






这篇主要记录一下如何实现对数据库的并行运算来节省代码运行时间。语言是Python,其他语言思路一样。
前言
一共23w条数据,是之前通过自然语言分析处理过的数据,附一张截图:
要实现对news主体的读取,并且找到其中含有的股票名称,只要发现,就将这支股票和对应的日期、score写入数据库。
显然,几十万条数据要是一条条读写,然后在本机上操作,耗时太久,可行性极低。所以,如何有效并行的读取内容,并且进行操作,最后再写入数据库呢?
并行读取和写入
并行读取:创建N*max_process个进程,对数据库进行读取。读取的时候应该注意:
每个进程需要分配不同的connection和对应的cursor,否则数据库会报错。
数据库必须能承受相应的高并发访问(可以手动更改)
实现的时候,如果不在进程里面创建新的connection,就会发生冲突,每个进程拿到权限后,会被下个进程释放,所以汇报出来NoneType Error的错误。
并行写入:在对数据库进行更改的时候,不可以多进程更改。所以,我们需要根据已有的表,创建max_process-1个同样结构的表用来写入。表的命名规则可以直接在原来基础上加上1,2,3...数字可以通过对max_process取余得到。
此时,对应进程里面先后出现读入的conn(保存消息后关闭)和写入的conn。每个进程对应的表的index就是 主循环中的num对max_process取余(100->4,101->5),这样每个进程只对一个表进行操作了。
部分代码实现
max_process = 16 #最大进程数
def read_SQL_write(r_host,r_port,r_user,r_passwd,r_db,r_charset,w_host,w_port,w_user,w_passwd,w_db,w_charset,cmd,index=None):
#得到tem字典保存着信息
try:
conn = pymysql.Connect(host=r_host, port=r_port, user=r_user, passwd =r_passwd, db =r_db, charset =r_charset)
cursor = conn.cursor()
cursor.execute(cmd)
except Exception as e:
error = "[-][-]%d fail to connect SQL for reading" % index
log_error('error.log',error)
return
else:
tem = cursor.fetchone()
print('[+][+]%d succeed to connect SQL for reading' % index)
finally:
cursor.close()
conn.close()
try:
conn = pymysql.Connect(host=w_host, port=w_port, user=w_user, passwd =w_passwd, db =w_db, charset =w_charset)
cursor = conn.cursor()
cursor.execute(cmd)
except Exception as e:
error = "[-][-]%d fail to connect SQL for writing" % index
log_error('error.log',error)
return
else:
print('[+][+]%d succeed to connect SQL for writing' % index)
r_dict = dict()
r_dict['id'] = tem[0]
r_dict['content_id'] = tem[1]
r_dict['pub_date'] = tem[2]
r_dict['title'] = cht_to_chs(tem[3])
r_dict['title_score'] =tem[4]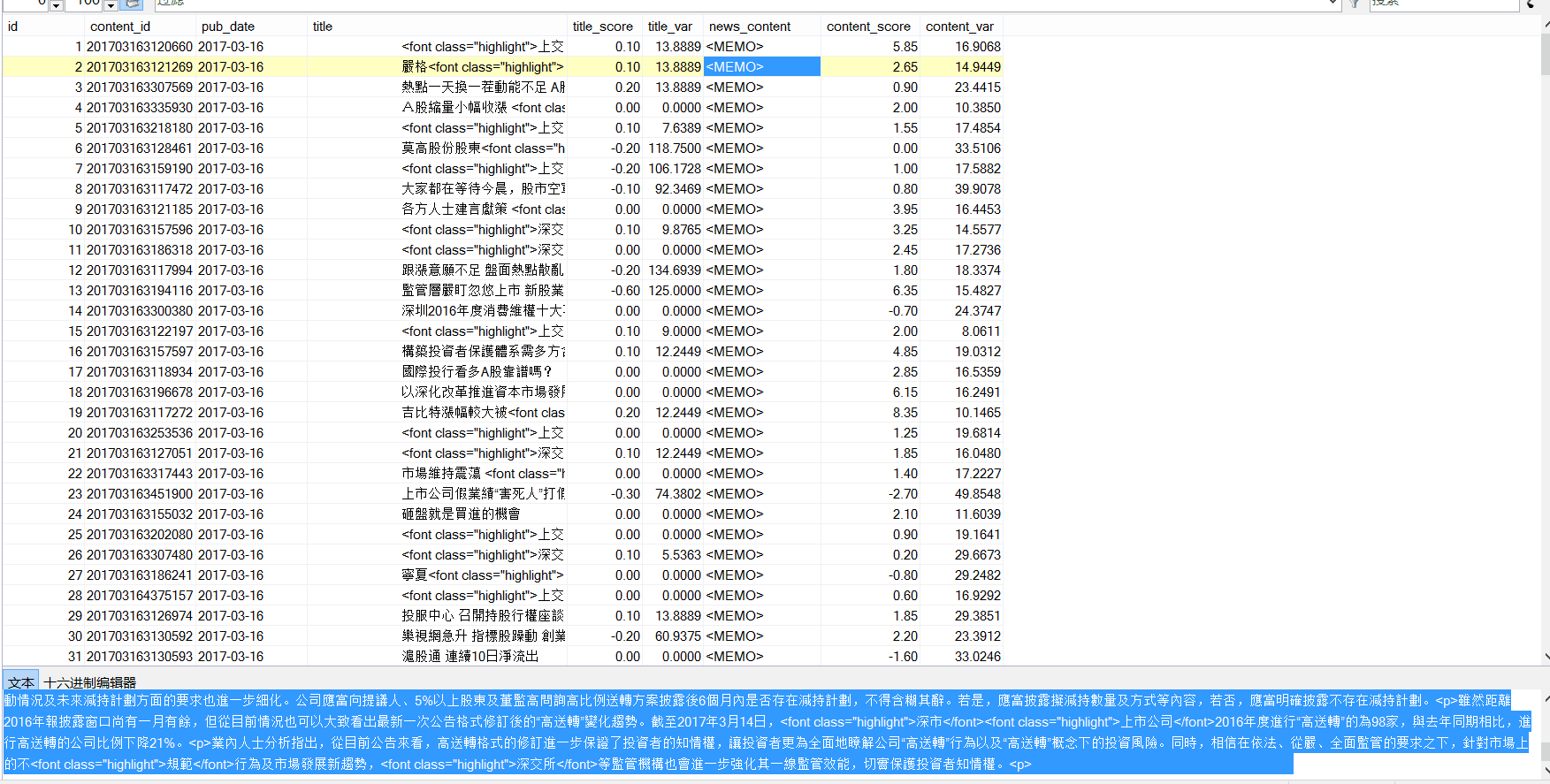
