





论文: A Multilayer Convolutional Encoder-Decoder Neural Network for Grammatical Error Correction
作者: Shamil Chollampatt1, Hwee Tou
源码: https://github.com/nusnlp/mlconvgec2018
notes:该方法效果已经落后于基于翻译的纠错系统
一、简介
我们使用多层卷积编码器/解码器神经网络来改进文本中语法,ortho-graphic, 固定搭配错误的自动校正。使用嵌入的字符初始化网络,该嵌入利用字符N-gram更好地适合此任务。当在通用基准测试数据集(CoNLL-2014和JF-LEG)上进行评估时,我们的模型在此任务上的性能明显优于所有先前的方法,以及优于经过训练的强大的基于统计机器翻译的神经系统和特定任务。我们的分析表明,卷积神经网络优于循环神经网络(例如长短期记忆(LSTM)网络),可以通过注意力捕获局部上下文,从而提高覆盖语法错误的覆盖率。通过整合多个模型,并结合N-gram语言模型并通过重新打分来编辑特征,我们的新方法成为第一个神经网络方法,在语法方面都胜过了当前基于统计机器翻译的最新方法和效率。
随着全球非母语学习者和英语写作者的增多,改进诸如纠错系统之类的创作工具的必要性也在增加。语法错误纠正(GEC)是一项公认的自然语言处理(NLP)任务,用于处理自动纠正书面文本(尤其是非本地书面文本)中的错误的构建系统。 GEC系统尝试纠正的错误不仅限于语法错误,还包括拼写和固定搭配错误。
最近,英语的GEC在NLP社区中引起了很多关注。基于短语的统计机器翻译(SMT)方法已成为该任务的最新方法(Chollampatt和Ng 2017; Junczys-Dowmunt和Grundkiewicz 2016),其中GEC被视为翻译从“bad”英语语言到“good”英语语言的任务。使用并行纠错语料库(包含错误的源文本及其相应的正确目标文本)来学习翻译模型。神经网络(NN)模型已被用作改善SMT方法通用性的功能(Chollampatt,Taghipour和Ng 2016),SMT在有效访问全局源和目标上下文方面仍然有局限。在解码过程中将单词和短语视为离散实体也限制了其泛化能力。为此,提出了几种用于该任务的神经编码器-解码器方法(Xie等,2016; Yuan和Briscoe,2016; Ji等,2017; Schmaltz等,2017)。但是它们的性能仍然大大落后于最新的SMT方法。
用于GEC的所有先前神经方法都依赖于使用递归神经网络(RNN)。与以前的神经网络方法相比,我们对GEC的神经方法基于完全卷积的编码器-解码器体系结构,具有多个卷积层和注意力层(Gehring等人2017)。我们的分析表明,卷积神经网络(CNN)可以比RNN更有效地捕获局部上下文,因为卷积操作是在较小的单词序列窗口上执行的。大多数语法错误通常是局部的,并且仅取决于附近的单词。卷积的多层层次结构和注意力机制也可以捕获不同单词之间的广泛上下文和交互作用,该注意力机制会根据源单词在预测目标单词中的相关性来对源单词进行加权。此外,无论输入长度如何,仅对输入执行固定数目的非线性操作,而在RNN中,非线性数目与输入的长度成正比,从而减少了远处单词的影响。
