







三、Nginx
3.1 Nginx的介绍
- Nginx是一款轻量级的Web 服务器/反向代理服务器占有内存少,并发能力强,官方测试nginx能够支撑5万并发链接,并且CPU、内存等资源消耗却非常低,运行非常稳定。
3.2 使用场景
3.2.1 高并发场景
-
高并发:
高并发通常是指通过设计保证系统能够同时并行处理很多请求。简单来说,高并发就是在同一个时间点,有很多的用户同时访问同一的API接口或者URL地址。
-
高并发带来的问题:
- 会给服务器和硬件环境带来很大的压力
- 池:
- 刚开始的时候创建多个请求等待使用
- 使用完毕后并不会销毁,而是重新归还到池
- 如果业务量比较大,我们通过池控制最大连接的数
-
高并发的解决——负载均衡
将请求/数据【均匀】分摊到多个操作单元上执行,负载均衡的关键在于【均匀】
3.2.2代理服务器
-
代理服务器:
- 提供代理服务的电脑系统或其它类型的网络终端,代替网络用户去获取网络信息。
-
使用代理服务器的原因
- 提高访问速度
由于目标主机返回的数据会存放在代理服务器的硬盘中,因此下一次客户再访问相同的站点数据时,会直接从代理服务器的硬盘中读取,起到了缓存的作用,尤其对于热门网页能明显提高访问速度。 - 防火墙作用
由于所有的客户机请求都必须通过代理服务器访问远程站点,因此可以在代理服务器上设限,过滤掉某些不安全信息。同时正向代理中上网者可以隐藏自己的IP,免受攻击。 - 突破访问限制
互联网上有许多开发的代理服务器,客户机在访问受限时,可通过不受限的代理服务器访问目标站点,通俗说,我们使用某些其它网站就是利用了代理服务器,可以直接访问
- 提高访问速度
-
代理服务器的分类
-
正向代理(默认代理方式)
-
定义:
一个位于客户端和原始服务器端之间的服务器,为了从原始服务器取得内容,客户端向代理服务器发送一个请求并指定目标(原始服务器),然后代理服务器向原始服务器转发请求并将获得的内容返回给客户端,客户端才能使用正向代理。
-
应用:
- 访问原来无法访问的资源
- 可做缓存,加速访问资源
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VC8g3aCV-1655294566692)(https://s2.loli.net/2022/06/15/BksyNHtDQ8fCL1S.jpg)]](https://img-blog.csdnimg.cn/f0859974d77d46018a413e48fcb55efd.png)
-
-
反向代理(Nginx)
-
定义:
客户只需要发送请求到代理服务器,代理服务器会将请求转发给内部的服务器去处理,处理完毕之后会将结果返回给客户,整个过程中客户与实际处理服务器是不会直接建立连接的
-
应用:
- 保护内网安全
- 负载均衡(Nginx)
-
-
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VzVQ2lbY-1655294566693)(https://s2.loli.net/2022/06/15/Q2JOhLjz3XkCo7S.png)]](https://img-blog.csdnimg.cn/33254160ddef481fa115c3629e0bff81.png)
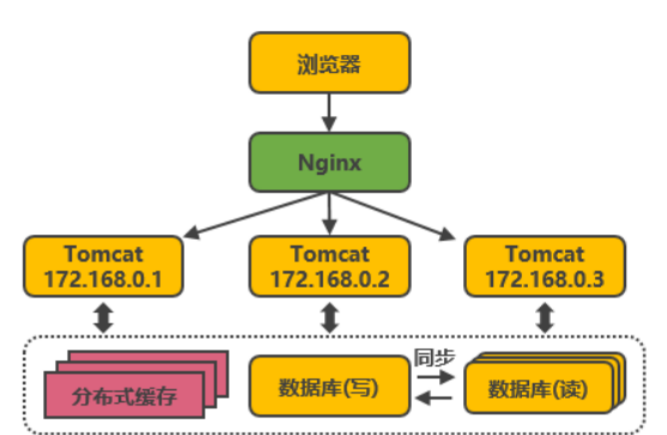
3.3 Nginx负载均衡
3.3.1 集群搭建
- 节点分布
| 节点\角色 | Nginx | Tomcat | JDK |
|---|---|---|---|
| basenode | √ | √ | |
| node01 | √ | √ | |
| node02 | √ | √ | |
| node03 | √ | √ |
-
BaseNode修改配置文件
#user nobody; worker_processes 1; events { worker_connections 1024; } http { include mime.types; default_type application/octet-stream; sendfile on; keepalive_timeout 0; upstream bdp { server 192.168.88.101:8080; server 192.168.88.102:8080; server 192.168.88.103:8080; } server { listen 80; server_name localhost; location / { proxy_pass http://bdp; } } } -
Tomcat配置信息
- vi /opt/bdp/apache-tomcat–8.5.47/webapps/ROOT/index.jsp
