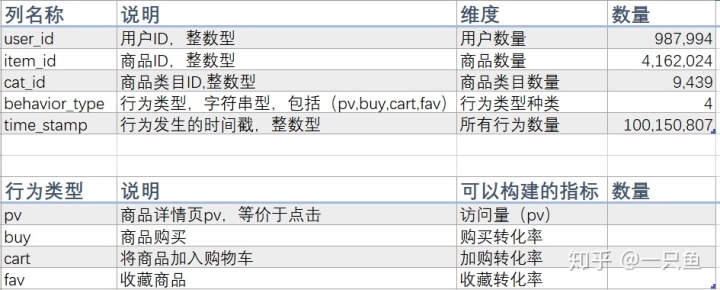
UserBehavior.csv该数集由阿里妈妈提供,包含了2017年11月25日至2017年12月3日之间,有行为的约一百万随机用户在淘宝网的所有行为数据(行为包括点击、购买、加购、收藏)。数集总共有5列,一亿多行,用Excel无法打开,因此选择导入Mysql进行分析。对于各字段的理解和数据大小描述如下:
三,提出问题
1,分析网站每日流量数据
- 用到的指标:日访问次数pv,日访问人数uv,日购买次数,日购买人数
- 通过监控每日流量指标,衡量网站总体运营情况。
2,分析一天不同时间段用户活跃规律
- 用到的指标:每小时访问次数,每小时访问人数,每小时人均访问次数,
- 了解不同时间段用户在网站的活跃规律,可以指导网站和商家把握营销节点。
3,基于AARRR模型分析用户购买行为路径
AARRR漏斗模型:
1,获取用户(Acquisition)。一般指日新增用户数。这里统计点击次数
2,激活用户(Activation)。一般指活跃用户数AU。这里统计收藏和加购物车的次数
3,提高留存(Retention)。一般指N日留存用户数。由于时间跨度太短本篇不做分析
4,增加收入(Revenue)。一般指付费用户数。这里统计用户购买次数
5,推荐(Refer)。一般指转发率。本数集无相关数据
- 用到的指标:收藏或加购物车转化率,购买转化率
- 收藏或加购物车转化率衡量用户购买意向,购买转化率衡量店铺流量最终转化质量。
4,基于RFM模型对用户价值进行分类
RFM用户价值分析模型:
R:最近一次消费时间间隔(Recency)。数据集提供了17年11月25号到12月3号的用户购买行为,统计有复购行为的用户最近2次的购买时间间隔,并设置R值打分
F:消费频率(Frequeny)。统计9天时间用户的购买次数,并设置F值打分
M:消费金额(Monetary)。数据集没有该项数据
- 用到的指标:消费间隔时间(类似于复购率),消费频次(类似于人均购买次数),
- R值衡量用户对产品的记忆强度,F值衡量用户对产品的忠诚度,M值衡量用户消费能力。RFM模型是用来衡量客户当前价值和潜在价值的重要工具,通过对客户价值分层,制定差异化营销方案
四,数据清洗
1,导入数据、选择子集、列名重命名
原始数据有1亿多行,考虑到操作效率,这里用数据库管理工具Navicat将原始数据前500万行分批导入Mysql。每100万行数据导入用时1分钟左右。
原始数据5个字段都有用,导入数据时不用选择子集。
原始数据没有列名,在导入数据之后用Navicat设计表功能对列名进行修改。
2,删除重复值、处理缺失值
对数据集重复数据的理解是同一用户在同一时间对同一商品的行为,因此删除重复行的方法1是在navicat设计表功能将user_id ,cat_id , time_stamp这3列设为联合主键,方法2是用Mysql语句查询重复行,并创建没有重复行的表格。这里选择第二种方法。
