






首先说说为什么要讲解这篇论文,这篇论文是发表在2017年CVPR上的论文,之所以挑出来讲解,是因为自己想了解一下注意力机制方面的知识。之前一直听说过“attention”,但就不知道什么意思,更别说应用了,一提到“attention”就觉得很高大上,所以近期准备研究一些关于注意力的文章。话不多说,进入正题!
【注意力机制的初衷】
什么是注意力机制?他是干嘛的呢?简单的来说就是把目光放在重点特征上,忽略那些无关紧要的信息。论文在摘要部分就说了注意力机制的设计初衷:一个动态的上下文有关的横跨时间的特征提取器。这句话怎么理解呢?我个人认为就是统筹全局信息(包括前面已获得的先验信息)来对现在的特征进行提取重要有用的信息。本文是结合空间注意力(spatial attetion)和通道注意力(channel-wise)两者共同在多层特征之间的应用。attention机制的本质是训练一个权重,然后这个权重可以用来对channel做选择或者叠加在feature map的每个像素点上,比如之前我讲解的SE-Net就是采用的训练权重对feature map的channel做选择的方式。
【Introduction】
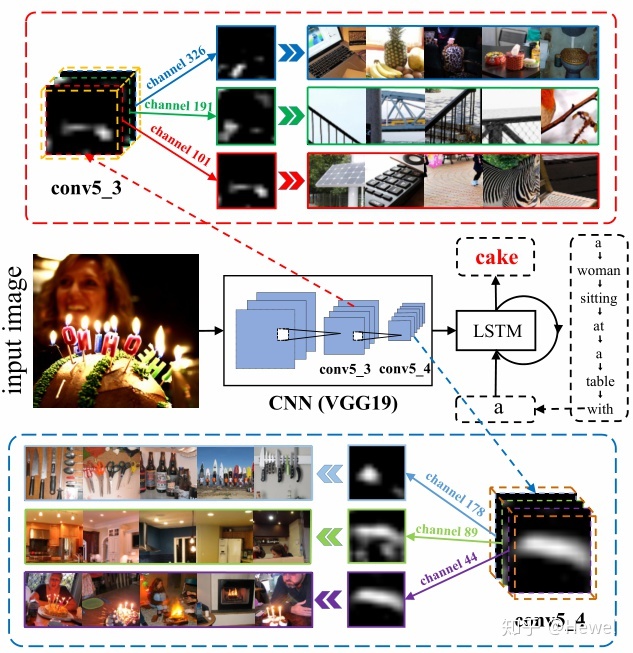
这是论文中的一张图,反映了通道注意力(channel-wise)在多层特征(multi-layer)间的应用。采用channel wise attention方法处理网络的某些层(比如VGG19网络中的conv5_3和conv5_4层)后的可视化效果。选取其中权重最大的3个channel的feature map并可视化,同时展示了每个channel的feature map对应的5张图像中感受野的响应最大的区域。
【流程】
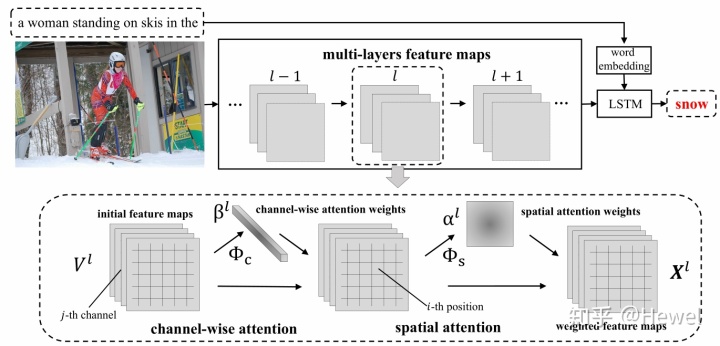
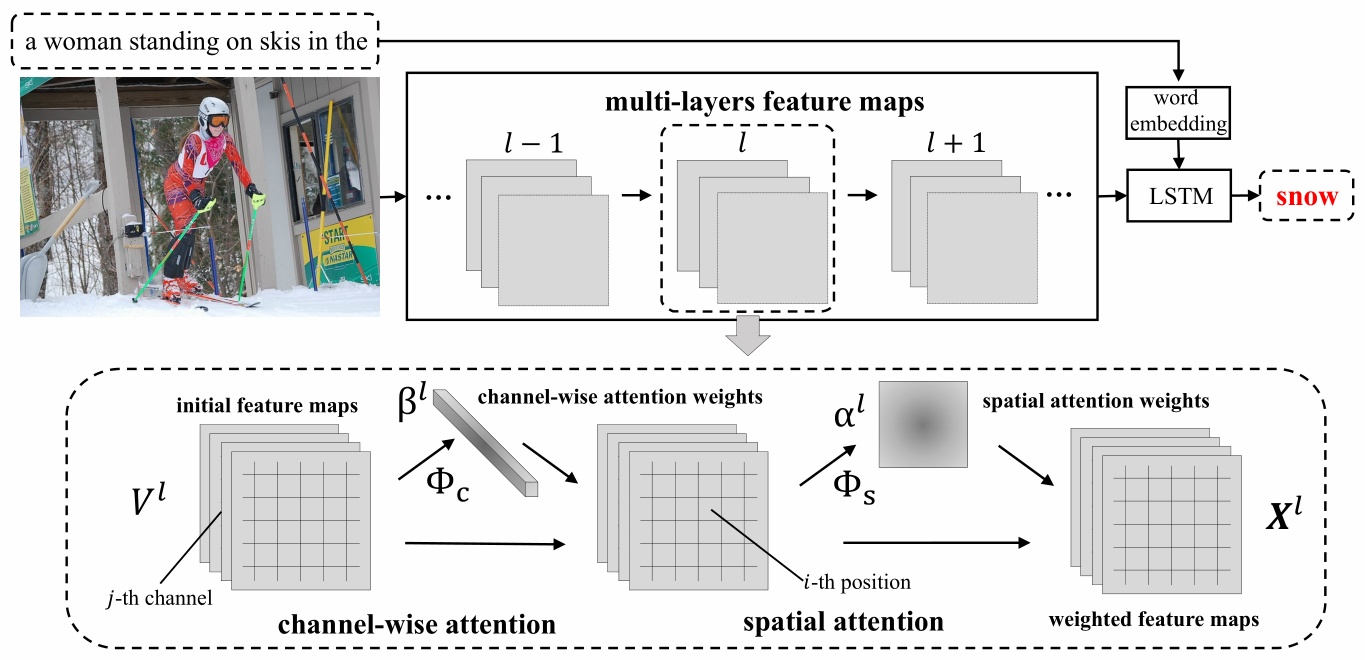
稍微解释一下:
(1)spatial attention:以当前feature map的每个像素为单位,对每个像素都分配一个权重值,这个权重值是一个二维矩阵;
(2)channel-wise:以feature map为单位,对每个channel分配一个权重,因此这个权重是一个向量。
上图是SCA-CNN的整体图,还是采取的经典的encoder-decoder结构,主要包含CNN网络(encoder)和LSTM网络(decoder)两部分。CNN网络包含spatial attention和channel wise attention两种attention操作。spatial attention可以理解以feature map的每个像素点为单位,对feature map的每个像素点都配一个权重值,因此这个权重值应该是一个矩阵;channel wise attention则是以feature map为单位,对每个channel都配一个权重值,因此这个权重值应该是一个向量。
其实对于LSTM笔者也不熟悉,所以这里暂时不详说。
好了,这篇基本上就说到这了,主要让大家了解一下注意力机制的一个大概情况,后面还会陆续带来相关的其他论文!















 9453
9453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









