






温馨提示:看完本大约需要12.4min~
摘要:
B-Tree:即BTree,或者B树,可不要读作B减树让人笑话啦。它是多路搜索树(不是二叉的)。
B+Tree:B+Tree也是多路搜索树,是B-Tree的变体。
二叉查找树:二叉查找树也叫二叉排序树,所以,它是有顺序的,每一个节点,它的左子树每个节点值都要小于该节点值,它的右子树每个节点值都要大于该节点值。
平衡二叉树:AVL树,在符合二叉查找树的前提下,任意节点的两个子树深度查不大于1。
平衡多路查找树:大致了解以上概念,平衡多路查找树也就不难理解了。B-Tree是平衡多路查找树。
完全二叉树:若设二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第 h 层所有的结点都连续集中在最左边,这就是完全二叉树。
满二叉树:满二叉树即字面的意思,满二叉树是一颗特殊的完全二叉树。每一个非叶节点都有两个子节点,所有的叶节点都在同一层。
前言:本文主要将B-Tree、B+Tree,在学习它们我们可能需要了解一些常见的数据结构,如二叉树,二叉查找树,平衡二叉树等。
一、二叉查找树(binary search tree)
二叉树:任意节点最多有两个子节点的树,我们称之为二叉树。
二叉查找树:左子树的健小于跟节点的键值,右子树的键值大于跟节点的键值。
二叉查找树示意图:
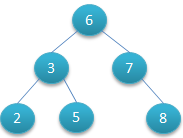
对二叉查找树的节点进行查找发现:深度为1的节点的查找次数为1,深度为2的查找次数为2,深度为n的节点的查找次数为n,因此其平均查找次数为(1+2+2+3+3+3) / 6 = 2.3次。
二叉查找树可以任意构造,同时也可以是一种链式结构,这种结构比较特殊,查找效率比较慢。所以想提高查找效率,由此便提出了平衡二叉树,也称作AVL树。
二、平衡二叉树(AVL Tree)
简单看一下平衡二叉树(AVL Tree)和非平衡二叉树的结构图:
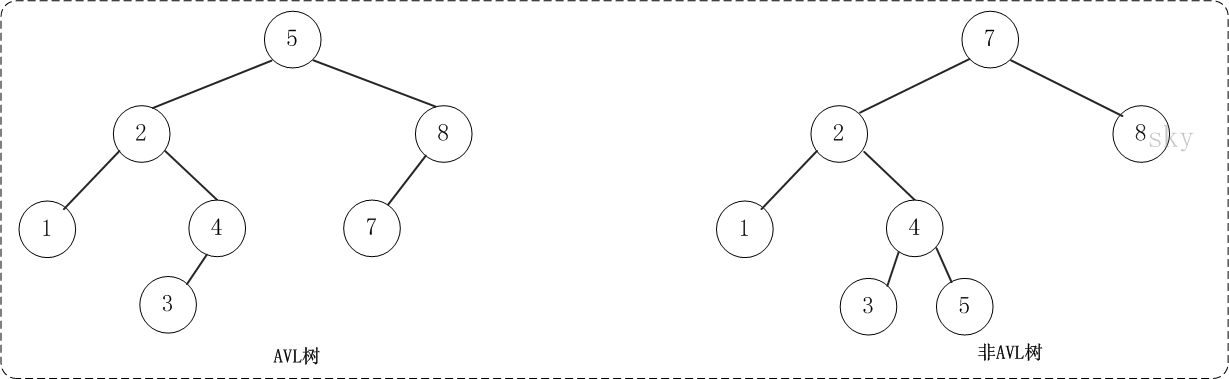
