







来源:《舰队Collection》岛风
前言
一致性哈希算法在很多领域有应用,例如分布式缓存领域的 MemCache,Redis,负载均衡领域的 Nginx,各类 RPC 框架。不同领域场景不同,需要顾及的因素也有所差异,本文主要讨论在负载均衡中一致性哈希算法的设计。
在介绍一致性哈希算法之前,我将会介绍一些哈希算法,讨论它们的区别和使用场景。也会给出一致性哈希算法的 Java 通用实现,可以直接引用,文末会给出 github 地址。
友情提示:阅读本文前,最好对一致性哈希算法有所了解,例如你最好听过一致性哈希环这个概念,我会在基本概念上缩短篇幅。
一致性哈希负载均衡介绍
负载均衡这个概念可以抽象为:从 n 个候选服务器中选择一个进行通信的过程。负载均衡算法有多种多样的实现方式:随机、轮询、最小负载优先等,其中也包括了今天的主角:一致性哈希负载均衡。一致性哈希负载均衡需要保证的是“相同的请求尽可能落到同一个服务器上”,注意这短短的一句描述,却包含了相当大的信息量。“相同的请求” — 什么是相同的请求?一般在使用一致性哈希负载均衡时,需要指定一个 key 用于 hash 计算,可能是:
请求方 IP
请求服务名称,参数列表构成的串
用户 ID
“尽可能” —为什么不是一定?因为服务器可能发生上下线,所以少数服务器的变化不应该影响大多数的请求。这也呼应了算法名称中的“一致性”。
同时,一个优秀的负载均衡算法还有一个隐性要求:流量尽可能均匀分布。
综上所述,我们可以概括出一致性哈希负载均衡算法的设计思路。
尽可能保证每个服务器节点均匀的分摊流量
尽可能保证服务器节点的上下线不影响流量的变更
哈希算法介绍
哈希算法是一致性哈希算法中重要的一个组成部分,你可以借助 Java 中的 inthashCode()去理解它。 说到哈希算法,你想到了什么?Jdk 中的 hashCode、SHA-1、MD5,除了这些耳熟能详的哈希算法,还存在很多其他实现,详见 HASH 算法一览。可以将他们分成三代:
第一代:SHA-1(1993),MD5(1992),CRC(1975),Lookup3(2006)
第二代:MurmurHash(2008)
第三代:CityHash, SpookyHash(2011)
这些都可以认为是广义上的哈希算法,你可以在 wiki 百科 中查看所有的哈希算法。当然还有一些哈希算法如:Ketama,专门为一致性哈希算法而设计。
既然有这么多哈希算法,那必然会有人问:当我们在讨论哈希算法时,我们再考虑哪些东西?我大概总结下有以下四点:
实现复杂程度
分布均匀程度
哈希碰撞概率
性能
先聊聊性能,是不是性能越高就越好呢?你如果有看过我曾经的文章 《该如何设计你的 PasswordEncoder?》,应该能了解到,在设计加密器这个场景下,慢 hash 算法反而有优势;而在负载均衡这个场景下,安全性不是需要考虑的因素,所以性能自然是越高越好。
优秀的算法通常比较复杂,但不足以构成评价标准,有点黑猫白猫论,所以 2,3 两点:分布均匀程度,哈希碰撞概率成了主要考虑的因素。
我挑选了几个值得介绍的哈希算法,重点介绍下。
MurmurHash 算法:高运算性能,低碰撞率,由 Austin Appleby 创建于 2008 年,现已应用到 Hadoop、libstdc++、nginx、libmemcached 等开源系统。2011 年 Appleby 被 Google 雇佣,随后 Google 推出其变种的 CityHash 算法。官方只提供了 C 语言的实现版本。Java 界中 Redis,Memcached,Cassandra,HBase,Lucene 都在使用它。 在 Java 的实现,Guava 的 Hashing 类里有,上面提到的 Jedis,Cassandra 里都有相关的 Util 类。
FNV 算法:全名为 Fowler-Noll-Vo 算法,是以三位发明人 Glenn Fowler,Landon Curt Noll,Phong Vo 的名字来命名的,最早在 1991 年提出。 特点和用途:FNV 能快速 hash 大量数据并保持较小的冲突率,它的高度分散使它适用于 hash 一些非常相近的字符串,比如 URL,hostname,文件名,text,IP 地址等。