r_dict['news_content'] = cht_to_chs(tem[5])
r_dict['content_score'] = tem[6]
for key in stock_dict.keys():
#能找到对应的股票
if stock_dict[key][1] and ( r_dict['title'].find(stock_dict[key][1])!=-1 or r_dict['news_content'].find(stock_dict[key][1])!=-1 ):
w_dict=dict()
w_dict['code'] = key
w_dict['english_name'] = stock_dict[key][0]
w_dict['cn_name'] = stock_dict[key][1]
#得到分数
if r_dict['title_score']:
w_dict['score']=r_dict['title_score']
else:
w_dict['score']=r_dict['content_score']
#开始写入
try:
global max_process
cmd = "INSERT INTO dyx_stock_score%d VALUES ('%s', '%s' , %d , '%s' , '%s' , %.2f );" % \
(index%max_process ,r_dict['content_id'] ,r_dict['pub_date'] ,w_dict['code'] ,w_dict['english_name'] ,w_dict['cn_name'] ,w_dict['score'])
cursor.execute(cmd)
conn.commit()
except Exception as e:
error = " [-]%d fail to write to SQL" % index
cursor.rollback()
log_error('error.log',error)
else:
print(" [+]%d succeed to write to SQL" % index)
cursor.close()
conn.close()
def main():
num = 238143#数据库查询拿到的总数
p = None
for index in range(1,num+1):
if index%max_process==1:
if p:
p.close()
p.join()
p = multiprocessing.Pool(max_process)
r_cmd = ('select id,content_id,pub_date,title,title_score,news_content,content_score from dyx_emotion_analysis where id = %d;' % (index))
p.apply_async(func = read_SQL_write,args=(r_host,r_port,r_user,r_passwd,r_db,r_charset,w_host,w_port,w_user,w_passwd,w_db,w_charset,r_cmd,index,))
if p:
p.close()
p.join()
MFC+mongodb+nodejs 数据库的读取与写入操作
首先通过nodejs和mongodb建立后端服务器 一.在windows平台下启动mongodb服务器 1.进入mongodb的安装目录,并进去bin目录启动mongod 2.在d盘建立mongodb ...
SQLBulkCopy使用实例--读取Excel写入数据库/将 Excel 文件转成 DataTable
MS SQL Server 提供一个称为 bcp 的流行的命令提示符实用工具,用于将数据从一个表移动到另一个表(表可以在不同服务器上). SqlBulkCopy 类允许编写提供类似功能的托管代码解决方 ...