我们通过集成多个模型进一步提高了性能。与先前的神经方法相反,我们使用一种更简单的预处理方法来缓解未知词问题(Sennrich,Haddow和Birch 2016)。使用字节对编码(BPE)算法将稀少的字分成多个频繁的子字。现有神经方法的主要弱点之一是它们不具有特定任务的功能,也没有利用大型的本地英语语料库来取得良好的效果。我们在编码器-解码器模型中使用此类英语语料库来预训练要用于初始化编码器和解码器中的嵌入的单词向量。我们还训练了一个N-gram语言模型作为feature和编辑数作为feature,从而产生更好的整体输出。
总而言之,本文做出了以下贡献:(1)我们成功地采用了基于BPE令牌训练的卷积编码器-解码器模型作为我们的主要模型,以实现GEC的最新性能。 我们的工作是端到端GEC使用全卷积神经网络的第一项工作。 (2)我们利用较大的英语语料库对单词嵌入进行预训练,并训练一个N-gram语言模型,以用作Rescorer中的功能,该模型被训练为使用最小错误率训练来优化目标指标(Och 2003 )。(3)我们对典型的循环体系结构和模型中的注意力机制进行了比较,并进行了错误类型性能分析,以确定我们的方法在当前最先进的SMT方法上的优势。
二、相关工作
在进行了CoNLL-2014共享任务(Ng等人,2014)之后,GEC在NLP社区中引起了很多关注。共同的任务是纠正英语论文中的所有语法错误。从那时起,用于共享任务的测试集已用于基准GEC系统。由于统计机器翻译能够纠正各种类型的错误和复杂的错误模式,因此已成为最先进的方法(Chollampatt和Ng,2017),而以前的方法则依赖于构建错误类型特定的分类器( Dahlmeier,Ng和Ng 2012; Rozovskaya等人,2014)。 SMT框架的主要优势在于它具有合并大型纠错的并行语料库的能力,例如公开提供的Lang-8语料库(Mizumoto等人,2011年),用于训练健壮语言模型(LM)的附加英语语料库,特定任务特征(Junczys-Dowmunt和Grundkiewicz 2016)和神经模型(Chollampatt,Taghipour和Ng 2016)。但是,与神经方法相比,基于SMT的系统的通用能力有限,并且无法有效地访问更长的源和目标上下文。为了解决这些问题,GEC提出了几种基于RNN的神经编码器/解码器方法。
GEC的神经编解码器方法
Yuan和Briscoe(2016)首先应用了一种流行的神经机器翻译模型RNNSearch(Bahdanau,Cho和Bengio,2015年),该模型由双向RNN编码器和基于注意力的RNN解码器组成。他们还使用了无监督词对齐模型和词级统计翻译模型来替换输出中的未知词。但是,他们使用来自专业注释的非公开Cambridge Learner Corpus 语料库(CLC)的1,900万个句子对,对系统进行了训练,从而使其模型难以复制和比较。
Xie et al. (2016) 提出了在GEC中使用字符级循环编码器/解码器网络。他们在公开可用的NUCLE(Dahlmeier,Ng和Wu 2013)和Lang-8语料库上训练了模型,并提供了常见错误类型的综合示例。他们还结合了解码期间在Common Crawl语料库的一小部分(2.2B N-gram)上训练的N-gram LM,在CoNLL-2014测试集上获得39.97的F0.5分数。他们还使用了字符和单词级编辑操作的监督编辑分类器,以及经过预训练的单词嵌入功能,以消除虚假编辑并使F0.5得分提高至40.56。