-- 1,查找重复值
SELECT *
FROM user_behavior
WHERE (user_id,item_id,time_stamp) in (
SELECT user_id,item_id,Time_stamp
FROM user_behavior
GROUP BY user_id,item_id,time_stamp
HAVING count(*)>1);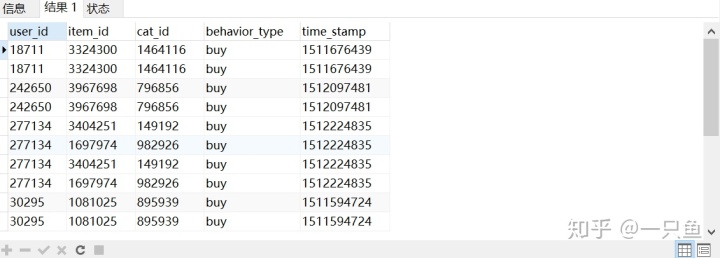
结果显示有10条数据出现重复,创建没有重复值的表格u1,并查看各字段数量。
-- 2,创建没有重复值表格
CREATE TABLE u1
SELECT *
FROM user_behavior
GROUP BY user_id,item_id,time_stamp;
-- 3,查看各字段数量
SELECT count(user_id),count(item_id),count(cat_id),count(behavior_type),count(time_stamp)
FROM u1;
结果显示各字段都是4999995条,没有缺失值。
3,数据类型转换
导入数据时默认各字段都是varchar类型(可变长度字符串),时间戳(time_stamp)这一列需要转换为普通时间格式,并截取日期(dates)和小时(hours)供后面分析不同时段购买规律。
由于有500万条左右数据,一次性更新时间戳列数据会导致Mysql系统奔溃,只能采用分批更新。分批的方法是设置表的属性值自动增加,用navicat设计表功能添加自动增长的ID列,后面通过选择ID序列号分批更新字段。
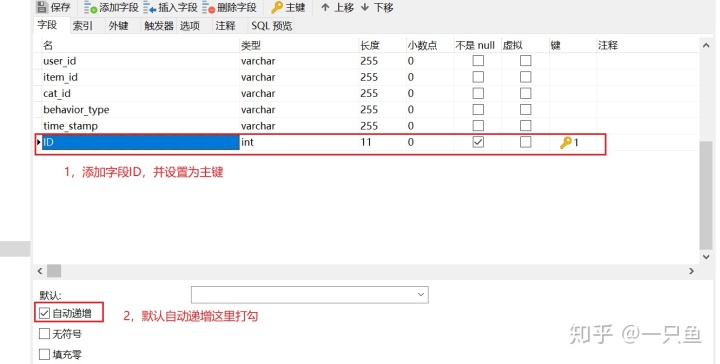
首先用from_unixtime()函数将time_stamp列转换为普通格式时间,再创建dates和hours列,最后用字符串截取函数left()和mid()分别截取对应time_stamp列的日期和小时。
-- 4,用from_unixtime()函数将unix时间戳转换为普通格式时间
UPDATE u1 SET time_stamp=from_unixtime(time_stamp)
WHERE ID between 1 and 1000000;
UPDATE u1 SET time_stamp=from_unixtime(time_stamp)
WHERE ID between 1000001 and 2000000;
UPDATE u1 SET time_stamp=from_unixtime(time_stamp)
WHERE ID between 3000001 and 4000000;
UPDATE u1 SET time_stamp=from_unixtime(time_stamp)
