











第一届自然语言生成与智能写作技术评测 任务四:中文句法错误检测技术评测 暨第七届中文句法错误检测技术评测(CGED-7) (cipsc.org.cn)
NLPTEA-2017 CGED-4 比赛第一名,阿里巴巴,在上图中的1,2,3个level中夺冠
1.Alibaba at IJCNLP-2017 Task 1: Embedding Grammatical Features into
LSTMs for Chinese Grammatical Error Diagnosis Task
相关介绍:http://www.sohu.com/a/206342111_473283
NLPTEA-2018 CGED-5 比赛第一名,哈尔滨工业大学与科大讯飞联合实验室
2.Chinese Grammatical Error Diagnosis using Statistical and Prior
Knowledge driven Features with Probabilistic Ensemble Enhancement
NLPTEA-2020 CGED-6 比赛第一名,科大讯飞
3. Combining ResNet and Transformer for Chinese Grammatical Error Diagnosis
相关介绍:第六届中文语法错误诊断大赛,哈工大讯飞联合实验室再获多项冠军_批改
网易有道,在top3 correction这个指标上获得第一
相关介绍:通关英语,再战中文,网易有道AI团队首战中文语法错误诊断大赛夺冠_纠错
1. 中文语法纠错的动机
学汉语的人越来越多,帮助学生学习,缓解老师压力。
2. 处理的任务
语病识别(侦测层:识别段落单元是否包含错误)、语病分类(识别层:识别错误点的错误类型)、语病定位(定位定:识别错误点的错误类型和位置)、语病修正(修正层:对缺词和错词提供修正的建议)。
其中,错误类型有四种,少词,多词,用词错误,词序错误,2018,2020的语法纠错任务相比2017多了语病修正的模块,对于缺词和错词,需提供修正的建议。具体的错误样本数据见下图。

训练数据以如下SGML格式给出:

3. 方法
第二篇论文在第一篇论文的基础上做了一些改进
(1)引入一些新的语言学特征(先验知识)
(2)概率集成方法(集成多个Bi-LSTM + CRF模型)
(3)模板匹配用于后处理
前三个任务,检测,识别,定位使用了Bi-LSTM + CRF 序列标注模型同时来做,这里的Bi-LSTM + CRF 是基于字的。模型的整体框架见下图,正确的句子为“锻炼能力”,使用的是BIO标注,B表示错误的开始,I 表示错误的内部,O表示错误的外部,S代表用词错误这一语法错误类别(M,S,R,W):

BiLSTM+CRF的前向的过程得到发射矩阵,即每个位置对应的的标签的概率。后向过程以及维特比解码过程,更新所有参数包括转移矩阵,bilstm的参数,以及随机初始化的输入特征对应的参数。 2017年阿里的论文中该模型用到的特征见下图:

(1)字嵌入向量 ,随机初始化得到的
(2)二元字向量的组合
(3)词性标注向量 ,由该字所在的词的词性决定 ,同时会标注该字是词的开始B,还是内部 I
(4)词性的得分,从大的语料中统计得到 。因为有的词既可以做名词又可以做动词,哪个词性比较常见,得分就比较高。
(5)所在的词和上一个词,下一个词的PMI互信息得分
(6)依存特征
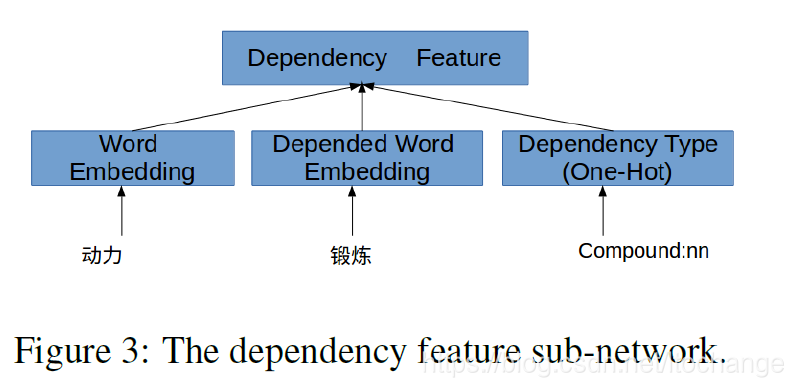
2018的篇论文多加了三个特征
(7)分词信息,例如这里的加的特征是B-word(动力),表示当前输入的字是"动力"这个词的开始。
(8)高斯ePMI, 使用可训练的加权高斯分布来利用单词的距离。 这个不是特别理解,只知道ePMI 不再是统计相邻单词的互信息,而是计算wi和wj距离为j-i的互信息,放个论文截图。