Ji et al. (2017)在(Luong and Manning 2016)的混合机器翻译模型的基础上,通过在单词和字符级别添加嵌套的注意力级别,提出了一种混合单词-字符模型。与 (Yuan and Briscoe 2016)类似,他们在Lang-8和NUCLE之外还使用了非公开CLC语料库进行训练,结果产生了260万个句子对。通过在评分步骤中进一步添加用于(Junczys-Dowmunt和Grundkiewicz 2016)的网络级Common Crawl LM,他们在CoNLL-2014测试集上获得了F0.5分数45.15。他们的rescorer通过使用固定步长的简单网格搜索进行训练,以获得特征权重,并且未使用特定任务的特征,而我们使用最小错误率训练(Och 2003)来找到最佳特征权重,并使用编辑操作特征和LM特征。
最近,Schmaltz et al. (2017) 在Lang-8和NUCLE(1.4M句子对)上训练的单词级双向LSTM网络,并在目标句子中标记了特殊标签的编辑操作(插入,删除和替换)。他们的未调整模型和未标记编辑操作标签的基线仍然产生了高精度和低召回率。但是,当他们使用最大化F0.5的网格搜索调整编辑操作的权重时,他们的召回率上升了。在不使用任何其他模型或语料库的情况下,他们的方法在CoNLL-2014测试集中获得了F0.5分数41.37。我们的建模方法是通过计数操作和使用它们作为权重特征。
三、多层卷积编解码器神经网络
编码器/解码器模型最广泛地用于从源语言到目标语言的机器翻译。同样,可以将编码器-解码器模型用于GEC,其中编码器网络用于在向量空间中对潜在错误的源语句进行编码,而解码器网络则通过使用源编码来生成校正后的输出语句。注意力机制(Bahdanau,Cho和Bengio,2015年)在解码期间选择性地对源语句的不同部分进行加权,从而在每个解码时间步长对源语句进行不同的解码。我们基于具有多层卷积和注意力机制的编码器-解码器架构来构建模型,类似于其在MT。模型将稀有词划分为子词(Sennrich,Haddow和Birch 2016)训练。
模型
假设输入源句子S, 使用m个源token s1, . . . , sm ,并且si∈Vs,其中Vs是源词汇表。最后一个源令牌sm是特殊的句子结尾标记令牌。源令牌嵌入在连续空间中,如s1, . . . , sm.。嵌入si∈Rd由si = w(si) + p(i)给出,其中w(si)是词embedding,p(i)是与源句中的令牌si的位置i对应的位置嵌入。 两种嵌入都是从嵌入矩阵和网络的其他参数一起获得的。
编码器和解码器分别由L层组成。该网络的体系结构如图1所示。
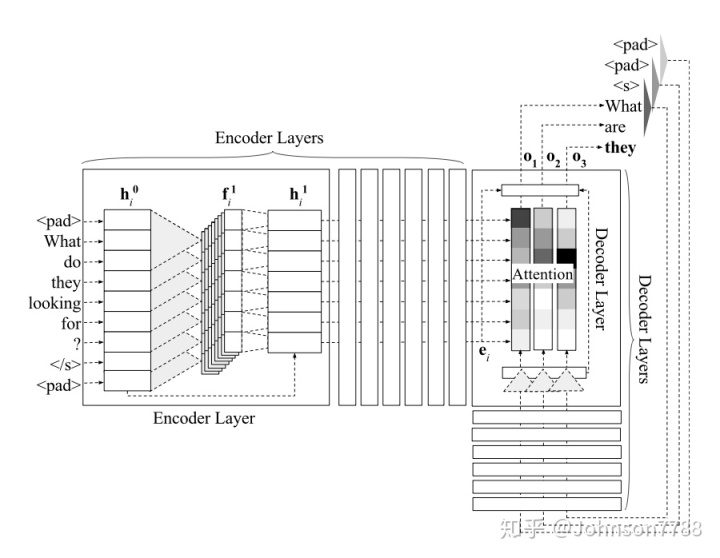
源令牌嵌入s1, . . . , sm, 通过线性映射以获得第一个编码器层的输入矢量。h是其中所有编码器和解码器层h0的输入和输出尺寸。线性映射是通过将权重W∈Rh×d乘以向量并加上偏差b∈Rh来完成的:
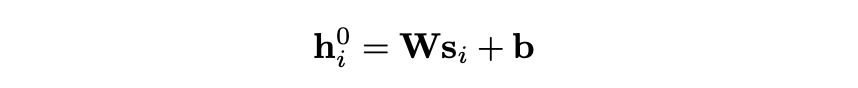
在第一个编码器层中,维度为3×h的2h卷积滤波器,每个序列映射三个连续输入i∈R2h的序列。在源语句的开头和结尾处添加填充(在图1中表示为 <pad>),以在卷积操作之后保留与源令牌相同数量的输出矢量。
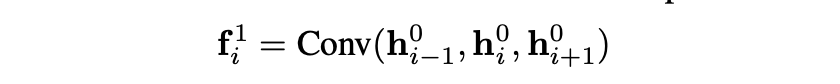
其中Conv(·)表示卷积运算。 接下来是使用门控线性单位(GLU)的非线性:
