







PromptDet: Towards Open-vocabulary Detection using Uncurated Images_eccv2022
本文作者的核心目的是,在使用最少的人工成本下,来定位和识别 novel categories。本文的 novelty 来自两个方面,1)本文在 textual encoder side 提出一定数量的 prompt vectors ,称为 regional prompt learning (RPL) 来构建更好的 latent space 与 visual embedding 对齐;2)利用大量未被记录的 web 图像语料库,从 Internet 检索一组候选图像来进一步迭代优化 prompt vectors,并利用这些图片和对应的伪标签对检测器进行 self-train。
背景知识
open-vocabulary detector 的两个核心,1)产生精确的 class-agnostic region proposals,2)进行准确的开集识别,即 open-vocabulary classification。他们的做法如下
Class-agnostic region proposal network 作者对 anchor classification,bounding box regression,和 mask prediction 以 class-agnostic manner 进行参数化,即对于所有类别共享参数。
Open-vocabulary classification 作者说在 vision 和 natural language 中存在一个 common latent space ,可以在这个空间中找与视觉特征最近的 embedding,即可进行 open-vocabulary classification。
c
almond
=
ϕ
text
(
g
(
"this is a photo of
[
almond
‾
]
"
)
)
c
d
o
g
=
ϕ
text
(
g
(
"this is a photo of
[
dog
]
‾
]
"
)
)
p
almond
=
exp
(
<
v
,
c
almond
>
/
ϵ
)
exp
(
<
v
,
c
almond
>
/
ϵ
)
+
exp
(
<
v
,
c
d
o
g
>
/
ϵ
)
\begin{aligned} &c_{\text {almond }}=\phi_{\text {text }}(g(\text { "this is a photo of }[\underline{\text { almond }}] ")) \\ &c_{\mathrm{dog}}=\phi_{\text {text }}(g(\text { "this is a photo of }[\underline{\operatorname{dog}]}] ")) \\ &p_{\text {almond }}=\frac{\exp \left(<v, c_{\text {almond }}>/ \epsilon\right)}{\exp \left(<v, c_{\text {almond }}>/ \epsilon\right)+\exp \left(<v, c_{\mathrm{dog}}>/ \epsilon\right)} \end{aligned}
calmond =ϕtext (g( "this is a photo of [ almond ]"))cdog=ϕtext (g( "this is a photo of [dog]]"))palmond =exp(<v,calmond >/ϵ)+exp(<v,cdog>/ϵ)exp(<v,calmond >/ϵ)
下图(左)为一般的对齐过程。然而它会造成较差的泛化性,1)仅使用类名计算嵌入不太理想,因为其不够精确,无法描述视觉概念,从而导致词汇歧义;2)训练 CLIP 的 Web 图像往往是场景为中心,对象仅占一小部分,而使用RPNs的 object proposals 通常紧密的定位目标,从而导致视觉上出现明显的域差异(推测描述的是,训练 CLIP 并没有定位的过程);3)训练检测器的基础类别的数量远小于训练 CLIP 的,因此,可能不够充分来保证 novel categories 上的泛化性。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-td4K2EJw-1660628164085)(image-20220816110849342.png)]](https://img-blog.csdnimg.cn/f2ffdf4c343644ca981850cf116ed660.png)
Alignment via Regional Prompt Learning
从上文得知,训练 CLIP 的图像一般不做处理,而训练检测器的数据通常是目标为中心的,这种差异不利于优化。因此作者提出 regional prompt learning (RPL) 来引导文本潜层空间特征以更好地适应以对象为中心的图像。
具体做法有两个。1)加入自学习的 prompt vectors。做法和 [1,2] 很像。具体的思路是,固定网络结构,通过添加可学习的输入来促进优化的目的,获得更好的效果。2)为了减少类别单词的歧义,增加描述,这类描述可以从维基百科或者是数据集的 meta data 中获得,例如 {category: “almond”, description: “oval-shaped edible seed of the almond tree”}。最后获得的文本表征如下