(9)带词性的PMI,不同词性的的词语对,即使互信息相同,也有不同的意义
假设有三个词 A B C, B2是词B中的字,假设B的词性是n,A的词性是v,C的词性是d,根据下图的方法构造B2的特征,合并相邻的带词性的互信息作为一个特征。
![]()
论文中用的一些集成方法:
2017的论文:因为在模型的训练过程中有权重参数的随机初始化,dropout的随机初始化,数据每个batch的训练顺序,模型训练好后存在差异。
(1)直接merg每个模型的结果。R值上升,P值下降很多。
(2)针对方法(1)做了一些优化,将每个Bi-LSTM+CRF模型得到的后20%的结果删除(模型认为有错的概率排序)。提高了P值但是仍然没有超过的单个的模型。
(3)投票,论文中集成了三个模型,得到了最好的F1值。
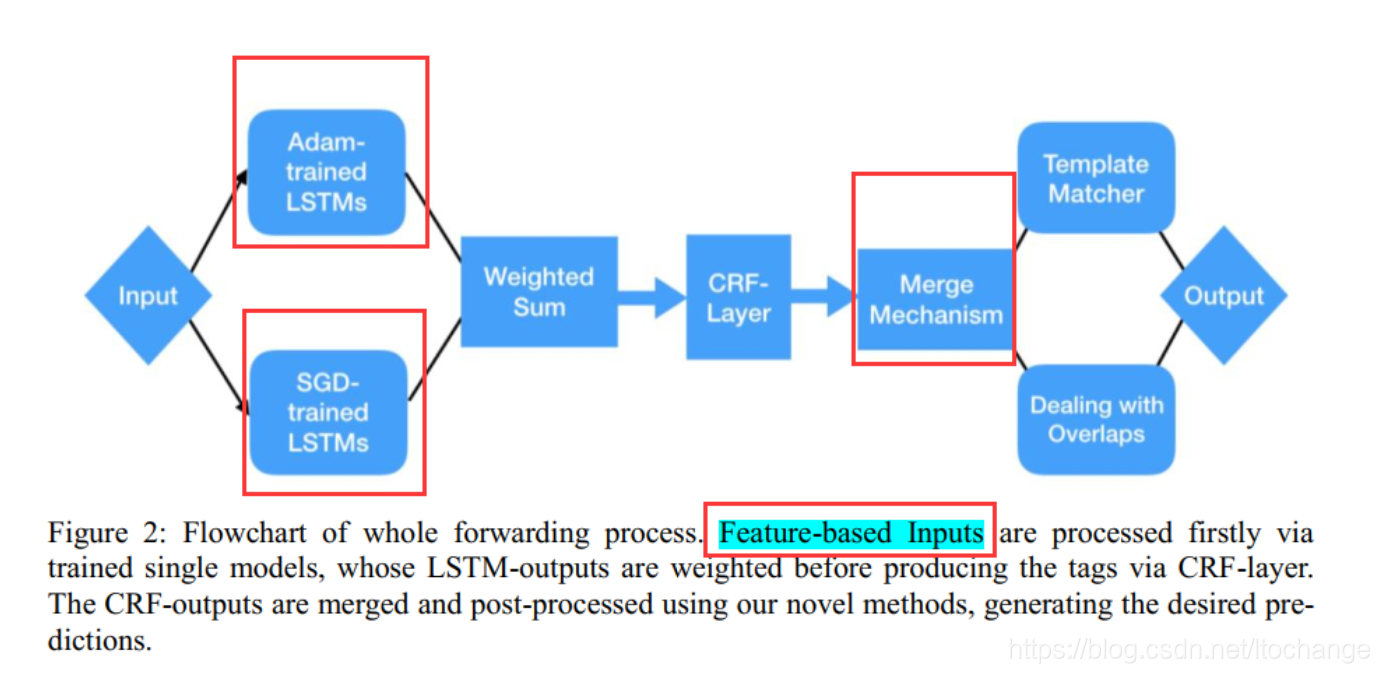
2018的论文做了一些改进,提出了两种集成策略:
(4)基于概率的集成方法,对于每个LSTM模型(超参数可能不一样)的输出,加权求平均,再作为CRF层的输入。
假设有n个模型:
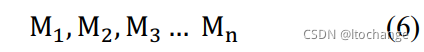
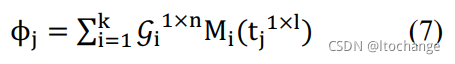