Ketama 算法:将它称之为哈希算法其实不太准确,称之为一致性哈希算法可能更为合适,其他的哈希算法有通用的一致性哈希算法实现,只不过是替换了哈希方式而已,但 Ketama 是一整套的流程,我们将在后面介绍。
以上三者都是最合适的一致性哈希算法的强力争夺者。
一致性哈希算法实现
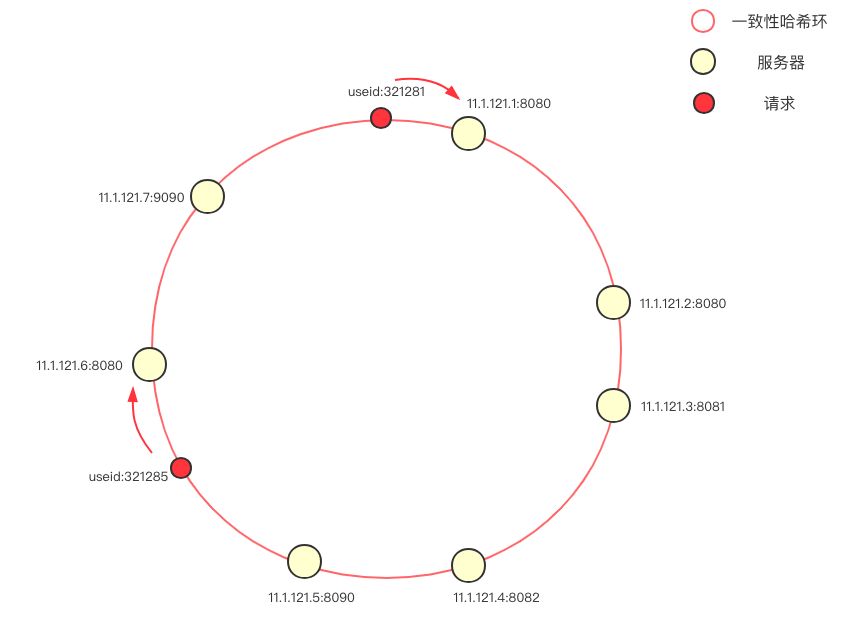
一致性哈希的概念我不做赘述,简单介绍下这个负载均衡中的一致性哈希环。首先将服务器(ip+端口号)进行哈希,映射成环上的一个节点,在请求到来时,根据指定的 hash key 同样映射到环上,并顺时针选取最近的一个服务器节点进行请求(在本图中,使用的是 userId 作为 hash key)。
当环上的服务器较少时,即使哈希算法选择得当,依旧会遇到大量请求落到同一个节点的问题,为避免这样的问题,大多数一致性哈希算法的实现度引入了虚拟节点的概念。
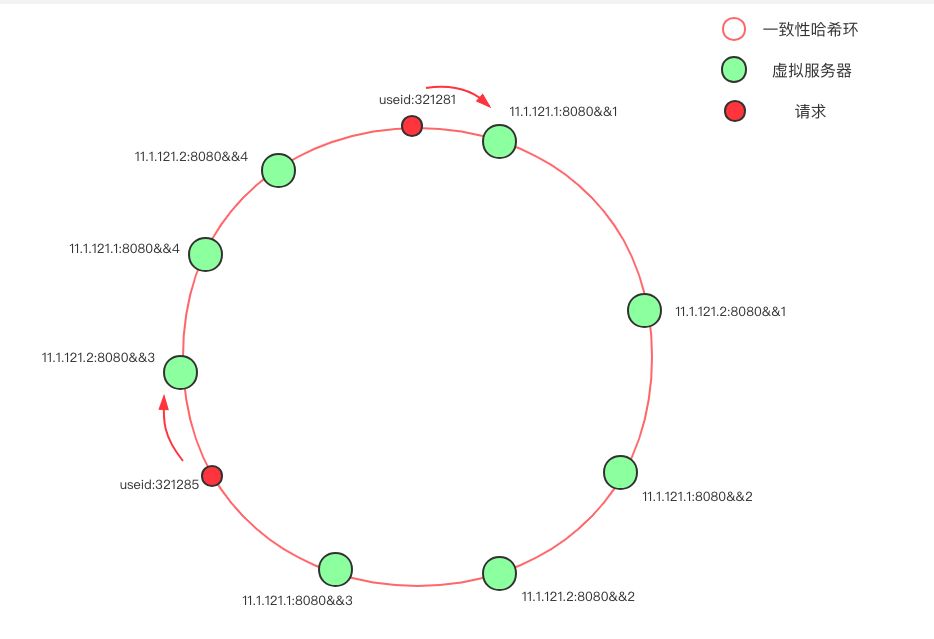
在上图中,只有两台物理服务器节点:11.1.121.1 和 11.1.121.2,我们通过添加后缀的方式,克隆出了另外三份节点,使得环上的节点分布的均匀。一般来说,物理节点越多,所需的虚拟节点就越少。
介绍完了一致性哈希换,我们便可以对负载均衡进行建模了:
public interface LoadBalancer {
Server select(List<Server> servers, Invocation invocation);
}
下面直接给出通用的算法实现:
public class ConsistentHashLoadBalancer implements LoadBalancer{
private HashStrategy hashStrategy = new JdkHashCodeStrategy();
private final static int VIRTUAL_NODE_SIZE = 10;
private final static String VIRTUAL_NODE_SUFFIX = "&&";
@Override
public Server select(List<Server> servers, Invocation invocation) {
int invocationHashCode = hashStrategy.getHashCode(invocation.getHashKey());
TreeMap<Integer, Server> ring = buildConsistentHashRing(servers);
Server server = locate(ring, invocationHashCode);
return server;
}
private Server locate(TreeMap<Integer, Server> ring, int invocationHashCode) {
// 向右找到第一个 key
Map.Entry<Integer, Server> locateEntry = ring.ceilingEntry(invocationHashCode);
if (locateEntry == null) {
// 想象成一个环,超过尾部则取第一个 key
locateEntry = ring.firstEntry();
}
return locateEntry.getValue();
}
private TreeMap<Integer, Server> buildConsistentHashRing(List<Server> servers) {
TreeMap<Integer, Server> virtualNodeRing = new TreeMap<>();
for (Server server : servers) {
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 692
692











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









