






断断续续花了两周时间学习了相关性分析这部分内容,今天来记录一下学习过程。
先说一下这两周的一些心得吧。首先,要保持学习的连贯性,每天多多少少都要抽出时间敲代码,几天不练,明显感觉到手生。然后呢,熟能生巧,“泰坦尼克号生存率预测”的案例我练习了六次,一次比一次熟练,也理解得越来越透彻。
下面是我用“女性服装电子商务评论”这个数据集进行相关性分析的过程。
女性服装电子商务评论分析tianchi.aliyun.com开始分析之前,我先用思维导图梳理了一个思路框架。
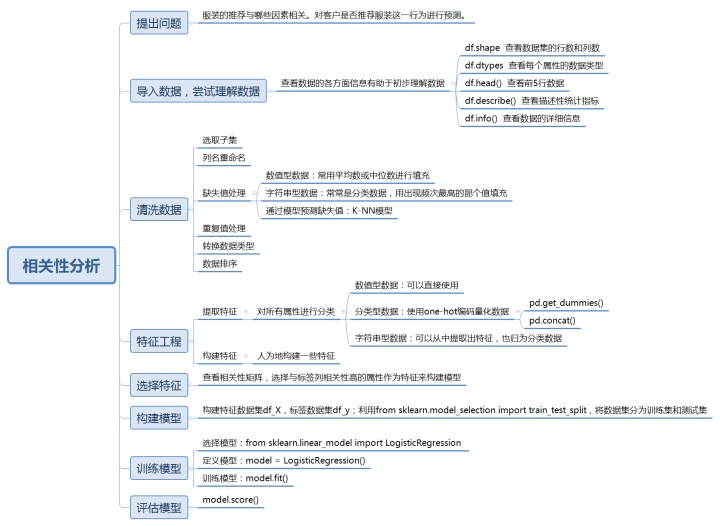
有了上面的框架图,开始正式的分析过程。
一. 提出问题
本次分析的目标是:客户对于服装的推荐与哪些因素相关,构建模型来预测客户是否推荐服装。
二. 导入数据,尝试理解数据
先用pandas的read方法将数据读取到Python中,然后查看数据的各方面的信息,初步理解一下数据。
常用的方法:
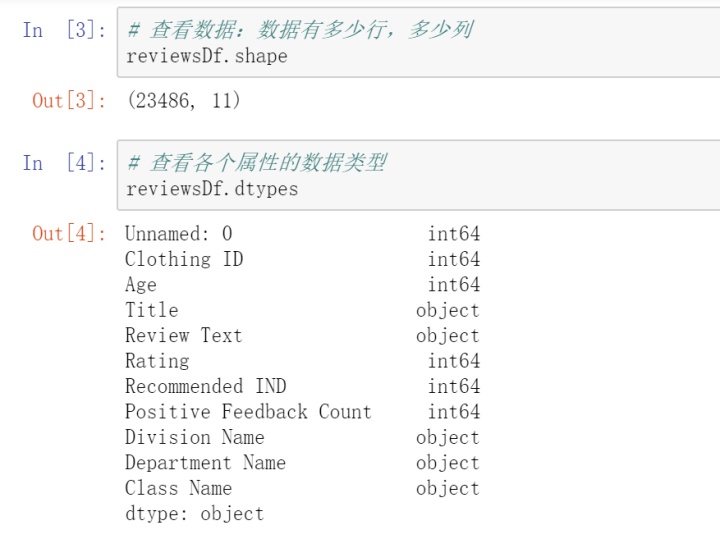
1. df. shape 查看数据有多少行,多少列
2. df.dtypes 查看各个属性的数据类型
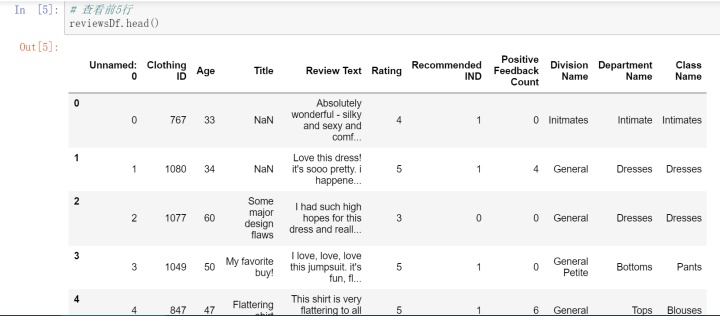
3. df. head() 查看前5行数据
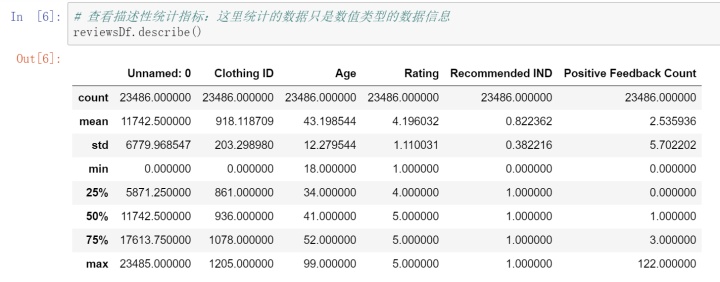