WHERE ID between 3000001 and 4000000;
UPDATE u1 SET time_stamp=from_unixtime(time_stamp)
WHERE ID between 4000001 and 4999995;
-- 5,增添后面分析用到的日期列(dates)和小时列(hours)
ALTER table u1 add column dates varchar(20) ;
ALTER table u1 add column hours varchar(20) ;
-- 6,用字符串截取函数left()和mid()分别截取对应time_stamp列的日期和小时。
UPDATE u1 SET dates=left(time_stamp,10),hours=MID(time_stamp,12,2)
WHERE ID between 1 and 1000000;
UPDATE u1 SET dates=left(time_stamp,10),hours=MID(time_stamp,12,2)
WHERE ID between 1000001 and 2000000;
UPDATE u1 SET dates=left(time_stamp,10),hours=MID(time_stamp,12,2)
WHERE ID between 2000001 and 3000000;
UPDATE u1 SET dates=left(time_stamp,10),hours=MID(time_stamp,12,2)
WHERE ID between 3000001 and 4000000;
UPDATE u1 SET dates=left(time_stamp,10),hours=MID(time_stamp,12,2)
WHERE ID between 4000001 and 4999995;更新后的数据表样式如下:

查询表结构并修改dates列数据类型为日期类型(date)。
-- 7,查询表结构并修改dates列数据类型为日期类型(date)
DESC u1;
ALTER table u1 MODIFY dates date;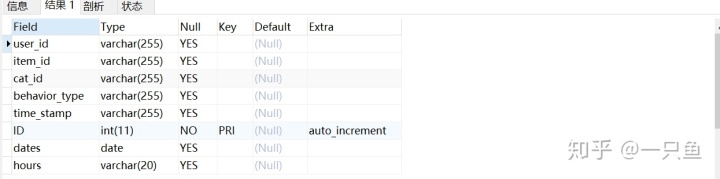
4,数据排序和异常值处理
原始数据集的说明是统计2017年11月25日到12月3日的用户行为,在navicat对表格dates列排序查看,发现有不在该时间段的数据。
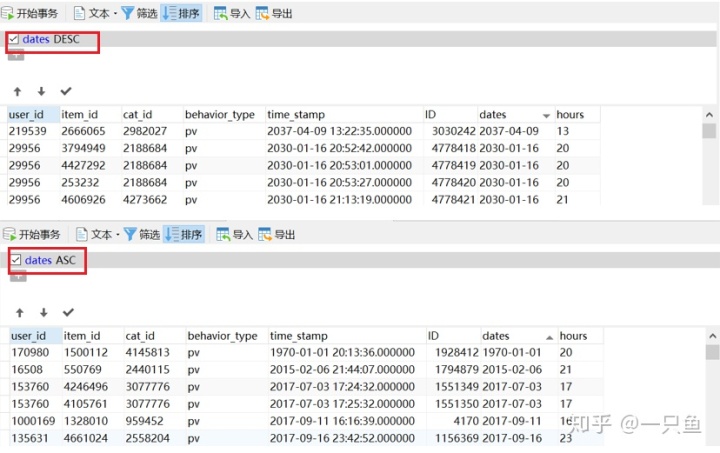
查找时间不在2017年11月25日到12月3日之间的数据,发现有2632条
-- 8,查找时间不在2017年11月25号到12月3号之间的数据
SELECT * from u1
WHERE dates not between '2017-11-25' and '2017-12-03'
