





一、
 鸢尾花的花语是信赖。小时候看的日漫彩虹国物语里经常出现鸢尾花,当国王送给心仪的女臣时,说
“这代表了无限的希望和可能性”。也有的说鸢尾花的花语是想念。
鸢尾花的花语是信赖。小时候看的日漫彩虹国物语里经常出现鸢尾花,当国王送给心仪的女臣时,说
“这代表了无限的希望和可能性”。也有的说鸢尾花的花语是想念。
二、鸢尾花数据集 著名的遗传学家、统计学家Fisher曾经研究不同种鸢尾花表型遗传的时候,面临着鸢尾花表型的分类问题,很聪明地将花瓣长度、宽度,以及花萼的长度和宽度四种属性进行定量化,然后特征性提取属性特征。然后Fisher建立了现在大数据分析学习中经典的
鸢尾花数据集(Iris dataset)
。关于Fisher老爷子,有两个听闻:第一个是,现在的机器学习统计学方法的50%、以及现在遗传学中的统计方法的90%是建立在当年Fisher的研究工作中;第二个是,Fisher当年的论文晦涩难懂,专门学统计的人要花1天的时间,才能读完他论文的一页。但是,对于传闻,经常会出现误传和夸大,比如这几个数字我可能就记错了。鸢尾花数据集长这样(https://www.bilibili.com/video/BV1CW411F7ki)
著名的遗传学家、统计学家Fisher曾经研究不同种鸢尾花表型遗传的时候,面临着鸢尾花表型的分类问题,很聪明地将花瓣长度、宽度,以及花萼的长度和宽度四种属性进行定量化,然后特征性提取属性特征。然后Fisher建立了现在大数据分析学习中经典的
鸢尾花数据集(Iris dataset)
。关于Fisher老爷子,有两个听闻:第一个是,现在的机器学习统计学方法的50%、以及现在遗传学中的统计方法的90%是建立在当年Fisher的研究工作中;第二个是,Fisher当年的论文晦涩难懂,专门学统计的人要花1天的时间,才能读完他论文的一页。但是,对于传闻,经常会出现误传和夸大,比如这几个数字我可能就记错了。鸢尾花数据集长这样(https://www.bilibili.com/video/BV1CW411F7ki)
三、主成分分析步骤这样的矩阵和我们临床研究时候差不多。当比如有一个研究问题:脑白质高信号模式能否区分出PD认知障碍人群?然后我计算了90个脑区的白质高信号。传统的统计学没法对这么多参数进行一次性组间比较,主成分分析就可以将这么多脑区降维成几个对目标参数有意义的成分,然后就可以按照传统的统计分析方法做。大概分成几步:1,对皮层厚度进行 z转化(目的:使之趋向正态【但是不一定能实现正态】,且消除单位不一致的影响)2. 主成分分析(SPPS-分析-降维-因子),不用选择变量,以90个脑区的白质高信号z值为变量,获得主成分得分, 将主成分得分与你感兴趣的行为学相关或者疾病做差异性分析。3. 观察主成分组成,观察几个指标:①特征值的方差百分比(理解成该主成分对总体的贡献率),②所有特征值累积百分比(理解成所有主成分合起来分类的效果),③成分矩阵(理解成每个脑区白质高信号对该主成分的贡献);还可以再选上成分得分系数( 每个脑区白质高信号与该主成分的相关系数),与成分矩阵的关系大概是变量的成分得分矩阵开方*主成分得分=成分矩阵4. 直观 看一眼分类效果 第2步、第3步、第4步可以根据需要换一下顺序。操作见下链接https://jingyan.baidu.com/article/6181c3e087a97a152ff15357.html自己按照痴呆分组算出了主成分。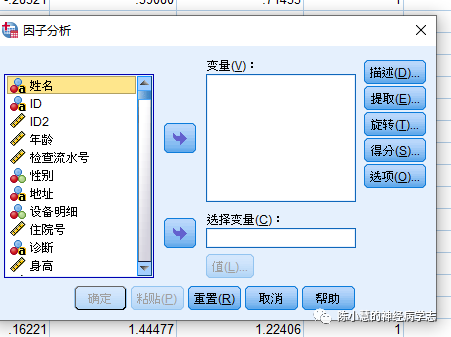
四、结果解读:1. 90个脑区的白质高信号提取出3个主成分,累积贡献率为70.988%,分类效果一般(80%以上算比较满意)。其中第一个主成分贡献率56.7%,第二个是7.25%,第3个6.96——第一个主成分权重比较大。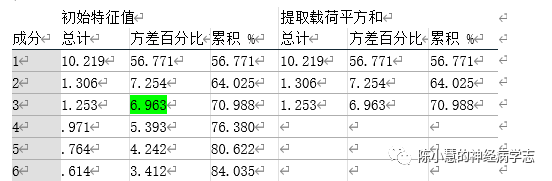 2. 与认知评分做线性归回模型,只有主成分3有意义