4. df. describe() 查看数据的描述性统计指标,这个只显示数值型的数据
5. df. info() 查看数据的详细信息,这个也可以显示其他类型的数据。通过info,我们可以知道数据集的行数和列数,每个属性的数据类型、是否可以为空、是否有缺失值。可以为后面的数据清洗做准备。

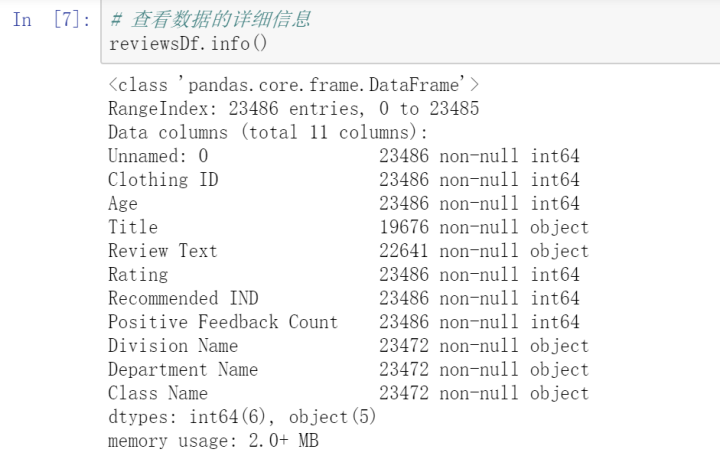
二. 清洗数据
清洗数据常用的几步:
1. 选取子集
2. 列名重命名
3. 缺失值处理
4. 重复值处理
5. 数据类型转换
6. 数据排序
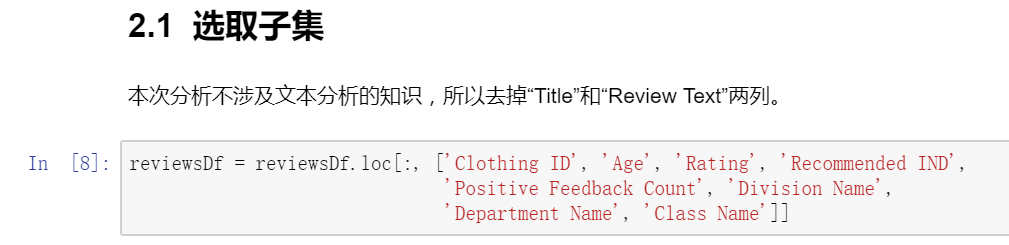
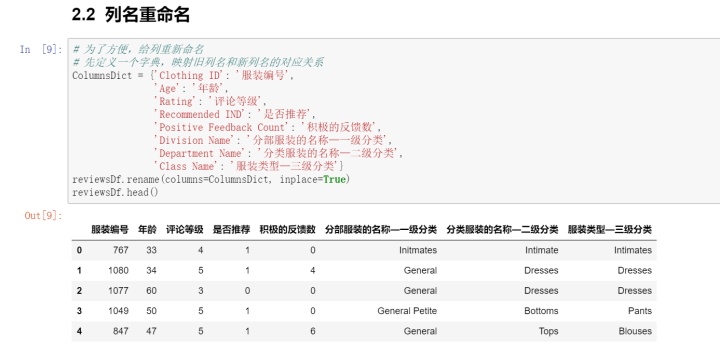
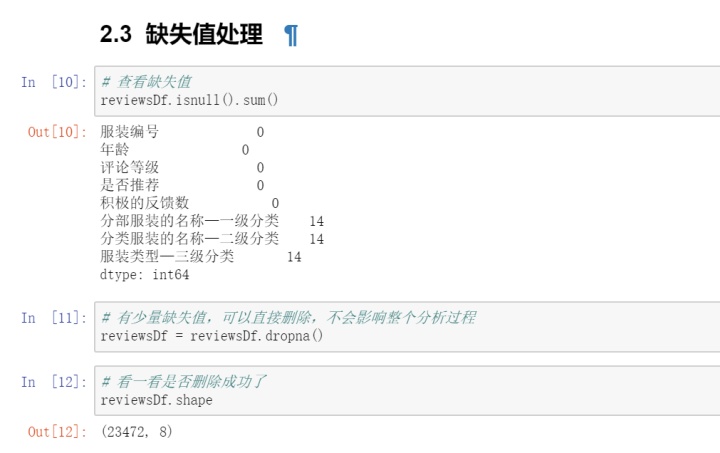
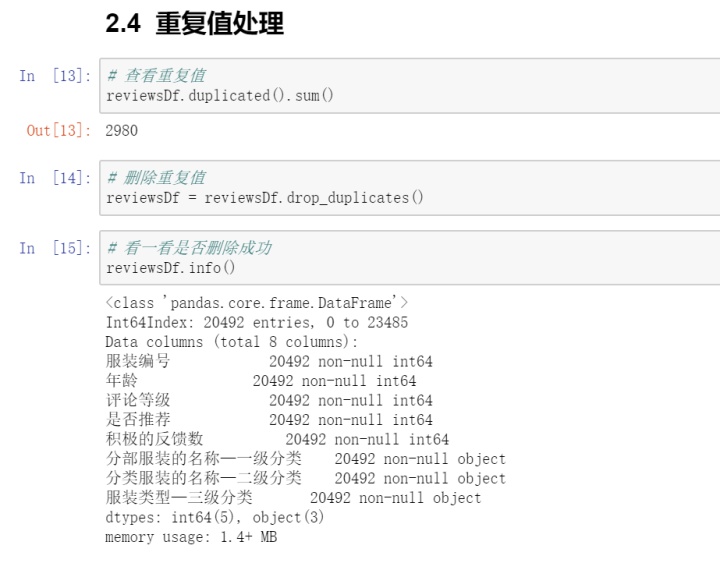
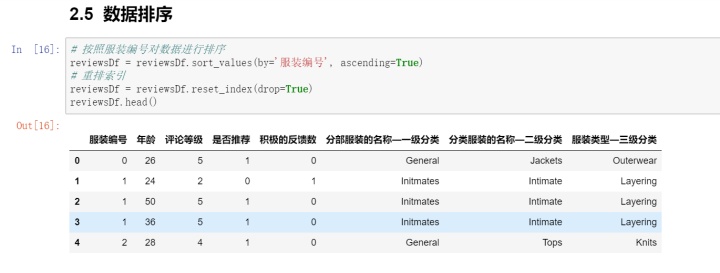
数据清洗完毕,因为选取的数据集相对简单,不需要进行特征工程。
不过在这里还是要强调一下特征工程的重要性。业界流行一句话:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。由此可见,对于特征的处理是基础,却也是重中之重,直接影响了后面的模型构建和预测结果的好坏。