如果我们对AVL树进行插入节点或删除节点操作,那么可能会导致AVL树失去平衡,这种失去平衡的二叉树已经不能再称之为AVL树。示例:在上图的AVL树中,如果我们将值为7的节点进行DELETE,那么,这颗AVL树就会失去平衡。
AVL树失去平衡后,要保持平衡可不是一件容易的事情,我们可以通过旋转将其恢复平衡。
AVL树的旋转类型有4中,LL、LR、RL、RR,稍后介绍具体该如何进行旋转。
其实,每个节点都有一份隐含的信息,那就是节点的平衡因子。
节点的平衡因子 = 左子树高度 - 右子树高度。
所以这里的另一个问题便得到了解决。什么时候进行旋转操作达到平衡?或者换一种问法,如何才知道我们的树失去了平衡?当树中存在节点的平衡因子不是-1、0、+1时,那就是失去了平衡,就需要进行调整,达到平衡。保证每个节点平衡,以局部平衡保持整体平衡。

为方便理解在何时执行哪一种旋转,设x代表刚插入AVL树中的结点,设A为离x最近且平衡因子更改为2的绝对值的祖先。
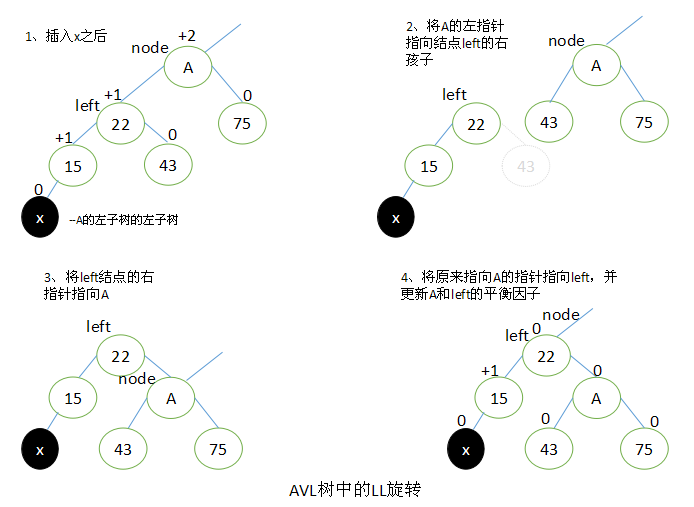
LL旋转
当x位于A的左子树的左子树上时,执行LL旋转。
步骤:设left为A的左子树,要执行LL旋转,将A的左指针指向left的右子结点,left的右指针指向A,将原来指向A的指针指向left。
旋转过后,将A和left的平衡因子都改为0。所有其他结点的平衡因子没有发生变化。
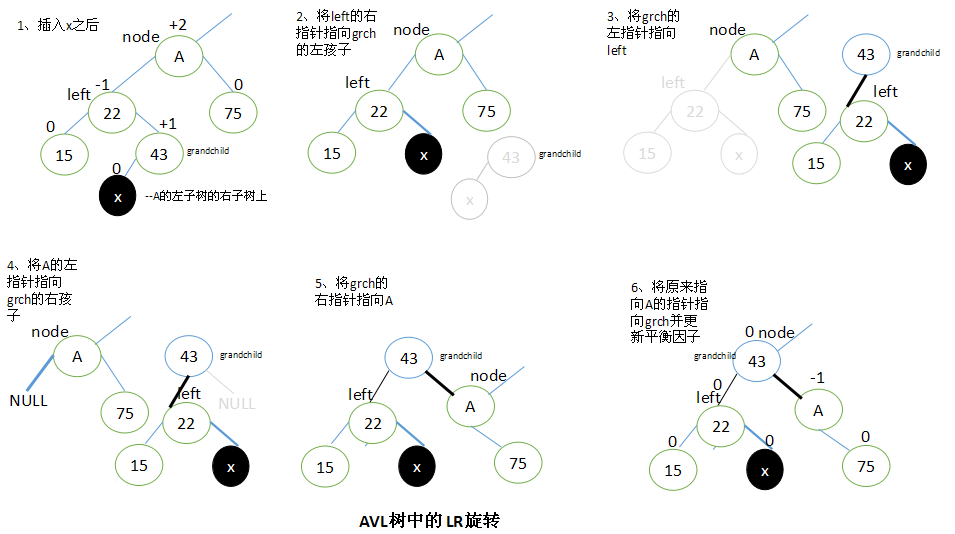
LR旋转
当x位于A的左子树的右子树上时,执行LR旋转。
设left是A的左子结点,并设A的子孙结点grandchild为left的右子结点。
步骤:要执行LR旋转,将left的右子结点指向grandchild的左子结点,grandchild的左子结点指向left,A的左子结点指向grandchild的右子结点,再将grandchild的右子结点指向A,最后将原来指向A的指针指向grandchild。
执行LR旋转之后,调整结点的平衡因子取决于旋转前grandchild结点的原平衡因子值。
如果grandchild结点的原始平衡因子为+1,就将A的平衡因子设为-1,将left的平衡因子设为0。