2. 与认知评分做线性归回模型,只有主成分3有意义
 3. 观察主成分3的构成,主要与顶枕叶白质高信号相关性比较强。其实也是比较符合文献研究现状的。
3. 观察主成分3的构成,主要与顶枕叶白质高信号相关性比较强。其实也是比较符合文献研究现状的。
 4. 构建分类图,观察主成分分类相关。三个坐标维度就是三个主成分得分。
4. 构建分类图,观察主成分分类相关。三个坐标维度就是三个主成分得分。
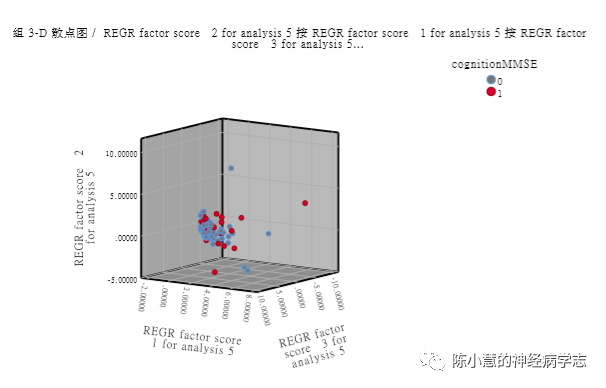 可以看到两组重叠在一起了,分类效果不好。
本次分析结果不太满意。
可以看到两组重叠在一起了,分类效果不好。
本次分析结果不太满意。
五、上次被问到 “你用的是哪种主成分?”遇到行家的时候就捉襟见肘了,会后试着查了一下matlab公式。matlab实现主成分分析,基本只要一行代码,用一个PCA的公式,详见https://www.bilibili.com/video/BV1Es411V7dj。感谢代码君传递知识。自己也试着跑了一下matlab,和SPSS是完全一样的。下图是是matlab的分类效果图,条形图是各个主成分单独的分类效果;散点图是主成分两两结合的分类效果,三个主成分对于痴呆的区分效果不好。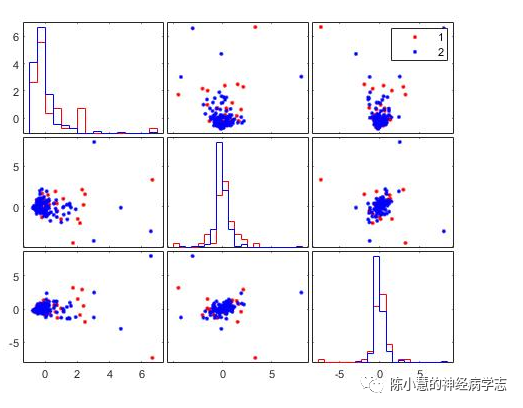
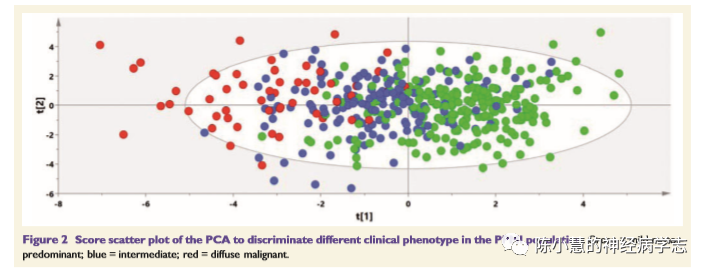
六、主成分分析的方法在文章中很常见比如,这篇Brain文章通过数据挖掘、聚类建立帕金森亚型诊断方法的文章也用到了主成分分析,但是其实从图上看,分类效果一般。
 下图是文初提到的鸢尾花数据集的主成分分类效果:第一个主成分就把不同种类鸢尾花很好分开了。
下图是文初提到的鸢尾花数据集的主成分分类效果:第一个主成分就把不同种类鸢尾花很好分开了。

七、个人觉得,数据挖掘、大数据分析、数据驱动、机器学习等是数据量增大情况下,被开发的工具,但是也代替不了传统统计学,更像是解决传统方法解决不了的问题时可以选用。数据驱动容易产生假阳性(数据多了,比较起来就有多重比较校正的问题),要通过传统统计学再来验证。而且,当数据量不大的时候,你会发现,data mining的方法和传统统计方法做出来的结果是一样、一样、一样的。 数据驱动分析还有一个问题:分析出来的结果有时候没有统计值,或者临床意义不明(黑箱),有时候需要临床解读,或者再在临床验证。 做科研真的会有点“费头发”。
鸢尾花的花语是信赖。小时候看的日漫彩虹国物语里经常出现鸢尾花,当国王送给心仪的女臣时,说
“这代表了无限的希望和可能性”。也有的说鸢尾花的花语是想念。
二、鸢尾花数据集
著名的遗传学家、统计学家Fisher曾经研究不同种鸢尾花表型遗传的时候,面临着鸢尾花表型的分类问题,很聪明地将花瓣长度、宽度,以及花萼的长度和宽度四种属性进行定量化,然后特征性提取属性特征。然后Fisher建立了现在大数据分析学习中经典的
鸢尾花数据集(Iris dataset)
。关于Fisher老爷子,有两个听闻:第一个是,现在的机器学习统计学方法的50%、以及现在遗传学中的统计方法的90%是建立在当年Fisher的研究工作中;第二个是,Fisher当年的论文晦涩难懂,专门学统计的人要花1天的时间,才能读完他论文的一页。但是,对于传闻,经常会出现误传和夸大,比如这几个数字我可能就记错了。鸢尾花数据集长这样(https://www.bilibili.com/video/BV1CW411F7ki)
| % meas是鸢尾花一些特征的检测结果,矩阵大小150*4 | |
| % meas每一行对应一个观测结果,整个数据集有150个观测结果 | |
| % meas每一列对应鸢尾花的一种特征属性, | |
| % means的4列对应的属性分别是:萼片长度,萼片宽度,花瓣长度,花瓣宽度 | |