<%@ page pageEncoding="UTF-8" contentType="text/html; charset=UTF-8" %> <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8" /> <title>斗鱼直播</title> <link href="favicon.ico" rel="icon" type="image/x-icon" /> <link href="favicon.ico" rel="shortcut icon" type="image/x-icon" /> </head> <body> <h1>welcome to 斗鱼直播</h1> <h2>Server:<%=request.getLocalAddr() %></h2> <h2>Port:<%=request.getLocalPort() %></h2> <h2>Client:<%=request.getRemoteAddr() %></h2> <h2>Session:<%=session.getId() %></h2> <hr/> <img src="/static/img/qbl.jpg" height="200px" /> </body> </html> -
启动Tomcat和Nginx
访问Nginx,会依次将Tomcat页面显示到也面
3.3.2 负载策略
1. 请求轮询(默认)
- 将请求按时间顺序依次转发给不同的服务器
- 平均分配,是他们的负载大致相同
2.增加权重
使用服务器权重,就可以进一步的影响Nginx的负载均衡算法,谁的权重大,分发到的请求就越多
upstream bdpweight {
server 192.168.88.101:8080 weight=2;
server 192.168.88.103:8080 weight=1;
}
3.最少连接数(least_conn)
把请求转发给连接数较少的服务器,避免服务器过载
upstream bdpleast {
least_conn;
server 192.168.88.101:8080;
server 192.168.88.103:8080;
}
4.IP_HASH
负载均衡器按照客户端IP地址的分配方式,可以确保相同客户端的请求一直发送到相同的服务器,以保证session会话。
这样每个访客都固定访问一个后端服务器,可以解决session不能跨服务器的问题。
upstream bdphash {
ip_hash;
server 192.168.88.101:8080;
server 192.168.88.103:8080;
}
3.4 资源静态化
3.4.1 床图
由外部服务器统一管理图片
常见的一些图床
3.4.2 配置静态资源
<body>
<h1> welcome to cluster</h1>
<h1> 服务器地址: <%= request.getLocalAddr() %> </h1>
<h1> 客户端地址: <%= request.getRemoteAddr() %> </h1>
<h1> Session的ID : <%= session.getId() %> </h1>
<img width="200px" src="/static/qbl.jpg" />
</body>
- 在Nginx的html目录下创建一个static文件夹,然后存放图片
location ^~ /static/ {
root html;
}
3.5 单Linux搭建多Tomcat
3.5.1 拷贝多台Tomcat

3.5.2 环境变量的配置
#tomcat8080
export CATALINA_HOME=/opt/bdp/apache-tomcat-8080
export CATALINA_BASE=/opt/bdp/apache-tomcat-8080
export TOMCAT_HOME=/opt/bdp/apache-tomcat-8080
#tomcat18080
export CATALINA_HOME18080=/opt/bdp/apache-tomcat-18080
export CATALINA_BASE18080=/opt/bdp/apache-tomcat-18080
export TOMCAT_HOME18080=/opt/bdp/apache-tomcat-18080
修改后执行 source /etc/profile
3.5.3 server.xml文件的修改
-
只需要修改tomcat18080即可,8080保持不变
vim apache-tomcat-18080/conf/server.xml