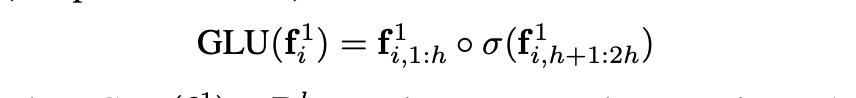
其中GLU, o表示元素乘,最后将编码器层的输入向量作为残差连接。第l编码器层的输出向量为:
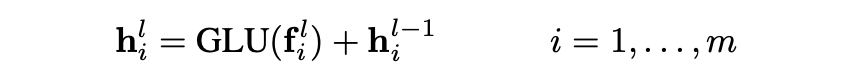
最后输出层用线性映射:

现在考虑解码阶段的第n时间步,在上一个单词n-1提供的情况下,生成目标单词tn,解码阶段,最开始需要做padding,句子开始marker和先前生成的token这两个填充被嵌入为t-2,t-1,t0,t1,...tn-1的计算方法与源令牌嵌入相同。 每个嵌入的t并作为输入传递到第一个线性映射到g0的解码器层。 在每个解码器层中,对前一个解码器层的输出矢量g执行卷积运算,然后进行非线性运算,其中j = 1 ..., n:
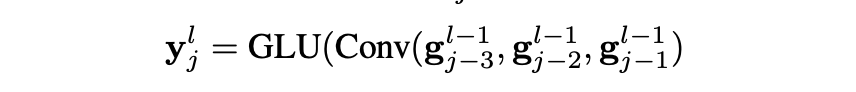
其中Conv(·)和GLU(·)分别表示卷积和非线性,ylj在第l个解码器层的第j个时间步变为解码器状态。 卷积滤波器的数量和大小与编码器中的相同。
每个解码器层都有自己的注意力模块。 为了在第n个时间步预测目标令牌之前在第l层计算注意力,解码器状态yn∈Rh线性映射到权重Wz∈Rd×h且偏差bz∈Rd的d维向量,将先前目标令牌的嵌入:
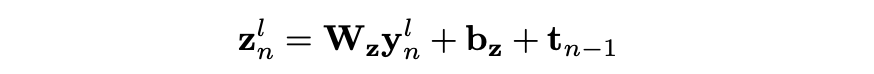
注意力权重α通过编码器输出矢量e1,...,e和znl的点积来计算, 并通过softmax进行归一化:
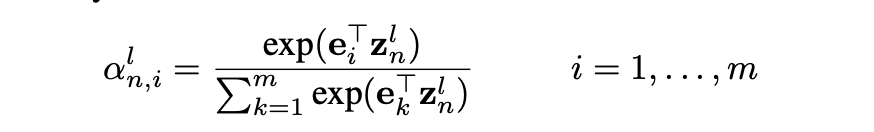
通过将注意力权重应用于编码器输出向量和源嵌入的总和来计算源上下文向量xln。 源嵌入的加入有助于更好地保留有关源令牌的信息。

xnl 然后通过线性映射到cnl, 解码器输出向量l,gnl是cnl和ynl和上一层输出向量gn(l-1)的和:
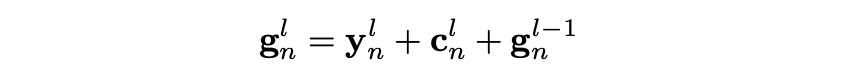
最终解码器层输出向量gnl经过线性映射到dn,然后添加Dropout,输出向量映射到单词表维度大小,然后经过softmax计算目标单词的概率
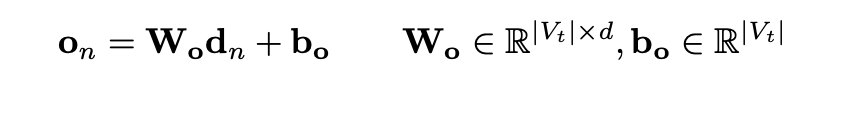
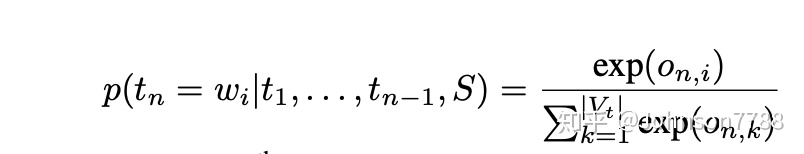
wi表示单词表V中的第i个单词。
词嵌入的预训练
我们使用从大型英语语料库中学到的预训练词向量,来初始化源和目标词的词向量。 由于我们对用于训练网络的并行语料库进行了类似的预处理,因此该英语语料库中的稀有词被分为基于BPE的子词单元。 单词嵌入的计算方法是,将单词表示为多个N-gram的字符,然后使用fastText工具将这些n-gram字符序列的skipgram嵌入进行求和。 这些嵌入具有有关词的基本形态的信息,并且根据经验发现,与随机初始化网络或使用word2vec嵌入(将词视为单独的实体并且不了解字符序列的信息)相比,其性能要好。
训练
使用负的对数似然损失函数训练模型:
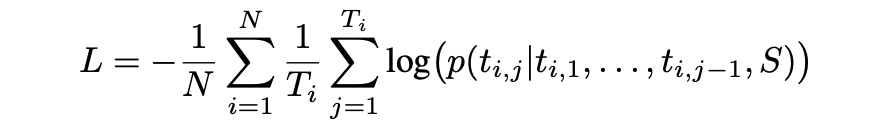
其中N是batch中训练样本的数量,Ti是第i个参考语句中token的数量,ti,j是第i个训练实例的参考校正中的第j个目标单词。使用简化了Nesterov的动量公式的NAG优化器优化参数。
解码