ORDER BY dates;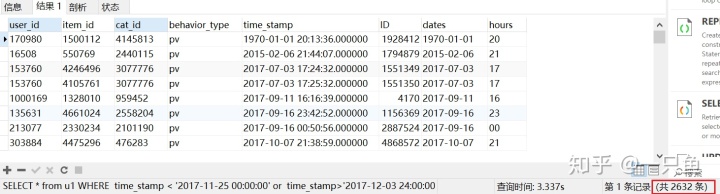
用delete from 语法删除异常数据。
-- 9,删除时间不在2017年11月25号到12月3号之间的数据
DELETE from u1
WHERE dates not between '2017-11-25' and '2017-12-03';5,查看清洗完之后的整体数据量
-- 10,查看清洗完之后的各字段数据量
SELECT count(distinct user_id) as 用户数量,
count(distinct item_id) as 商品数量,
count(distinct cat_id) as 商品类目数量,
count(distinct behavior_type) as 行为类型数量,
count(distinct dates) as 总天数,
count(distinct hours) as 总小时数,
count(time_stamp) as 总行为数量
FROM u1;
五,构建模型和数据可视化
1,分析网站每日流量数据
按照日期分类,查询日访问次数,日访问人数,日购买次数,日购买人数。并创建每日流量数据表day_kpi,用来监控店铺每天流量数据
-- 1,查询日访问次数pv,日访问人数uv,日购买次数。并创建视图d1
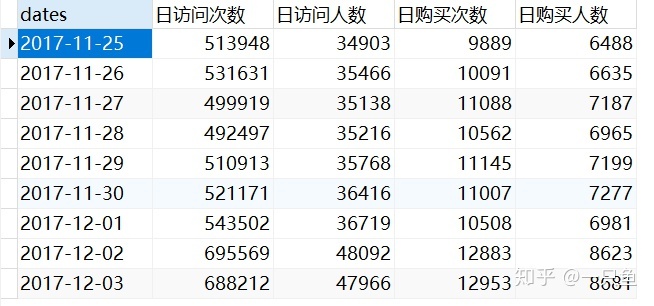
用Finebi连接Mysql,并导入day_kpi表,在仪表板绘制折线图,可视化效果如下:
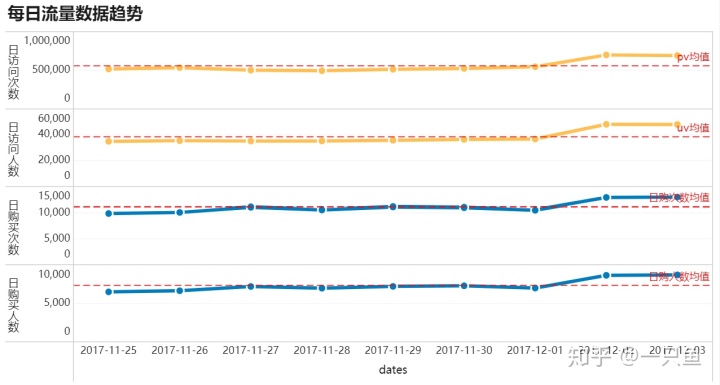
从图表很容易看出2017年11月25日—12月1日每天流量相对比较平稳,12月2号和12月3号这2天各数据流量均高于平均值。
进一步分析12月2日和12月3日这2天流量增加的原因,假设周末和工作日方面的影响。
用星期转化函数dayname() 将日期dates列转换为星期,发现12月2号和3号这2天正好是周末,由于数据集只有9天的流量信息,无法进一步验证是否每周末流量都比工作日环比增加。
-- 4,查询一周内每星期访问用户数
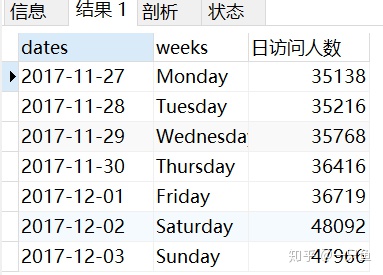
2,分析一天不同时间段用户活跃规律
查询一天24个小时不同时间段的访问次数pv和访问人数uv,并创建hour_kpi表
-- 1,查询每小时访问用户数和访问次数
CREATE TABLE hour_kpi AS
SELECT hours,count(DISTINCT user_id) as 每小时访问人数,
sum(case when behavior_type='pv' then 1 else 0 end) as 每小时访问次数
FROM u1
GROUP BY hours