22--默认为8005--》修改为18005 <Server port="18005" shutdown="SHUTDOWN"> 69--默认为8080--》修改为18080 <Connector port="18080" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443" /> 116-默认为8009--》修改为18009 <Connector port="18009" protocol="AJP/1.3" redirectPort="8443" />
3.5.4 catalina.sh脚本
只需要修改Tomcat18080即可,修改catalina.sh
vim apache-tomcat-18080/bin/catalina.sh
####################113行开始添加
export CATALINA_BASE=$CATALINA_BASE18080
export CATALINA_HOME=$CATALINA_HOME18080
export TOMCAT_HOME=$TOMCAT_HOME18080
3.5.5 启动Tomcat
./apache-tomcat-8080/bin/startup.sh
./apache-tomcat-18080/bin/startup.sh
3.7 虚拟主机
- 虚拟主机
- 是一种特殊的软硬件技术,它可以将网络上的每一台计算机分成多个虚拟机,每个虚拟机都可以独立的对外提供web服务,从而实现一台主机能对外提供多个web服务,而且每个虚拟机之间是互不影响的。
- 分类
- 基于域名的虚拟主机
- 通过域名来区分虚拟主机
- 基于端口的虚拟主机
- 通过端口来区分虚拟主机
- 基于域名的虚拟主机
- 通过虚拟主机实现内网穿透
- 将主机的端口与子网下的IP进行绑定
- 然后通过访问主机的端口来实现访问子网下的IP
3.7.1 基于域名
这是Nginx比较常用的配置,通过修改Windows系统下的host文件来模拟DNS服务器
-
修改Window的 C:\Windows\System32\drivers\etchosts 文件,添加ip 域名映射关系,用来模拟DNS服务器
192.168.88.100 www.aaa8080.com 192.168.88.100 www.bbb18080.com -
修改Nginx配置文件
http { upstream miaosha { server 192.168.88.101:8080; server 192.168.88.102:8080; server 192.168.88.103:8080; } upstream fxhh { server 192.168.88.101:18080; server 192.168.88.102:18080; server 192.168.88.103:18080; } server { listen 80; server_name www.miaosha.bdp.com; location / { proxy_pass http://miaosha; } } server { listen 80; server_name www.fxhh.bdp.com; location / { proxy_pass http://fxhh; } } }
3.7.2 基于端口
-
修改Window的 C:\Windows\System32\drivers\etchosts 文件
192.168.88.100 www.bdp.com -
修改Nginx配置文件
http { upstream port12345 { server 192.168.88.101:8080; server 192.168.88.102:8080; server 192.168.88.103:8080; } upstream port54321 { server 192.168.88.101:18080; server 192.168.88.102:18080; server 192.168.88.103:18080; } server { listen 12345; server_name www.bdp.com; location / { proxy_pass http://port12345; } } server { listen 54321; server_name www.bdp.com; location / { proxy_pass http://port54321; } } }
3.7 Session一致性
3.8 高并发与一致性算法
3.8.1高并发
解决高并发的问题要从容量、读写性能和安全性这三个方面来考虑
1.磁盘阵列
解决高并发的容量问题
-
Raid介绍
- Redundant Arrays of Independent Disks( 独立磁盘冗余阵列 )