(5)基于ranking的方法。通过实验发现使用Adam的优化方法的模型比使用SGD的优化方法在recall指标上表现比较好,但是直接merger adam 优化的模型,会使得p值较差。将每个Bi-LSTM+CRF模型得到的前40%结果保存下来。 去掉后20%结果的模型。
2018论文的模型整体架构图:
语病修正(对缺词和错词错误进行纠正):参赛系统采取了端到端的神经网络模型与词汇点互信息相结合,将语病位置空出,根据上下文以及语病信息对于该位置正确的词汇进行推测。
(1)ePMI排序
(2)seq2seq + attention
比如说存在名词错误,把这个位置空出进行decoder(需要用到前面的位置识别的结果吗?),生成正确的?decoder 部分不会引入很多错误嘛? ePMI是产生候选词吗?还有些不太懂的地方。
论文 Combining ResNet and Transformer for Chinese Grammatical Error Diagnosis:
在检测任务中,提出了ResBERT模型,在BERT模型基础上融入残差网络,增强输出层中每个输入字的信息,使模型可以更好地检测语法错误位置。从下图可以看出,是把embedding的信息直接作为输出层的一部分输入,然后再【CLS】位置进行是否有错二分类。
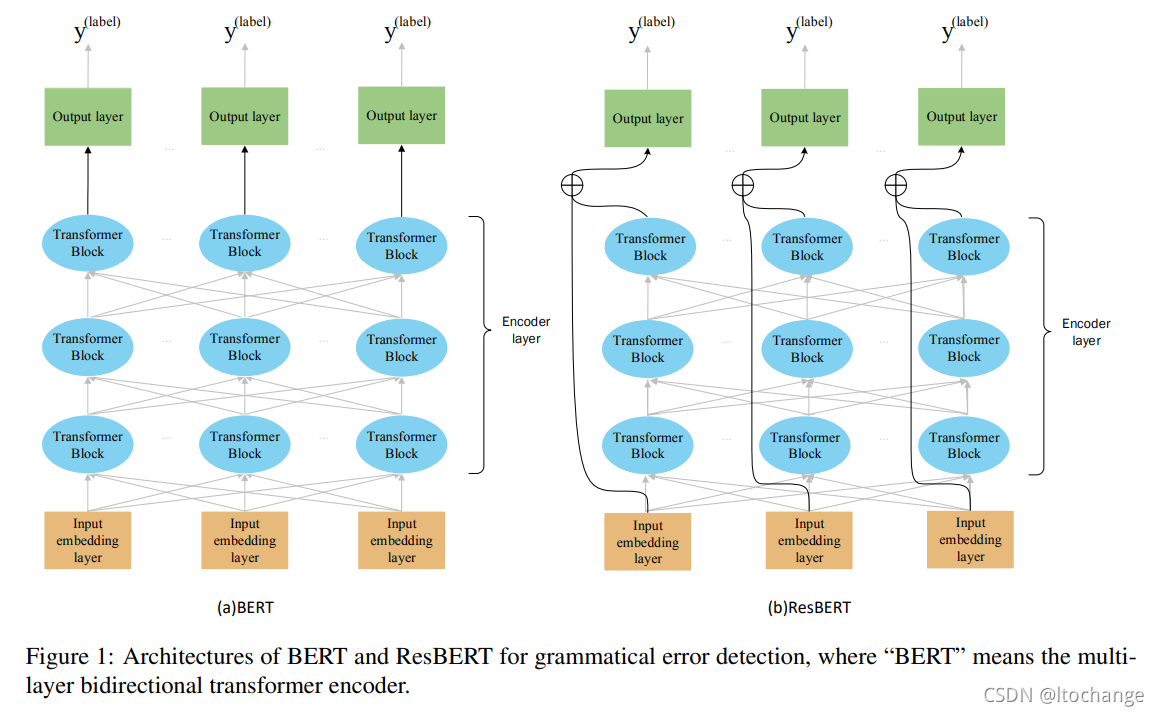
在修正任务中,由于序列标注模型无法直接给出语法错误的修正结果。