ORDER BY hours;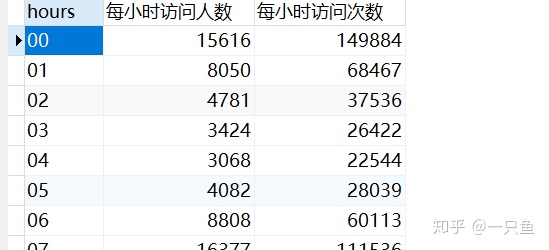
绘制折线图
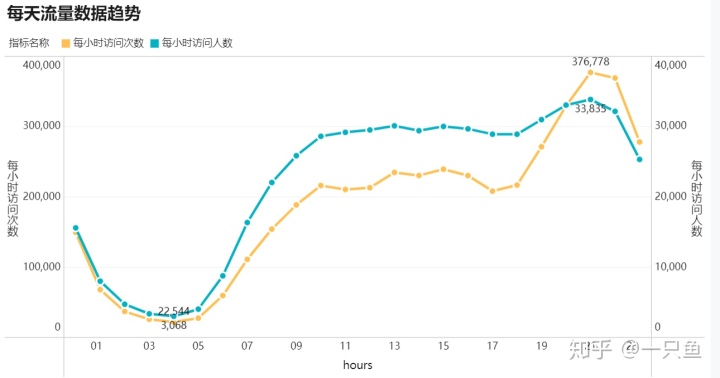
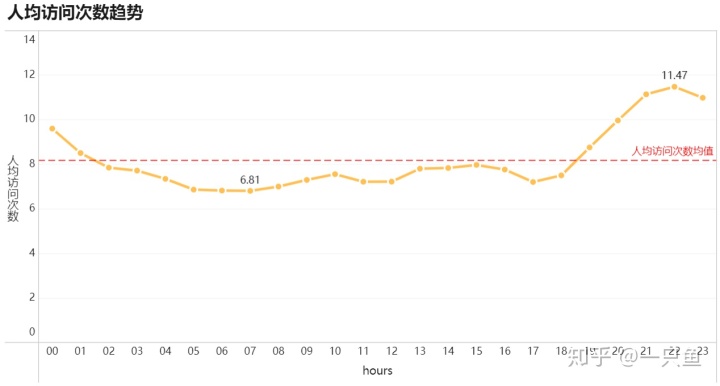
①从图1看出pv和uv一天当中变化规律:pv,uv都是从凌晨0点开始急剧下降,4点达到最低谷,6点开始急剧上升,10:00—18:00趋于平稳,18点开始继续上升,21点达到最高峰。基本符合一般人的正常作息规律。
②从图2可以看出用户在网站的浏览一天人均访问次数平均值是8.76次,其中19点到1点人均访问次数高于一天平均值,其他时间段相对比较平稳。
结合图1和图2,可以分析出一天不同时间段用户活跃规律:晚上7点到晚上11点淘宝访问用户量是一天当中最多的,晚上7点到凌晨1点人均访问次数是一天当中最多,值得注意的是晚上12点到凌晨1点虽然访问用户数相对较低,但是这段时间用户在淘宝的人均访问次数还是很高的。
3,基于AARRR漏斗模型分析用户购买
用户行为分为点击(pv)、加购物车(cart)、收藏(fav)和购买(buy)4种。其中点击次数代表用户活跃情况,收藏和加购物车次数代表用户对商品有购买意向,网站和店铺最关心的是最终购买次数。
淘宝用户购买途径大致有3种,一是点击之后直接购买,二是点击+加购物车+购买,三是点击+收藏之后,以后在点击+购买,或者点击+加购物车+购买。这里按照统计总点击次数、总收藏和加购次数以及总购买次数去分析各环节转化率。
-- 1,统计每个用户4种行为数据量。并创建视图cvr
CREATE VIEW cvr AS
SELECT user_id,count(behavior_type) as 总行为次数,
sum(case when behavior_type='pv' then 1 else 0 end) as 点击次数,
sum(case when behavior_type='fav' then 1 else 0 end) as 收藏次数,
sum(case when behavior_type='cart' then 1 else 0 end) as 加购次数,
sum(case when behavior_type='buy' then 1 else 0 end) as 购买次数
FROM u1
GROUP BY user_id
ORDER BY count(behavior_type) DESC;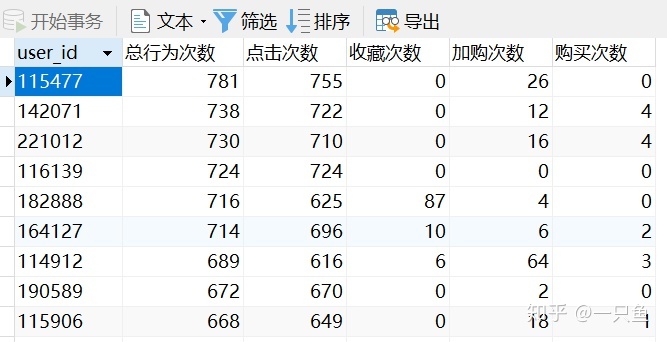
-- 2,用cvr视图查询点击、加购、收藏和购买的总行为次数,计算收藏转化率,加购转化率和购买转化率
SELECT sum(点击次数) as 总点击次数, sum(加购次数) as 总加购次数,sum(收藏次数) as 总收藏次数,
sum(购买次数) as 总购买次数