- RAID阵列技术允许将一系列磁盘分组,以实现为数据保护而必需的数据冗余,以及为提高读写性能而形成的数据条带分布
-
条带化
-
定义:
- 条带化技术就是将一块连续的数据分成很多小部分并把它们分别存储到不同的磁盘中
-
条带化出现的原因
-
大多数磁盘系统都对访问次数(每秒的 I/O 操作,IOPS)和数据传输率(每秒传输的数据量,TPS)有限制
-
当达到这些限制时,后面需要访问磁盘的进程就需要等待,这时就是所谓的磁盘冲突。
-
-
解决方案:条带化技术
- 运用条带化技术将一块连续的数据分成很多小部分,分别存储到不同的磁盘上
- 这就能够使多个进程同时访问数据的多个不同部分而不会造成磁盘冲突
- 在对这种数据进行顺序访问的时候可以获得最大程度上的I/O并行能力,从而获得非常好的性能
-
-
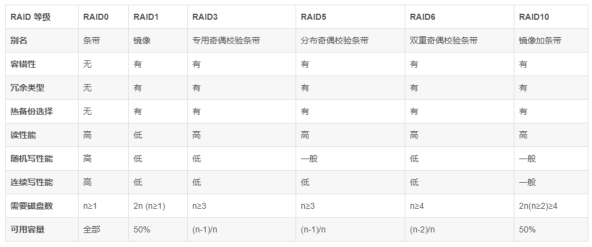
Raid的分类及作用
参考资料:RAID技术详解 - EFFOREFFOR - 博客园 (cnblogs.com)
最常用的是0、1、3、5四个级别
- Raid0
- 又称数据分块,即把数据分成若干相等大小的小块
- 低成本、高读写性能、 100% 的高存储空间利用率
- 不提供数据冗余保护,一旦数据损坏,将无法恢复
- 适用于对性能要求严格但对数据安全性和可靠性不高的应用,如视频、音频存储、临时数据缓存空间等
- Raid1
- RAID1 称为镜像,它将数据完全一致地分别写到工作磁盘和镜像磁盘,盘空间利用率为50%
- 数据写入时,响应时间会有所影响,但是读数据的时候没有影响
- 安全性高:如果一个磁盘的数据发生错误,或者硬盘出现了坏道,那么另一个硬盘可以补救回磁盘故障而造成的数据损失和系统中断。
- 镜象和双工的缺点是需要多出一倍数量的驱动器来复制数据,但系统的读写性能并不会由此而提高
- Raid2
- RAID2 称为纠错海明码磁盘阵列,其设计思想是利用海明码实现数据校验冗余。
- Raid0

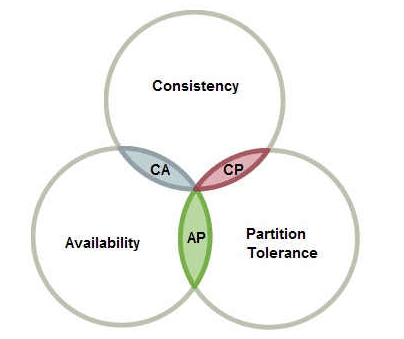
2.CAP原则
-
定义:
CAP原则又称CAP定理,指的是在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可得兼。
-
对CAP的理解
- Consistency(一致性)
- 系统在执行过某项操作后仍然处于一致的状态。在分布式系统中,更新操作执行成功后所有的用户都应该读取到最新值
- Availability(可用性)
- 在分布式环境下,整个集群所有的节点在指定时间内能不能返回统一的结果给用户使用。“一定时间内”“返回结果”
- Partition tolerance(分区容错性)
- 是否允许对数据进行分区和伸缩
- Consistency(一致性)
-
一致性与可用性的抉择(分区容忍性是必须要实现的)
CAP理论就是说在分布式存储系统中,最多只能实现上面的两点。而由于当前的网络硬件肯定会出现延迟丢包等问题,所以分区容忍性是我们必须需要实现的。所以我们只能在一致性和可用性之间进行权衡,没有NoSQL系统能同时保证这三点。
3.数据一致性
-
定义:
- 一些分布式系统通过复制数据来提高系统的可靠性和容错性,并且将数据的不同的副本存放在不同的机器
- 在数据有多分副本的情况下,如果网络、服务器或者软件出现故障,会导致部分副本写入成功,部分副本写入失败。这就造成各个副本之间的数据不一致,数据内容冲突。
-
一致性分类
- 强一致性
- 要求无论更新操作实在哪一个副本执行,之后所有的读操作都要能获得最新的数据
- 弱一致性
- 用户读到某一操作对系统特定数据的更新需要一段时间,我们称这段时间为“不一致性窗口”
- 最终一致性
- 是弱一致性的一种特例,保证用户最终能够读取到某操作对系统特定数据的更新
- 最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态
- 强一致性
-
最终一致性的5种分类
-
因果一致性
-
读己之所写一致性
-
会话一致性:
-
单调读一致性:
-
单调写一致性:
-
3.8.2 一致性算法
1.Paxos算法
-
提出原因:
- Paxos算法解决的问题是分布式一致性问题,即一个分布式系统中的各个进程如何就某个值(决议)达成一致
- Paxos是能够基于一大堆完全不可靠的网络条件下却能可靠确定地实现共识一致性的算法。也就是说:它允许一组不一定可靠的处理器(服务器)在某些条件得到满足情况下就能达成确定的安全的共识,如果条件不能满足也确保这组处理器(服务器)保持一致
-
分布式拍卖案例理解Paxo算法