如果grandchild结点的原始平衡因子为0,就将A和left的平衡因子都设置为0。
如果grandchild结点的原始平衡因子为-1,就将A的平衡因子设置为0,将left的平衡因子设置为+1。
在所有的情况下,grandchild的新平衡因子都是0。所有其他结点的平衡因子都没有改变。
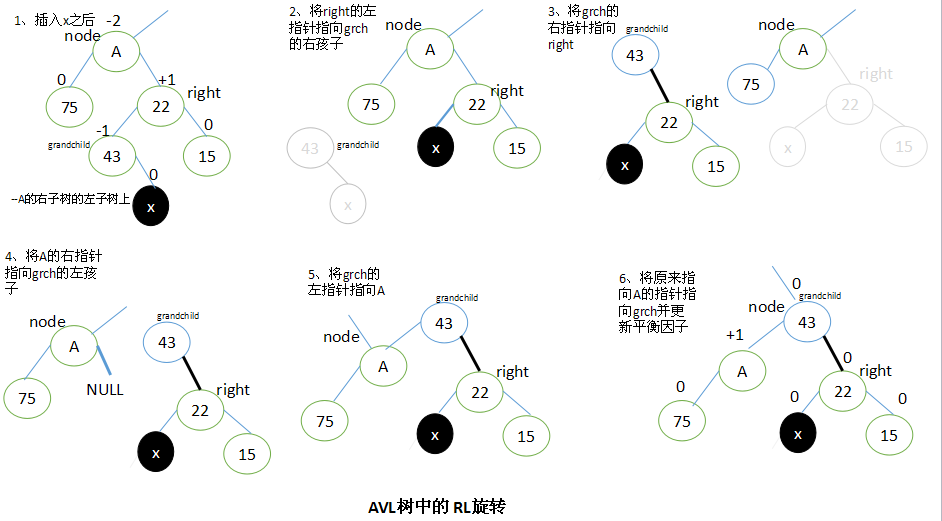
RL旋转
当x位于A的右子树的左子树上时,执行RL旋转。
RL旋转与LR旋转是对称的关系。
步骤:设A的右子结点为right,right的左子结点为grandchild。要执行RL旋转,将right结点的左子结点指向grandchild的右子结点,将grandchild的右子结点指向right,将A的右子结点指向grandchild的左子结点,将grandchild的左子结点指向A,最后将原来指向A的指针指向grandchild。
执行RL旋转以后,调整结点的平衡因子取决于旋转前grandchild结点的原平衡因子。这里也有三种情况需要考虑:
如果grandchild的原始平衡因子值为+1,将A的平衡因子更新为0,right的更新为-1;
如果grandchild的原始平衡因子值为 0,将A和right的平衡因子都更新为0;
如果grandchild的原始平衡因子值为-1,将A的平衡因子更新为+1,right的更新为0;
在所有情况中,都将grandchild的新平衡因子设置为0。所有其他结点的平衡因子不发生改变。
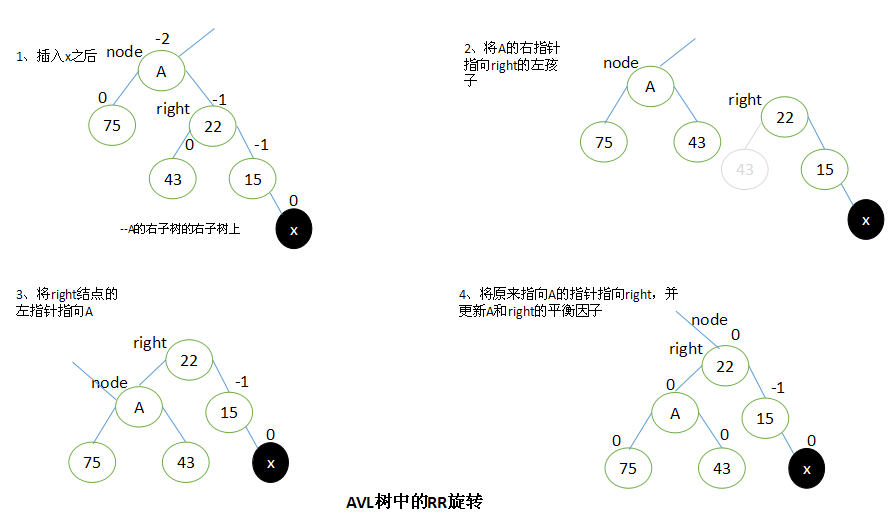
RR旋转
当x位于A的左子树的右子树上时,执行RR旋转。
RR旋转与LL旋转是对称的关系。
设A的右子结点为Right。要执行RR旋转,将A的右指针指向right的左子结点,right的左指针指向A,原来指向A的指针修改为指向right。
完成旋转以后,将A和left的平衡因子都修改为0。所有其他结点的平衡因子都没有改变。
TODO深度优先遍历、广度优先遍历
TODO代码层面的具体实现
TODO为什么1.8的HashMap选择红黑树,而不是二叉搜索树?