FROM cvr;
-- 3,计算点击率,收藏或加购物车转化率,购买转化率
SELECT concat(round(sum(点击次数)/sum(点击次数)*100,2),'%') as 点击率,
concat(round((sum(加购次数)+sum(收藏次数))/sum(点击次数)*100,2),'%') as 收藏或加购转化率,
concat(round(sum(购买次数)/sum(点击次数)*100,2),'%') as 购买转化率
FROM cvr;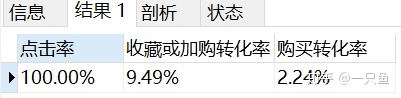
制作转化率漏斗图
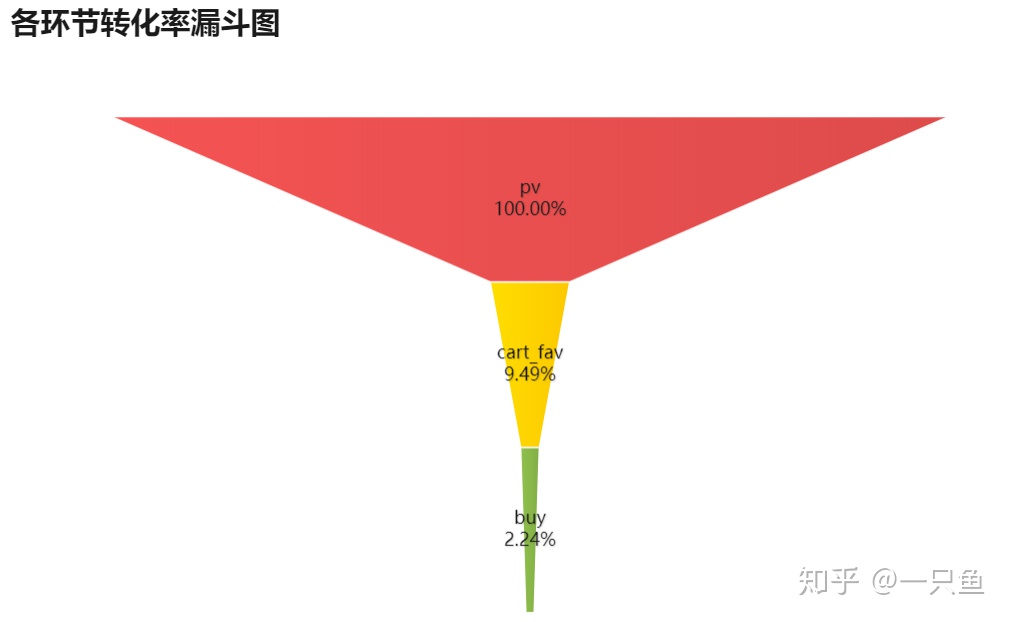
淘宝商品收藏和加购的转化率是9.49%,购买转化率是2.24%。由于转化率是根据行业或者竞品对比分析的,这里就不评价数据好坏。
4,基于RFM模型分析用户价值
R是指用户最近一次距离上一次购买时间的间隔天数,F是指用户在统计时间段的消费频次(一般同一天多次消费记为一次),M是指用户消费金额。
数据集统计时间是2017年11月25日到12月3日,时间跨度只有9天, R值计算客户最近一次购买距离2017年12月3日的天数,F值计算9天之内用户购买次数(同一天消费记作一次)
-- 1,统计有购买行为的用户表buy
create table buy as
select user_id,behavior_type,dates
from u1
where behavior_type='buy'
GROUP BY user_id ,dates
-- 2,计算每个用户最近一次购买时间与2017-12-03的间隔天数以及购买频次
CREATE TABLE frm as
SELECT user_id, DATEDIFF('2017-12-03',max(dates)) as 间隔天数,
count(behavior_type)as 购买频次
FROM buy
GROUP BY user_id
/* 3,间隔天数范围0-9,购买频次1-9。
F分为3个档次,[0,3]记作3,[4,6]记作2,[7,9]记作1
R分为3个档次,[1,3]记作1, [4-6]记作2,[7-9]记作3 */
CREATE table frm1 as
SELECT *,(case when 间隔天数<=3 then 3
when 间隔天数 BETWEEN 4 and 6 then 2
when 间隔天数>=7 then 1
else NULL end) as f_score,
(case when 购买频次<=3 then 1
when 购买频次 BETWEEN 4 and 6 then 2
when 购买频次>=7 then 3
else NULL end) as r_score
FROM frm;
-- 4,分别计算f和r 的平均分