编码器-解码器模型在给定错误源句S的情况下估计目标词的概率。目标词的最佳顺序是通过从左到右的beam search获得的。在beam search中,保留每个解码时间步长前b个可能的候选对象。搜索结束时beam中得分最高的候选者将是校正假设单词。假设的模型得分是网络计算的假设词的对数概率之和。我们还通过对多个模型集成的结果预测求均值,以便计算候选词的对数概率得分。用于集成的模型具有相同的体系结构,但使用不同的随机初始化进行训练。
Rescoring 打分
为了合并特定于任务的特征和大型语言模型,我们使用对数线性框架对最终的候选beam进行重新评分。源句子S的校正假设句子T的分数由下式给出:
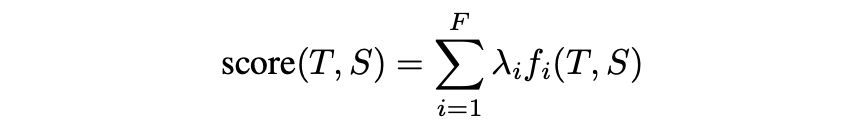
其中,λi和fi分别是第i个特征权重和特征函数,F是特征数。特征权重是通过对开发集进行最小错误率训练(MERT)来计算得到的。除了假设的模型得分外,我们还使用以下几组特征进行评分:
- 编辑操作(EO)特征:三个特征表示token-level的替换,删除和在源语句与假设语句之间的插入次数。
2.语言模型(LM)特征:两个特征,即5-gram语言模型得分(即假设句子中5-gram的对数概率之和)和假设中的单词数。与最先进的方法类似,语言模型在Webscale的Common Crawl语料库上进行训练。
四、实验装置
数据集我们使用先前使用的两个公共数据集Lang-8(Mizumoto等,2011)和NUCLE(Dahlmeier,Ng和Wu 2013)来创建并行数据。与NUCLE中的句子对一起,我们通过选择由英语学习者撰写的论文并使用语言识别工具,从其中删除非英语句子,来提取和使用Lang-8中的英语句子对。在目标侧不变的句子对将从训练集中删除。该数据的一个子集(来自NUCLE的5.4K句子对)被取出用作模型选择和训练的开发数据。用于训练编码器-解码器NN的剩余并行数据由130万个句子对(1805万个源词和2153万个目标词)组成。我们还利用来自Wikipedia的更大的英语语料库(1.78B个单词)来预训练单词嵌入,并使用Common Crawl语料库的一个子集(94B个单词)来训练语言模型进行评分。领先的GEC系统已经使用了来自Common Crawl的类似大小的语料库。
评价
我们的评估设置与CoNLL2014共享任务中的评估设置相同。我们评估模型并将其与官方CoNLL-2014测试集上的先前系统进行比较,并使用通过MaxMatch评分器计算得出的F0.5评分。在先前的工作之后,我们分析了神经模型的选择,并在CoNLL-2013共享任务测试集上进行了消融研究。
我们还在最近发布的JFLEG开发和测试集(Napoles,Sakaguchi和Tetreault 2017)上评估了模型输出的流畅性,其中对基于母语的学习者编写的句子进行了基于流畅性的重写,以使句子听起来自然,并且没有错误。当未提供error-span和error-type注释时,GLEU度量标准可用于评估已校正文本的流畅性(Napoles等人,2015)。 我们还使用JFLEG数据集发布的脚本自动提取了注释范围后,计算了F0.5分数。
模型和训练细节