| %%% 种类标记 species | |
| % species是鸢尾花种类 | |
| % setosa 山鸢尾, versicolor 多色鸢尾, virginica 弗吉尼亚鸢尾 |
三、主成分分析步骤这样的矩阵和我们临床研究时候差不多。当比如有一个研究问题:脑白质高信号模式能否区分出PD认知障碍人群?然后我计算了90个脑区的白质高信号。传统的统计学没法对这么多参数进行一次性组间比较,主成分分析就可以将这么多脑区降维成几个对目标参数有意义的成分,然后就可以按照传统的统计分析方法做。大概分成几步:1,对皮层厚度进行 z转化(目的:使之趋向正态【但是不一定能实现正态】,且消除单位不一致的影响)2. 主成分分析(SPPS-分析-降维-因子),不用选择变量,以90个脑区的白质高信号z值为变量,获得主成分得分, 将主成分得分与你感兴趣的行为学相关或者疾病做差异性分析。3. 观察主成分组成,观察几个指标:①特征值的方差百分比(理解成该主成分对总体的贡献率),②所有特征值累积百分比(理解成所有主成分合起来分类的效果),③成分矩阵(理解成每个脑区白质高信号对该主成分的贡献);还可以再选上成分得分系数( 每个脑区白质高信号与该主成分的相关系数),与成分矩阵的关系大概是变量的成分得分矩阵开方*主成分得分=成分矩阵4. 直观 看一眼分类效果 第2步、第3步、第4步可以根据需要换一下顺序。操作见下链接https://jingyan.baidu.com/article/6181c3e087a97a152ff15357.html自己按照痴呆分组算出了主成分。
四、结果解读:1. 90个脑区的白质高信号提取出3个主成分,累积贡献率为70.988%,分类效果一般(80%以上算比较满意)。其中第一个主成分贡献率56.7%,第二个是7.25%,第3个6.96——第一个主成分权重比较大。
2. 与认知评分做线性归回模型,只有主成分3有意义
3. 观察主成分3的构成,主要与顶枕叶白质高信号相关性比较强。其实也是比较符合文献研究现状的。
4. 构建分类图,观察主成分分类相关。三个坐标维度就是三个主成分得分。
可以看到两组重叠在一起了,分类效果不好。
本次分析结果不太满意。
五、上次被问到 “你用的是哪种主成分?”遇到行家的时候就捉襟见肘了,会后试着查了一下matlab公式。matlab实现主成分分析,基本只要一行代码,用一个PCA的公式,详见https://www.bilibili.com/video/BV1Es411V7dj。感谢代码君传递知识。自己也试着跑了一下matlab,和SPSS是完全一样的。下图是是matlab的分类效果图,条形图是各个主成分单独的分类效果;散点图是主成分两两结合的分类效果,三个主成分对于痴呆的区分效果不好。
六、主成分分析的方法在文章中很常见比如,这篇Brain文章通过数据挖掘、聚类建立帕金森亚型诊断方法的文章也用到了主成分分析,但是其实从图上看,分类效果一般。
下图是文初提到的鸢尾花数据集的主成分分类效果:第一个主成分就把不同种类鸢尾花很好分开了。
七、个人觉得,数据挖掘、大数据分析、数据驱动、机器学习等是数据量增大情况下,被开发的工具,但是也代替不了传统统计学,更像是解决传统方法解决不了的问题时可以选用。数据驱动容易产生假阳性(数据多了,比较起来就有多重比较校正的问题),要通过传统统计学再来验证。而且,当数据量不大的时候,你会发现,data mining的方法和传统统计方法做出来的结果是一样、一样、一样的。 数据驱动分析还有一个问题:分析出来的结果有时候没有统计值,或者临床意义不明(黑箱),有时候需要临床解读,或者再在临床验证。 做科研真的会有点“费头发”。















 2530
2530











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