在传统拍卖场景中,价高者先得,这些拍卖者都是在同一个房间,彼此能够直接看得到对方的报价,如果我们假设分布式拍卖是将这些拍卖者分离到不同的地方,这样我们可以用拍卖者之间的联系模拟分布式计算机之间的通讯。
假设拍卖者各自在自己家里拍卖,通过邮局信件发出自己的拍卖信息,拍卖者之间除非等到邮局投递人告诉他们彼此之间的报价,否则是无法知道对方报价的。如果邮局信件投递这个环节出了问题,投递速度慢了甚至无法投递了,那么整个拍卖程序就无法继续进行下去。
-
Paxos算法的解决的问题描述
假设有一组可以提出(propose)value(value在提案Proposal里)的进程集合。一个一致性算法需要保证提出的这么多value中,只有一个value被选定(chosen)。如果没有value被提出,就不应该有value被选定。如果一个value被选定,那么所有进程都应该能学习(learn)到这个被选定的value。对于一致性算法,安全性(safaty)要求如下:-
只有被提出的value才能被选定。
-
只有一个value被选定,并且如果某个进程认为某个value被选定了,那么这个value必须是真的被选定的那个。
Paxos的目标:保证最终有一个value会被选定,当value被选定后,进程最终也能获取到被选定的value
-
-
Paxos算法的过程(算法描述)
Paxos算法类似于两阶段提提交,其算法执行过程分为两个阶段。具体如下:
- 阶段一(prepare阶段):
- (a) Proposer选择一个提案编号N,然后向半数以上的Acceptor发送编号为N的Prepare请求。Pareper(N)
- (b) 如果一个Acceptor收到一个编号为N的Prepare请求,如果小于它已经响应过的请求,则拒绝,不回应或回复error。若N大于该Acceptor已经响应过的所有Prepare请求的编号(maxN),那么它就会将它已经接受过(已经经过第二阶段accept的提案)的编号最大的提案(如果有的话,如果还没有的accept提案的话返回{pok,null,null})作为响应反馈给Proposer,同时该Acceptor承诺不再接受任何编号小于N的提案。
- 阶段二(accept阶段):
- (a) 如果一个Proposer收到半数以上Acceptor对其发出的编号为N的Prepare请求的响应,那么它就会发送一个针对[N,V]提案的Accept请求给半数以上的Acceptor。注意:V就是收到的响应中编号最大的提案的value(某个acceptor响应的它已经通过的{acceptN,acceptV}),如果响应中不包含任何提案,那么V就由Proposer自己决定。
- (b) 如果Acceptor收到一个针对编号为N的提案的Accept请求,只要该Acceptor没有对编号大于N的Prepare请求做出过响应,它就接受该提案。如果N小于Acceptor以及响应的prepare请求,则拒绝,不回应或回复error(当proposer没有收到过半的回应,那么他会重新进入第一阶段,递增提案号,重新提出prepare请求)。
- 在上面的运行过程中,每一个Proposer都有可能会产生多个提案。但只要每个Proposer都遵循如上述算法运行,就一定能保证算法执行的正确性。
- 阶段一(prepare阶段):
-
无主集群模型
- 人人平等,每个人都可以提议,但是提议的编号重复率高
- 会造成活锁,即节点数正好是偶数,两个编号相同的决议各持有一半
- 因为最终一致性,议员数据不一定相同,将来其他节点同步数据的时候需要从多个节点同步数据
-
有主集群模型(总统议员)
- 只有一个人可以发送指令,解决了编号和同步的问题
- 如何第一次选择主节点
- 每个议员都有一个唯一的数字编号
- 最开始每个议员都想成为总统,他会把这个竞选消息发送给其他所有的议员
- 这些收到消息的议员只会投票给大于自己编号的人
- 于是当前环境下编号最大的议员就成了总统
- 缺点:
- 当前集群只有一个主节点,很容易发生单点故障,一旦出现单点故障,整个集群都会停止工作等待再次选举
- 有可能会产生多主脑裂的问题
- 如何进行后续的选举
- 所有的节点都开始竞选,每个议员都想成为总统
- 这些收到消息的议员会把票投给(事物编号大于自己并且数字编号也大于自己的议员)
- 事物编号–数字编号,都是为了最快速度选出总统
- 选举速率与节点数量
- 节点越多,业务处理能力越强,但是选举的速度越慢
- 需要减少参与选举和投票的人数
参考资料:分布式系统Paxos算法 - 下里巴人or知己 - 博客园 (cnblogs.com)
Paxos算法原理和过程解析_小诚信驿站的博客-CSDN博客_paxos算法














 861
861











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