我们扩展了基于PyTorch的公开实现,以训练使用预训练嵌入初始化的多层卷积模型。源嵌入和目标嵌入均为500维。源词汇表和目标词汇表分别由来自,并行数据源端和目标端的30K最频繁的BPE令牌组成。使用fastText在Wikipedia语料库上进行一次预训练,使用窗口大小为5的skip-gram模型进行一次训练。字符N-gram序列的大小在3到6之间(包括两者),用于计算单词嵌入, 其他参数保持默认值。在训练编码器-解码器NN期间,嵌入被更新。每个编码器和解码器由七个卷积层组成,卷积窗口宽度为3。编码器和解码器中的层数是基于对5、7和9层进行试验后的开发集性能来设置的。每个编码器和解码器层的输出为1024维。概率为0.2的Dropout应用于嵌入,卷积层和解码器输出。我们在3个NVIDIA Titan X GPU上同时训练每个模型,每个GPU上的批处理大小为32,并在每个epoch之后在另一个NVIDIA Titan X GPU上同时执行验证。学习速率为0.25,学习速率annealing因子为0.1,动量为0.99。我们使用早停功能,并根据开发集上的F0.5分数选择最佳模型。训练单个模型大约需要18个小时。在解码期间,使用的beam宽度为12。
基准线
我们将我们的系统与用于GEC的所有现有神经方法和两个最先进的(SOTA)系统进行了比较。第一个SOTA系统(Junczys-Dowmunt和Grundkiewicz,2016年)采用了具有任务特定功能的词级SMT方法和在Common Crawl语料库上训练的网络级LM。第二个SOTA系统(Chollampatt和Ng,2017年)向具有任务特定功能和网络级LM的单词级SMT系统添加了自适应神经网络联合模型(NNJM),并通过使用字符集进行拼写错误校正来进一步改进级SMT系统。为了在不使用其他英语语料库的情况下,将我们的神经方法与SMT方法进行比较,我们使用已发布的SOTA系统模型(Chollampatt和Ng 2017)创建了两个基准。 第一个(表1中的SMT + NNJM)是在删除所有使用附加英语语料库的辅助模型(例如单词类LM和网络级Common Crawl LM)之后重新调整的基于单词级SMT的系统。 该系统具有经过调整的NNJM和操作序列模型(OSM),均在并行数据上训练,并且在并行数据的目标侧上训练了单个LM。 通过进一步删除适应的NNJM并重新调整我们的开发集,来创建另一个非神经SMT基线(表1中的SMT)。
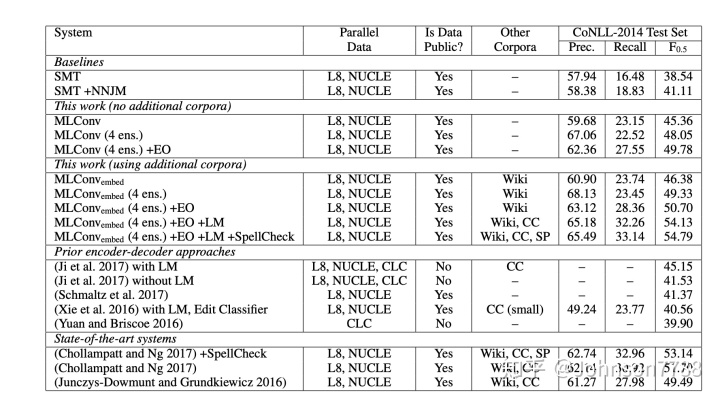
表1:CoNLL-2014测试集的结果。 对于单个模型(MLConv和MLConvembed),报告了4个模型的平均精度,召回率和F0.5(使用不同的随机初始化进行训练)。 (4 ens)是指这4个模型的整体解码。 + EO和+ LM分别表示使用编辑操作和语言模型功能进行重新评分。 + SpellCheck表示增加了(Chollampatt和Ng 2017)中提出的公开可用的拼写检查器。 L8指Lang-8语料库,CC指Common Crawl,CLC指非公开的Cambridge Learner语料库,SP指拼写错误的语料库。 与其余的(94B – 97B个字)相比,(Xie等人,2016年)使用了较小的CC(2.2B个字)子集。
五、实验与结果
基准语料库的评估
我们根据输出句子的语法和流利程度来评估我们的系统。
语法性