转载-python学习笔记之输入输出功能读取和写入数据
读取.写入和 Python 在 “探索 Python” 系列以前的文章中,学习了基本的 Python 数据类型和一些容器数据类型,例如tuple.string 和 list.其他文章讨论了 Pytho ...
Php连接及读取和写入mysql数据库的常用代码
在这里我总结了常用的PHP连接MySQL数据库以及读取写入数据库的方法,希望能够帮到你,当然也是作为我自己的一个回顾总结. 1.为了更好地设置数据连接,一般会将数据连接所涉及的值定义成变量. $mys ...
获取博客积分排名,存入数据库,读取数据进行绘图(python,selenium,matplotlib)
该脚本的目的:获取博客的排名和积分,将抓取时间,排名,积分存入数据库,然后把最近的积分和排名信息进行绘图,查看积分或者排名的变化情况. 整个脚本的流程:是利用python3来编写,利用selnium获 ...
php checkbox 从数据库读取和写入
checkbox将选中的值写入数据库中,在修改的时候如何从数据库中读取并设定Checkbox的状态 1.写入数据库提交后因为你的rol是数组,所以可以使用$_POST获取 PHP code ? 1 ...
Python对于CSV文件的读取与写入
今天天气"刚刚好"(薛之谦么么哒),无聊的我翻到了一篇关于csv文件读取与写入的帖子,作为测试小白的我一直对python情有独钟,顿时心血来潮,决定小搞他一下,分享给那些需要的小白 ...
python读取与写入csv,txt格式文件
python读取与写入csv,txt格式文件 在数据分析中经常需要从csv格式的文件中存取数据以及将数据写书到csv文件中.将csv文件中的数据直接读取为dict类型和DataFrame是非常方便也很 ...
python文件读取和写入案例
python文件读取和写入案例 直接上代码吧 都是说明 百度上找了很多,最终得出思路 没有直接可以读取修改的扩展,只能先读取,然后复制一份,然后在复制出来的文件里面追加保存 然后删除读的那个,但是缺 ...
随机推荐
ubuntu svn安装测试
本机环境 :ubuntu 12.4 LTS desktop 1 sudo apt-get install subversion #安装svn 2 sudo mkdir /home/lzj/s ...
delphi 写系统日志监控 转
不久前写了个抓取网页内容的小程序,跑了一晚上,本以为早上起来都抓完了,谁知道程序死掉了,分析半天,才发现用tmemo来记录日志的信息太多了,越积越多,本来memo的容量就不大.对于无法控制信息量的日志 ...
js执行环境相关
Js执行过程 如果一个文档中存在多个代码段 步骤一:读入第一个代码段(js引擎并非一行一行执行,而是一段一段分析执行) 步骤二:做词法分析和语法分析,有错则报语法错误(比如括号不匹配等),并跳转到步骤 ...
wcf的binding和host
----------------------------Binding绑定:定义:绑定表示通讯信道的配置:定义了客户端与服务端之间的协议:---传输协议:http.tcp.命名管道.msmq,自定义( ...
浅析mydumper
Ⅰ.背景 mysqldump单线程备份,很慢 恢复慢,一张表一张表恢复, 如果备份了100G的数据,想恢复其中一个表,做不到(所有的表都在一个文件里) 所以推荐使用mydumper备份 备份并行,基于 ...
PHP-MySQL基本操作
PHP-MySQL基本操作 <?php // 1.防止页面中文乱码 header("content-type:text/html;charset=utf-8"); // 链接 ...
HDU - 6394 Tree(树分块+倍增)
http://acm.hdu.edu.cn/showproblem.php?pid=6394 题意 给出一棵树,然后每个节点有一个权值,代表这个点可以往上面跳多远,问最少需要多少次可以跳出这颗树 分析 ...
Ubuntu 远程使用ssh 开启服务器终端的方法
首先,加载服务器环境变量$DISPLAY,需要先从服务器获取值 echo $DISPLAY 假如返回值为1001,本地通过sshpass启动终端,假设服务器用户名server,密码passwd, ip ...
冒泡排序快速版(C)
冒泡排序C语言版:在每轮排序中检查时候有元素位置交换,如果无交换,说明数组元素已经有序,无需继续排序 #include #include
Android 上SuperUser获取ROOT权限原理解析
Android 上SuperUser获取ROOT权限原理解析 一. 概述 本文介绍了android中获取root权限的方法以及原理,让大家对android 玩家中常说的“越狱”有一个更深层次的认识. ...














 9278
9278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