c
almond
=
ϕ
text
(
[
p
1
,
…
,
p
j
,
g
(
category
‾
)
,
p
j
+
1
…
,
p
j
+
h
,
g
(
description
‾
)
]
)
c_{\text {almond }}=\phi_{\text {text }}\left(\left[p_{1}, \ldots, p_{j}, g(\underline{\text { category }}), p_{j+1} \ldots, p_{j+h}, g(\underline{\text { description }})\right]\right)
calmond =ϕtext ([p1,…,pj,g( category ),pj+1…,pj+h,g( description )])
这里
p
i
p_i
pi 表示 learnable prompt vectors。注意这里的 prompt vectors 是类别无关的,因此也能更好的泛化到新类中。
Optimising prompt vectors 为了节省计算,作者以离线方式学习 prompt vectors,具体来说,从LVIS中获取基本类别的对象裁剪,相应地调整它们的大小,并通过冻结的CLIP视觉编码器,以生成图像嵌入。visual 和 textual 编码器均被冻结。具体可以见上图的右图。
PromptDet: Alignment via Self-training
本任务另一个痛点在于缺少足够多的数据,导致泛化能力不足。而作者的想法是使用 large-scale, uncuratged, noisy 的 web images 来提高对齐质量。作者构建了一个学习框架,该框架迭代了 RPL 和候选图像产生,然后生成伪标签,并进行 self-training。
下图是 self-training 的框架。stage-I,使用 base 类别来学习 regional prompts。stage-II,通过 learned prompt 获得和下载互联网图像。stage-III,利用 LVIS 图片中的 base 数据和网络图片的 novel 数据 同时 self-train 检测器。
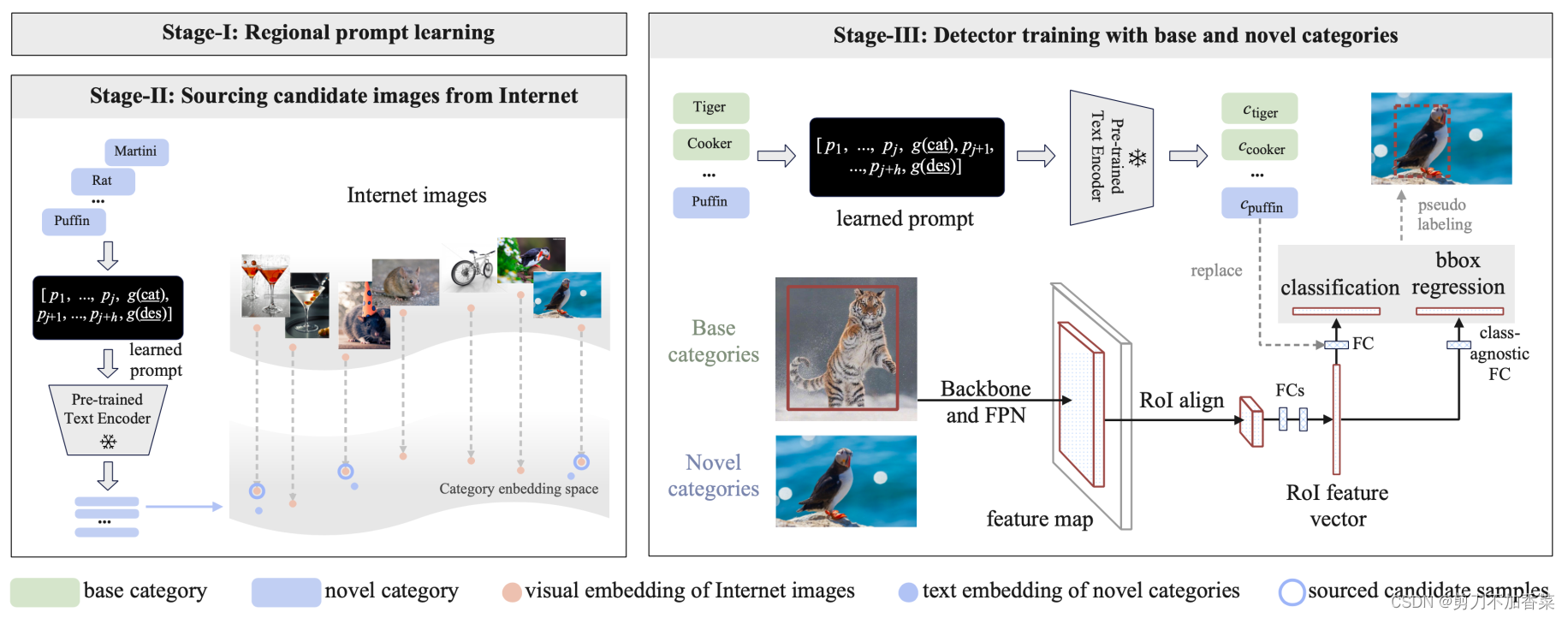
Sourcing candidate images 作者使用 LAION-400M dataset 作为初始的图片语料库,使用 CLIP 的视觉编码器获得视觉特征。作者计算视觉特征和文本特征的相似度,并保留具有最高相似度的图像。最终,使用 base 和 novel 类别构建了一组额外的图像,这组数据没有 ground truth。
Iterative prompt leanring and image sourcing 交替的执行 stage-I regional prompt learning 和 stage-II souring Internet images with prompt with high precision。
Bounding box generation对上述获得的数据利用模型打上标签(框)。
具体训练细节不做叙述,详见原文。
根据全文,文章方法的具体流程为,1 利用 LVIS-base 训练 prompts,使用固定的 CLIP 视觉和文本编码器,同时使用gt的标注框将目标裁剪下来再输入模型优化 prompts;2 在 LAION-400M 网络数据上,使用 learned prompt,利用 KNN 搜索,找到每个 novel class 对应的置信度最高的一批图片,作为后续 self-train 的图片;3 如果多次迭代,将原始的 LVIS-base 和新的 sourced images 同时来更新 prompt vectors,再继续搜索新类的 images,最后构建 LAION-novel dataset;4 在 LAION-novel dataset 上生成伪 bounding box,这样就能利用到这些 unlaleled instances; 5 在 Mask-RCNN 上 re-training visual backbone 和 RPN(including regression head),这里应该是先用 base 数据训练,再生成伪标签,继续用 novel 的数据训。
再总结本文的两个核心要点:1)prompt vectors。它的作用是更好的进行视觉(目标为中心的)-文本对齐,这其中加入类别的描述,从而减少歧义;2)利用大量的未被处理的网络数据,充分挖掘这些数据的潜力,具体而言是利用 CLIP 找到这里最有可能是 novel class 的图片,利用类别无关打上框标签,再将这些新数据加入数据集中训练。依此提高检测能力。时间和个人能力均有限,如有问题可继续讨论。
[1] AdaptFormer: Adapting Vision Transformers for Scalable Visual Recognition
[2] Visual Prompt Tuning. ECCV2022.















 1173
1173











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