select AVG(f_score),AVG(r_score) from frm1
/* 5,f和r都高于均值记作重要价值客户,f高r低记作重要保持客户,
F低R高记作重要发展客户,F和R都低于平均分记作一般价值客户*/
CREATE table frm2 as
SELECT * ,(case when f_score=3 and r_score>=2 then '重要价值客户'
when f_score=3 and r_score=1 then '重要保持客户'
when f_score<=2 and r_score>=2 then '重要发展客户'
when f_score<=2 and r_score=1 then '一般价值客户'
else NULL end ) as 客户价值
FROM frm1;
-- 6,查询各层级客户数量
select sum(case when 客户价值='重要价值客户' then 1 else 0 end) as 重要价值客户数,
sum(case when 客户价值='重要保持客户' then 1 else 0 end) as 重要保持客户数,
sum(case when 客户价值='重要发展客户' then 1 else 0 end) as 重要发展客户数,
sum(case when 客户价值='一般价值客户' then 1 else 0 end) as 一般价值客户数
from frm2;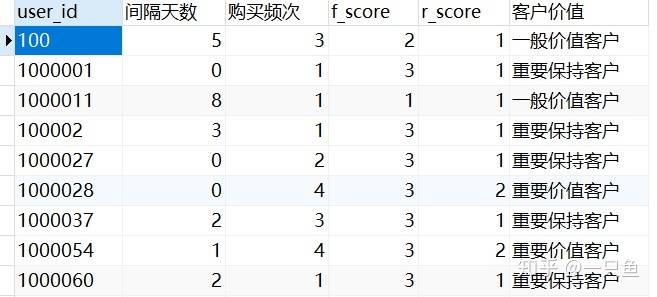

制作客户价值分类饼图:
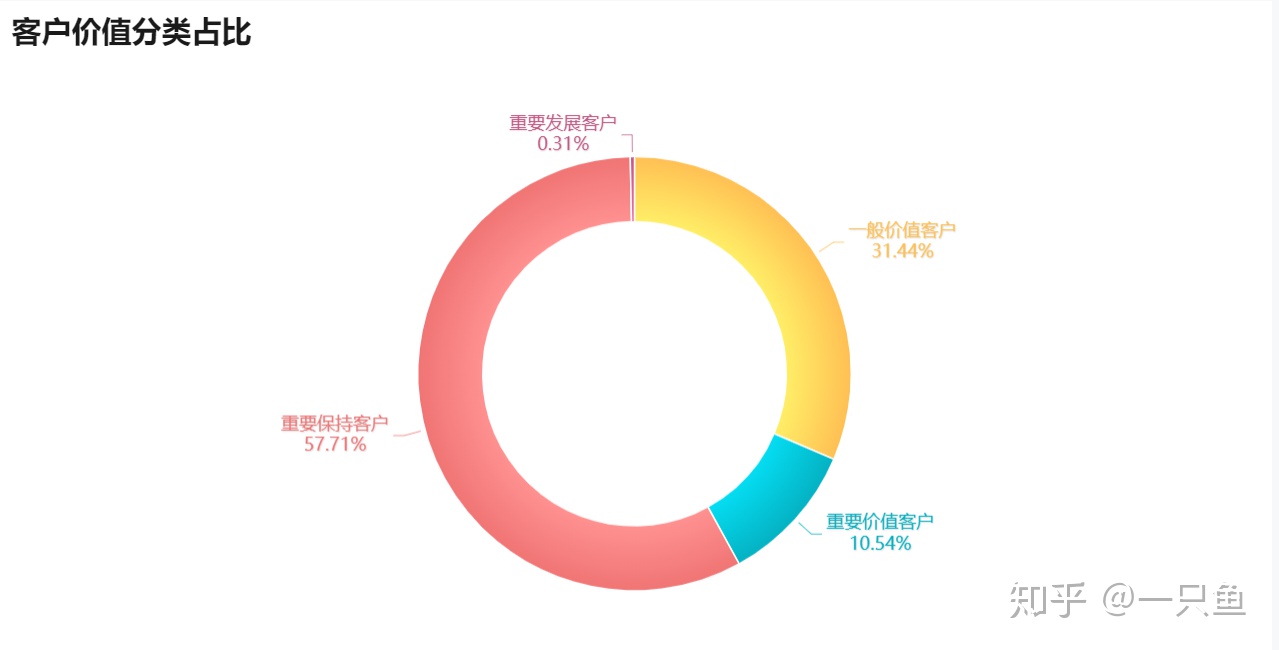
客户价值分类表可以用来制定CRM营销方案。比如:
- 对重要价值客户可以发放VIP会员卡,每次购物享受打折优惠,巩固忠诚客户。
- 对重要保持客户每次购物发放下次消费可用的满减购物券,提高消费频次。
- 对重要发展客户可以定期发送限期消费的无门槛购物券,唤醒沉睡客户。
- 对一般价值客户定期推送网站促销信息,吸引客户到网站浏览。
六,总结和建议
1,淘宝网站流量在2017年11月25日到12月3日,pv和uv在前5个工作日比较平稳,周末有所提升。
2,淘宝用户每天的访问高峰在晚上7点—晚上11点,低谷在凌晨0点—早上6点,上午和下午相对比较平稳。其中人均访问次数是8.76次,在晚上7点到凌晨1点是一天当中最高。
3,淘宝商品收藏和加购的转化率是9.49%,购买转化率是2.24%。
4,根据R和F客户价值分类模型,淘宝重要保持客户占比最多,达57.71%,重要发展客户占比最少,只有0.31%。建议网站近期注重提高用户消费频次,从而进一步提升重要价值用户数。














 3082
3082











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