下一篇对红黑树数据结构的深入理解,届时应该会解释这个问题。
三、平衡多路查找树(B-Tree)
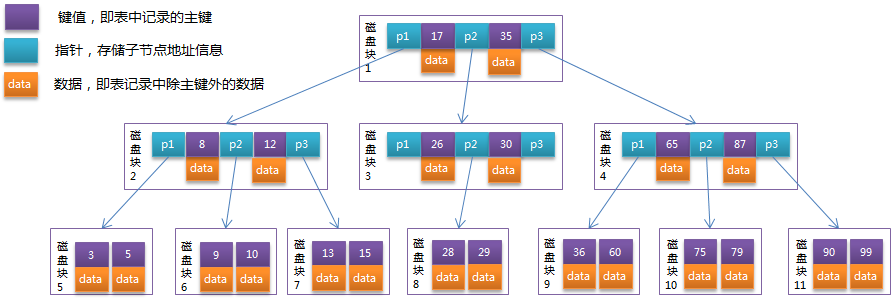
在计算机科学中,B树(英语:B-tree)是一种自平衡的树,能够保持数据有序。这种数据结构能够让查找数据、顺序访问、插入数据及删除的动作,都在对数时间内完成。B树,概括来说是一个一般化的二叉查找树(binary search tree)一个节点可以拥有最少2个子节点。与自平衡二叉查找树不同,B树适用于读写相对大的数据块的存储系统,例如磁盘。B树减少定位记录时所经历的中间过程,从而加快存取速度。B树这种数据结构可以用来描述外部存储。这种数据结构常被应用在数据库和文件系统的实现上。
——————摘自维基百科
所以,我们口中的B树,也就是所谓的BTree,或者B-Tree,不存在口中的B减树。B-Tree是一棵树多路平衡树。
扩展:如果你还听过“2-3 B树”,简称为2-3树,它也是一棵B-Tree,该B-Tree内部的节点只能有2个或者3个子节点。
B-Tree的定义:
一个 m 阶的B树是一个有以下属性的树:
每一个节点最多有 m 个子节点
每一个非叶子节点(除根节点)最少有 ⌈m/2⌉ 个子节点
如果根节点不是叶子节点,那么它至少有两个子节点
有 k 个子节点的非叶子节点拥有 k − 1 个键
所有的叶子节点都在同一层
每一个内部节点的键将节点的子树分开。例如,如果一个内部节点有3个子节点(子树),那么它就必须有两个键: a1 和 a2 。左边子树的所有值都必须小于 a1 ,中间子树的所有值都必须在 a1 和a2 之间,右边子树的所有值都必须大于 a2 。
问:MySQL INNODB引擎中索引数据结构为什么是B-/B+Tree,而不是二叉搜索树?为什么也不是红黑树?