我们首先根据CoNLL-2014测试数据(表1)评估系统的不同变体。我们的单一模型无需使用任何其他语料库或评分(MLConv),即可达到45.36 F0.5。在整合了四个模型(4 ens)之后,性能达到了48.05 F0.5,并且比之前没有LM的最佳的神经模型(Ji等人2017)(41.53 F0.5)的表现大幅度提高了6.52 F0.5,尽管后者使用更多的训练数据,包括非公开CLC。我们的神经系统也大大优于两个可比较的SMT基准,即“ SMT”和“ SMT + NNJM”。当使用编辑操作(+ EO)特征执行重新评分时,性能将达到49.78 F0.5,优于使用任务特定特征和网络功能的强大的基于SMT的系统(Junczys-Dowmunt和Grundkiewicz 2016)。缩放Common Crawl语言模型。另一方面,我们的系统无需使用任何其他英语语料库或经过预训练的单词嵌入,即可达到这一性能水平。当我们通过使用预先训练的fastText词嵌入(MLConvembed)进行初始化来训练模型,使用四个模型的集合进行解码,并使用编辑操作功能进行重新评分时,性能将达到50.70 F0.5。
在将web-scale的LM添加到评分(+ LM)后,我们的方法达到了54.13 F0.5,胜过了(Chollampatt and Ng 2017)(F0.5 = 53.14)之前最好的发布结果,该结果还使用了经过训练的拼写校正组件在拼写语料库上。这种改善是显着的(p <0.001)。当我们使用(Chollampatt and Ng 2017)(+ SpellCheck)中的拼写校正组件时,我们的性能达到了54.79,与先前发布的最佳结果相比,具有意义的1.65 F0.5(p <0.001)显着改善,并建立了英语GEC的最新技术。所有统计显着性检验均使用符号测试和bootstrap重采样对100个样品进行。
流利度
我们还测量了JFLEG开发和测试集的输出效率(表2)。
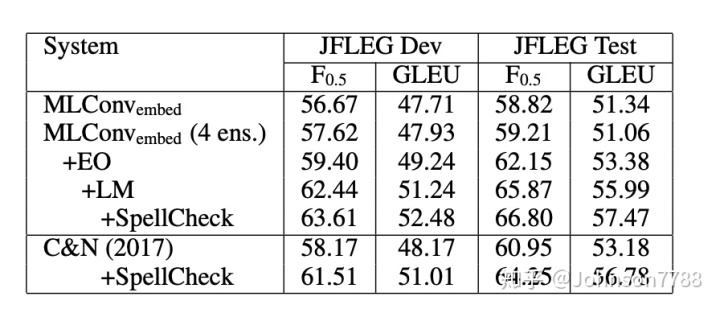
我们的系统具有使用编辑操作特征进行评分的功能,在数据集和指标方面均无需进行拼写检查(Chollampatt和Ng 2017),其性能优于web-scale的LM。这无需在我们的系统中添加网络级LM。添加网络级LM并使用拼写检查器后,我们的方法在这些数据集上获得了报告的最佳GLEU和F0.5分数。值得注意的是,我们的模型无需调整JFLEG开发集即可达到这一性能水平。
编码器和解码器架构
我们无需使用CoNLL-2013测试集上的预训练词嵌入功能即可分析各种网络体系结构的性能(表3)。
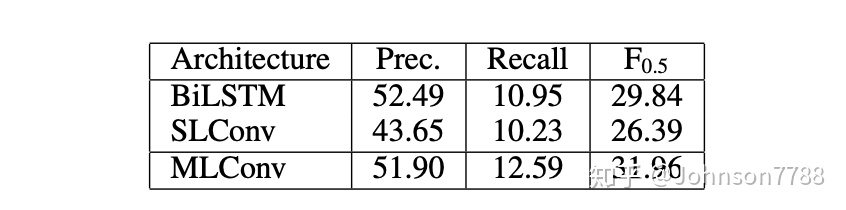
我们尝试在编码器中使用双向LSTM,并使用具有soft注意力机制的注意力LSTM解码器(Bahdanau,Cho和Bengio 2015)(表3中的BiLSTM),并将其与单层卷积(SLConv)以及我们的提出了多层卷积(MLConv)编码器和解码器模型。 BiLSTM可以捕获每个输入单词从左到右的整个句子上下文,而SLConv只能捕获几个周围的单词(等于3的过滤宽度)。但是,MLConv可以更有效地捕获更大的周围环境(7层×过滤器宽度3 = 21个标记),从而使其表现优于SLConv和BiLSTM。
有趣的是,BiLSTM模型比MLConv模型具有更高的精度,尽管其召回率较低。我们从CoNLL-2013测试集中的一个例句中分析了两个模型的注意力权重(图2)。
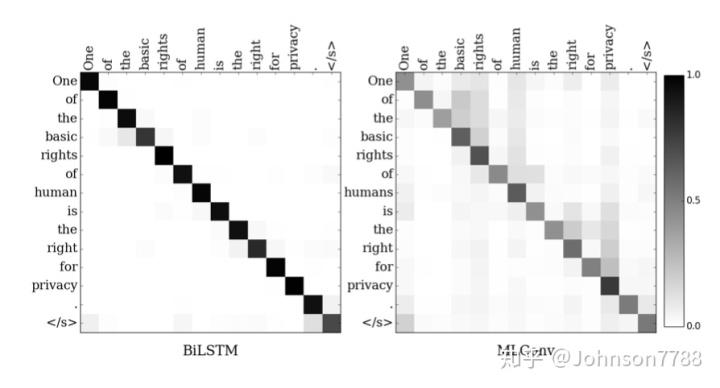