那么,特征工程到底是什么呢?实际上,特征工程就是一个把原始数据转换成特征的过程,这些特征可以很好地描述这些数据,并且利用它们建立的模型在未知数据上的表现性能可以达到最优(或接近最佳性能)。从数学角度来看,特征工程就是人工地去设计输入变量x。我们的目标就是:得到能够很好地描述数据内部结构的好特征。
需要注意的是,特征工程是一个迭代工程。我们需要不断地设计特征、选择特征、建立模型、评估模型,然后才能得到最终的model。
三. 选择特征
选择特征的目的是:从特征集合中挑选一组最具统计意义的特征子集,从而达到降维的效果。
方法:用一些评价指标单独地计算出单个变量特征跟类别变量之间的关系。如:
Pearson相关系数、基尼指数、信息增益等。
本案例使用的是Pearson相关系数法。案例相对简单,只选择了一个特征来建立模型。遇到复杂的案例还是需要用心去选择合适的特征子集的。
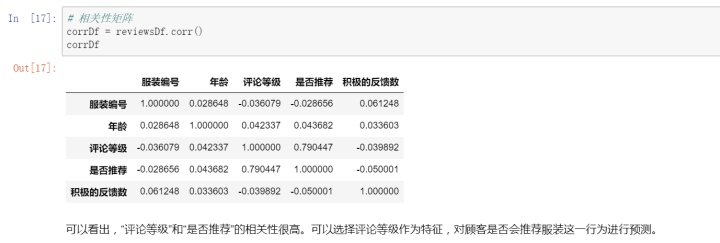
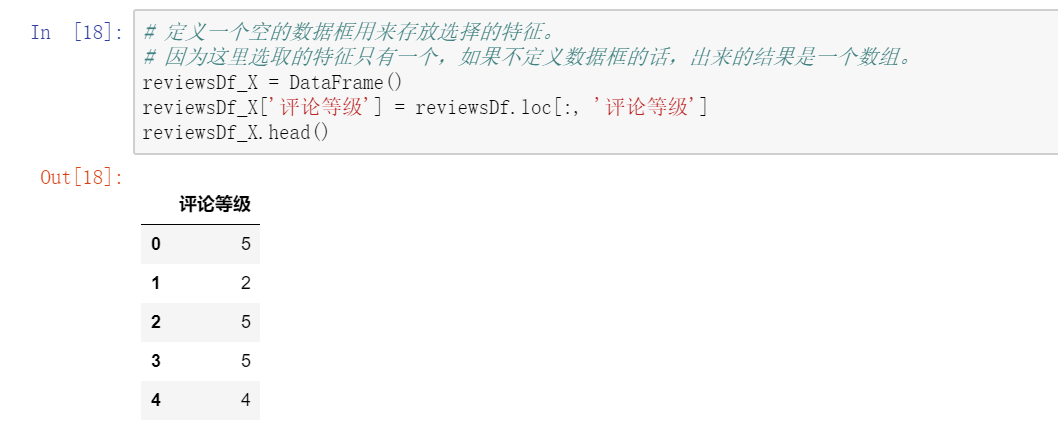
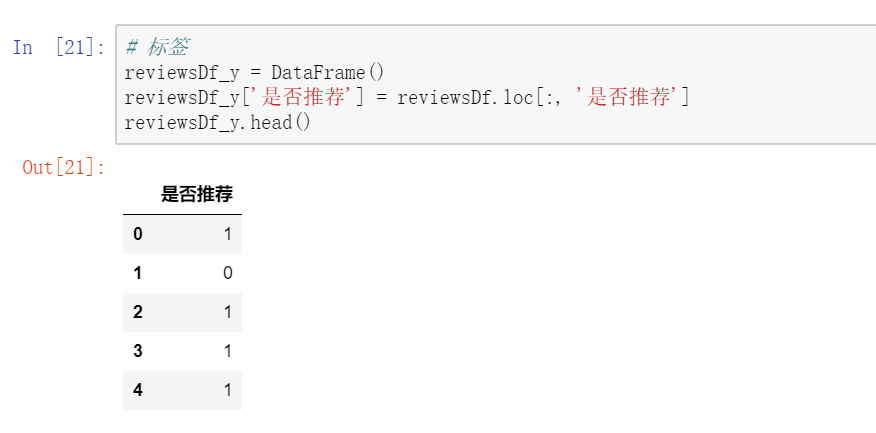
四. 构建模型
我们要得到一个模型,用来预测客户是否会推荐服装。
机器学习模型 = 机器学习算法 + 训练数据
所以,我们要得到两个东西:一个是算法,一个是训练数据。
因为我们选择的标签列“是否推荐”是一个逻辑值,‘1’代表‘是’,‘0’代表‘否’,所以选择逻辑回归算法是最合适的。