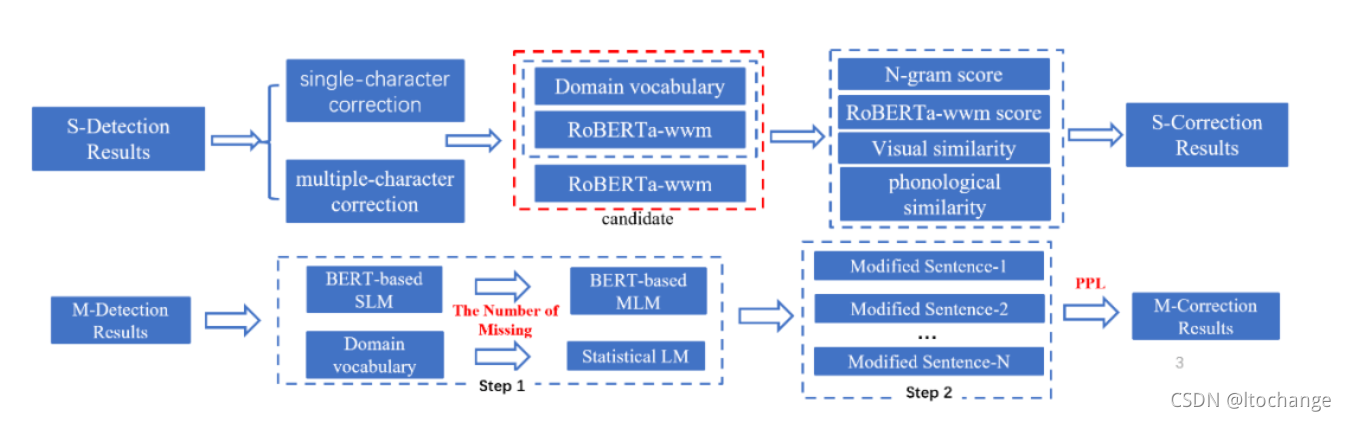
针对用词不当错误,使用RoBERTa模型选取候选字,然后再综合考虑字音、字形相似度以及语言模型打分来选出最终的修正结果。
针对缺失错误,首先预测缺失位置缺失的字数,然后再使用BERT语言模型生成修正候选结果,最后通过比较多个候选修正句子的困惑度来确定缺失修正结果。
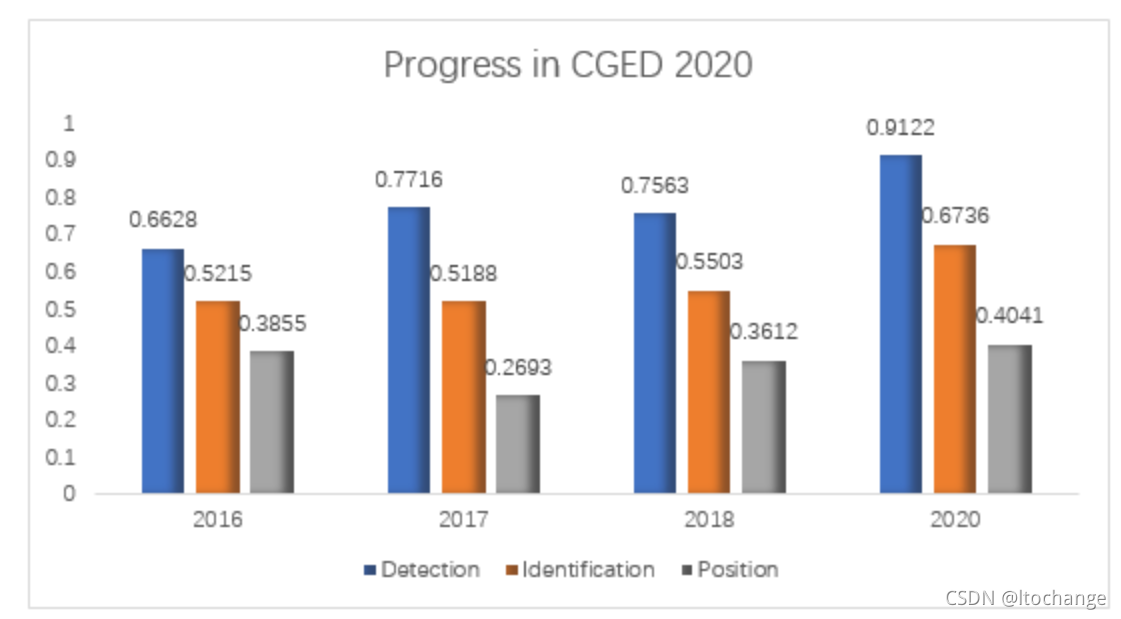
近几年的中文语法纠错的发展:
中文语法纠错的任务比较难,指标也不高。如果只关注错别字的纠正(中文拼写纠错),可以关注中文错别字纠正调研(2021更新) · Haibin's Studio
比赛综述文章:
IJCNLP-2017 Task 1: Chinese Grammatical Error Diagnosis
Overview of NLPTEA-2018 Share Task Chinese Grammatical Error Diagnosis
Overview of NLPTEA-2020 Shared Task for Chinese Grammatical Error Diagnosis


















 5469
5469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