MLConv模型显示的注意权重是所有解码器层的平均注意权重。可以看出,与MLConv相比,BiLSTM产生了更清晰的分布,从而在匹配的源词上赋予了更高的权重,而MLConv也在周围的上下文词上赋予了明显的概率。我们在尝试的所有其他示例中都观察到了这种趋势。这可能是导致BiLSTM频繁输出源字词的原因,导致提出的更正次数更少,因此精度更高。该分析证明了MLConv更好地捕获上下文的能力,因此比复制源单词更有利于进行更正。
使用预训练的嵌入进行初始化
我们评估初始化源词和目标词嵌入的各种方法。表4显示了随机初始化嵌入以及在CoNLL-2013测试集中使用word2vec和fastText初始化嵌入的结果。

我们使用word2vec训练skip-gram模型,并使用与fastText相同的参数。 fastText嵌入可以访问组成单词的字符序列,因此更适合于学习形态学的单词表示形式。我们还发现,使用fastText进行初始化在经验上效果很好,因此,在对基准测试数据集进行评估时,我们选择这些嵌入来初始化网络。
分析与讨论
我们使用最新发布的ERRANT工具包(Bryant,Felice和Briscoe 2017),基于F0.5对CoNLL2014测试执行我们的系统,与最新技术(SOTA)系统(Chollampatt和Ng 2017)的特定于错误类型的性能比较。 ERRANT依靠基于规则的框架,来识别GEC系统提出的更正的错误类型。四种常见错误类型的结果如图3所示。
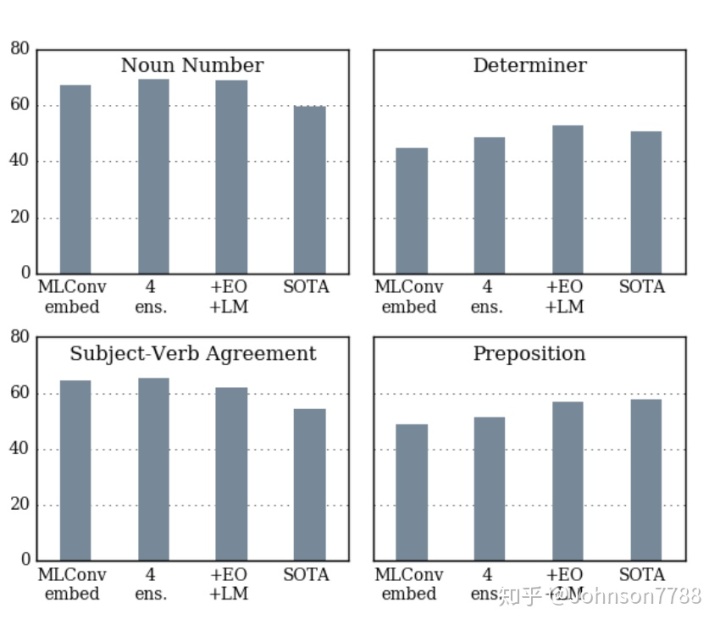
我们发现,带有Rescorer(+ EO + LM)的集成模型在介词错误上表现出优势,并且在名词数,确定词和主语动词错误方面优于SOTA系统。基于SMT的系统的缺点之一,在于主语-动词一致性错误的纠正,因为动词及其主语在源句中可能相距很远。另一方面,就主语动词一致性错误而言,即使是我们没有模型的单一模型(MLConvembed)也优于基于SOTA SMT的系统,因为它可以通过全局关注机制访问整个源上下文,并且可以更长的目标解码器中的多层卷积实现上下文。
从我们的分析中我们发现,与RNN相比,卷积编码解码器NN可以更有效地捕获上下文并获得出色的结果。但是,RNN可以提供更高的精度,因此将来可以研究这两种方法的组合。先前已经显示,改进的语言建模可以显着提高GEC性能。我们将留待将来的工作来探索在beam search过程中网络级LM的集成,以及将神经LM融合到网络中。我们还发现,一种简单的预处理方法可以将稀有词分割为子词,从而有效地解决了GEC的稀有词问题,并且其性能优于字符级模型和复杂的字符模型。
六、结论
我们将多层卷积编码器/解码器神经网络用于语法错误纠正,与所有先前的编码器-解码器神经网络方法相比,其性能均得到了显着提高。我们利用大型英语语料库对单词嵌入进行预训练和初始化,并训练语言模型以重新评估候选者的更正。在记录过程中,我们还使用了编辑操作功能。通过整合多个神经模型并进行记录,我们的新方法在CoNLL-2014和JFLEG数据集上均实现了改进的性能,明显优于当前领先的基于SMT的系统。因此,我们已经完全弥补了以前在神经和统计方法之间存在的巨大性能差距。本文使用的源代码和模型文件可从https://github.com/nusnlp/mlconvgec2018获得。















 378
378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