那么训练数据怎么得到呢?
这需要我们从原始数据集(reviewsDf)中拆分出训练数据集(用于训练模型),测试数据集(用于评估模型)。这一步要用到sklearn中的train_test_split函数。train_test_split是交叉验证中常用的函数,功能是从样本中随机地按比例选取训练数据和测试数据。
train_data:所要划分的样本特征集
train_target:所要划分的样本结果,即标签
train_size:样本占比,如果是整数的话就是样本的数量

五. 训练模型
简单三步:
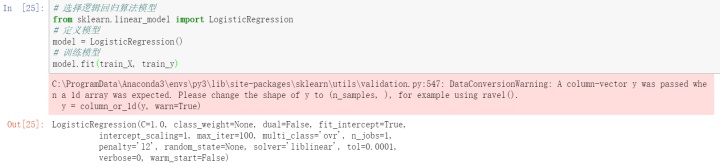
1.导入逻辑回归算法
2.定义模型
3.训练模型
六. 评估模型
分类问题,score方法得到的是模型的正确率。

可以看出,模型的正确率还是很高的,说明选择的特征和算法的性能是不错的。
七. 结论
通过数据清理、特征工程、模型构建和模型评估,我们发现评论等级和是否推荐的相关性是很高的,所以我们选择评论等级作为特征输入模型中,最终我们得到了一个正确率为0.93的模型。这个模型可以用于新数据的预测。也就是说,我们只需要知道某个服装的评论等级,就可以预测出客户是否会推荐这个服装。















 5346
5346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









