






 本文通过实验比较了ENVI平台上的六种遥感图像分类方法,包括最大似然法、最小距离法等。结果显示,最大似然法在精度和计算时间上表现出色,适合中低分辨率多光谱图像分类。支持向量机法精度最高,但计算时间较长。各方法各有优劣,适用于不同场景。
本文通过实验比较了ENVI平台上的六种遥感图像分类方法,包括最大似然法、最小距离法等。结果显示,最大似然法在精度和计算时间上表现出色,适合中低分辨率多光谱图像分类。支持向量机法精度最高,但计算时间较长。各方法各有优劣,适用于不同场景。
概述:
基于 ENVI 平台,利用该平台自带的 Landsat tm5 多光谱遥感图像作为数据源,进行监督分类应用实验,并对其分类结果进行精度比较,结果表明:6 种监督分类方法中最大似然法分类精度较高,且计算时间相对较短,更普遍适合
中低分辨率多光谱遥感图像分类工作。根据具体需求,同学们可以选择自己合适的分类方法。
方法:
监督分类主要分为平行六面体分类法、最小距离分类法、马氏距离分类法、最大似然分类法、神经网络分类法、支持向量机分类法。
数据与实验
实验数据。本文以 ENVI 自带的 Landsat tm5数据 Can_tmr.img 多光谱遥感图像作为主要数据源,以波段 5,4,3 模拟真彩色图像合成 RGB 进行显示,根据图像的光谱特征,通过人工判读把图像中的地物分为林地、草地、耕地、裸地、沙地、水体6 类,见图 1。通过绘制多边形感兴趣区进行训练样本选取,并对每类地物的感兴趣区用不同颜色加以区分。

图1 原始影像
分类实验。创建 6 类感兴趣区分别为林地、草地、耕地、裸地、沙地、水体,并以此定义训练样本。各个样本类型之间的可分离性,用 Jeffries-Matusita 距离和转换分离度参数表示,根据可分离性值的大小,从小到大列出感兴趣区组合。这两个参数的值在 0~2.0 之间,大于 1.9 说明样本之间可
分离性好,属于合格样本;小于 1.8,需重新选择样本。训练样本可分离性计算报表见表 1,可见各样本分离性均在 1.9 以上,说明各类感兴趣区分离性较好,选择该感兴趣区作为训练样本较为合适。
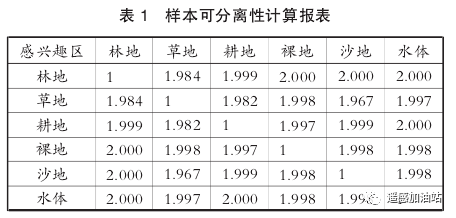
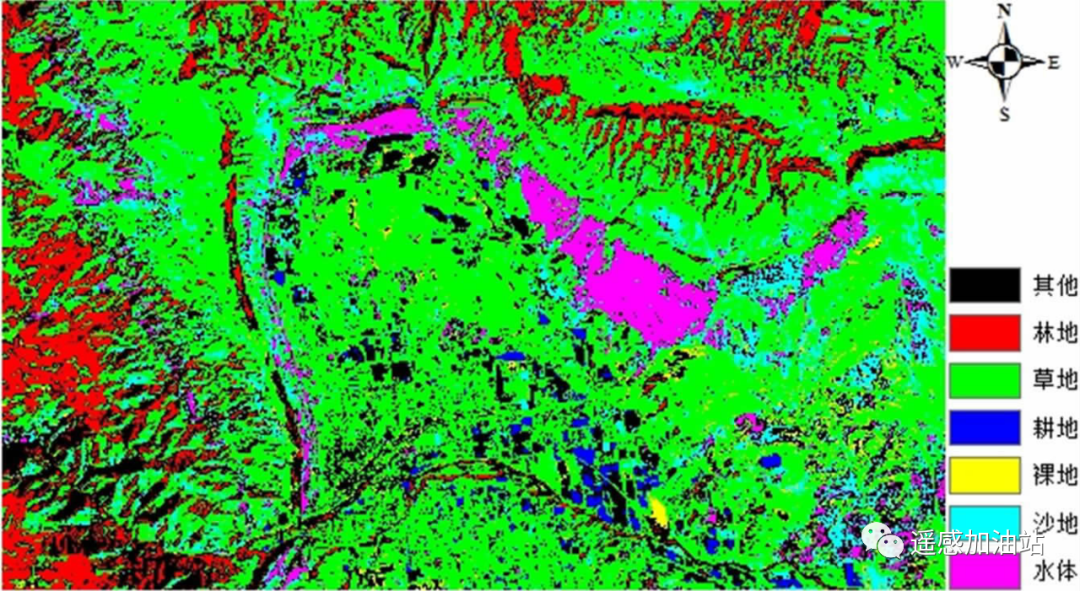
图2 平行六面体分类结果
图3最大似然分类结果
图4 最小距离分类结果
图5 马式距离分类结果
图6 神经网络分类结果
图7 支持向量机分类结果
结果精度分析
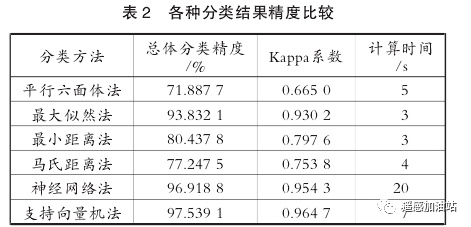
1)平行六面体法的总体分类精度为71.8877%, Kappa系数为0.6650,计算时间为5s;最大似然法的总体分类精度为93.8321% ,Kappa系数为0.9302,计算时间为3s;最小距离法的总体分类精度为80.4378% , Kappa系数为0.7976 ,计算时间为35;马氏距离法的总体分类精度为77.2475%, Kappa系数为0.7538,计算时间为4 s;神经网络法的总体分类精度为96.918 8% , Kappa系数为0.9543,计算时间为20s;支持向量机法的总体分类精度为97.5391 % , Kappa系数为 0.9647 ,计算时间为7s 。
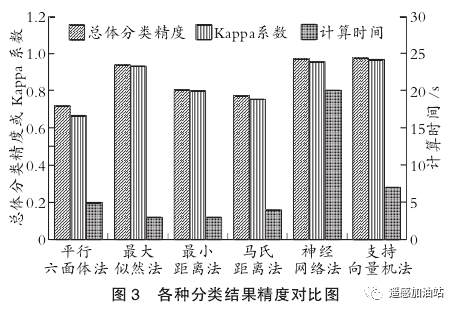
2)6 种分类方法中支持向量机法具有最高的分类精度,分类效果最好,能够较为准确地提取目标地物,但计算时间较长;平行六面体法分类精度最低,效果最差,得到的结果容易出现重叠,混淆不清的结果,但算法较为简单,计算时间也短。
3)最大似然法和神经网络法也具有较高的分类精度,其中最大似然法计算时间较短,神经网络法计算时间相比于其他 5 种分类法均较长。
4)最小距离法和马氏距离法的精度并不是很高,其中最小距离法容易出现大面积没有被分类成果的区域,但该算法较为简单,且计算时间较短。
5)针对本文采用的中低分辨率多光谱数据,6 种分类方法的计算时间均可在 20 s 之内完成,较为短暂。但因在实际应用中遥感数据的类型及大小不同,使用不同分类方法计算时具体计算时间会有所差异。

















 2270
2270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