答:B-Tree相对于二叉搜索树会减少搜索节点数,也就是缩减了节点个数,从而减少I/O操作,使得I/O操作和内存操作达到极致,所以,B-Tree相对二叉搜索树来说,性能更好。也不是红黑树的原因和二叉搜索树类似,总之是为了减少I/O操作,减少I/O时间,提高整体性能。
四、B+Tree
B+Tree相对于B-Tree有几点不同:
非叶子节点只存储键值信息。
所有叶子节点之间都有一个链指针。
数据记录都存放在叶子节点中。
将上一节中的B-Tree优化,由于B+Tree的非叶子节点只存储键值信息,假设每个磁盘块能存储4个键值及指针信息,则变成B+Tree后其结构如下图所示:
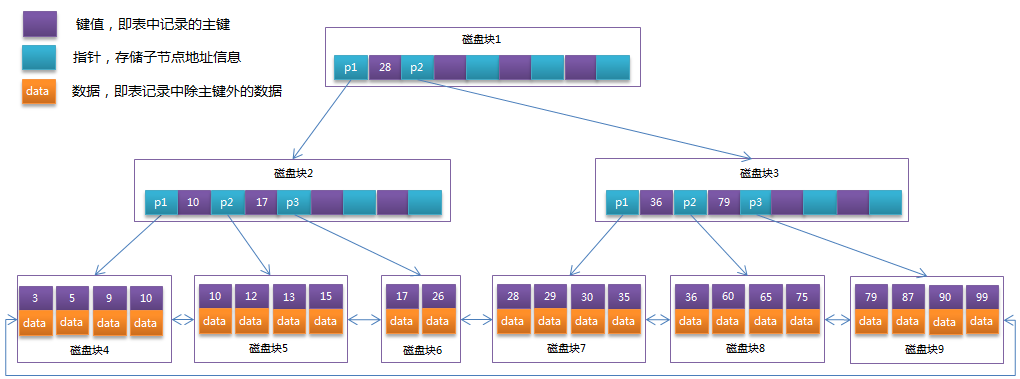
通常在B+Tree上有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点,而且所有叶子节点(即数据节点)之间是一种链式环结构。因此可以对B+Tree进行两种查找运算:一种是对于主键的范围查找和分页查找,另一种是从根节点开始,进行随机查找。
B+Tree是B-Tree众多变异体中的一种,同时也是B-Tree的基础之上的一种优化。使其更适合实现外存储索引结构,InnoDB存储引擎就是用B+Tree实现其索引结构。
至于优化的点在哪里,请听我慢慢道来。
首先,我们需要了解到MySQL INNODB引擎中有“页”的概念。页是磁盘管理的最小单位。InnoDB存储引擎中默认每个页的大小为16KB,我们可以通过
mysql> show variables like 'innodb_page_size';
来进行查看页大小。我们从上面的B-Tree图来看,一个节点分为三部分:指向子节点的指针、键、data。如果data足够大,会让一个页中的节点数变少,当节点数变少,平均I/O操作就会增多,整体性能下降,所以这是B+Tree的优化点,去掉非叶节点中的Data,让非叶节点保存的数据变少,从而提升节点中的键增多,便减少了I/O操作,所以提高整体性能。
当然,只是能说是提高整体性能,为什么这么说?
大家想想看,假设A同学用B-Tree,B同学用B+Tree,如果查询同一个东西,假设这个数据就在root节点,那么A同学是不是一下子就查到了?而B同学却不能,所以,这种情况A同学效率更高。但是对于整体,B同学效率更高。
刚刚说到InnoDB存储引擎中每个页的大小默认为16KB,现在我们来算算在InnoDB下,B+Tree中一个节点能有多少个键。
一般表的主键类型为INT(占用4个字节)或BIGINT(占用8个字节),指针类型也一般为4或8个字节,也就是说一个页(B+Tree中的一个节点)中大概存储16KB/(8B+8B)=1K个键值(因为是估值,为方便计算,这里的K取值为〖10〗^3)。也就是说一个深度为3的B+Tree索引可以维护10^3 * 10^3 * 10^3 = 10亿 条记录。
实际情况中每个节点可能不能填充满,因此在数据库中,B+Tree的高度一般都在2~4层。MySQL的InnoDB存储引擎在设计时是将根节点常驻内存的,也就是说查找某一键值的行记录时最多只需要1~3次磁盘I/O操作。
参考文献:
https://www.cnblogs.com/vianzhang/p/7922426.html
https://www.cnblogs.com/idreamo/p/8308336.html
https://zh.wikipedia.org/wiki/B%E6%A0%91
https://zh.wikipedia.org/wiki/B%2B%E6%A0%91
http://blog.codinglabs.org/articles/theory-of-mysql-index.html














 4079
4079











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









