





一说起机器学习,同学们的第一反应一般是: 哇,机器学习这么高大上的技术,一定很难吧。

说实话,机器学习的理论知识,对于非科班出身的同学们来说,确实就像是天书一样,小编还记得以前硬啃西瓜书从入门到放弃的惨痛经历。
但是,还好,我们有python这个强大的工具。有了python, 机器学习不再痛苦。
今天, 咱们就来学习一下,如何用25行python代码,实现一个简单的机器学习项目。
python环境
python环境肯定是必须的啦, 推荐使用python3.x, 比如小编电脑上安装的就是python3.7
为什么不推荐python2呢, 因为, python官方宣布 2020 年 1 月后不再更新维护 Python2了。
机器学习lib包

python里面有3个极其强大的机器学习lib包, 小编喜欢把他们称作 ”机器学习三剑客“:
1) numpy: 简称np, 主要用于矩阵计算。 听到矩阵两个字,是不是又感觉很难了, 不要急,这个机器学习项目不涉及矩阵计算~
2) pandas: 简称pd, 它是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具和方法。 听起来也挺复杂的,不过大家也不用担心, 我们只是用它来读取csv文件~
3) sklearn: 原文是scikit-learn (简称 sklearn) 它是基于 Python 语言的机器学习工具, 里面有各种模型,各种工具,基本上都是几行代码就可以实现c++里面极其复杂的功能,堪称“神器“.
这几个包的安装,推荐是使用pip来安装,网速不快的话,可以使用国内的源~, 具体方法本文就不再详述了,百度一下有茫茫多的教程。
项目背景

在泰坦尼克沉船事故中, 有些乘客遇难,有些乘客则成功获救。
训练数据集中记录了乘客的个人信息以及是否获救,
我们需要根据这些数据尝试训练合适的模型,用于预测测试集中的乘客是否可以获救。
这个问题本质上是一个二分类的问题。
数据集说明
数据集分为训练集和测试集,字段共有12个:
PassengerId, 乘客ID
Survived, 是否获救
Pclass, 舱位等级
Name, 乘客名称
Sex, 性别
Age, 年龄
SibSp, 兄弟姐妹个数
Parch, 父母小孩个数
Ticket, 船票文本信息
Fare, 票价
Cabin, 客舱
Embarked 登船港口
其中,Survived字段就是我们要预测的字段, 取值为0或者1。
下面看一段数据:
train.csv:
PassengerId,Survived,Pclass,Name,Sex,Age,SibSp,Parch,Ticket,Fare,Cabin,Embarked
1,0,3,"Braund, Mr. Owen Harris",male,22,1,0,A/5 21171,7.25,,S
2,1,1,"Cumings, Mrs. John Bradley (Florence Briggs Thayer)",female,38,1,0,PC 17599,71.2833,C85,C
3,1,3,"Heikkinen, Miss. Laina",female,26,0,0,STON/O2. 3101282,7.925,,S
test.csv:
PassengerId,Pclass,Name,Sex,Age,SibSp,Parch,Ticket,Fare,Cabin,Embarked
892,3,"Kelly, Mr. James",male,34.5,0,0,330911,7.8292,,Q
893,3,"Wilkes, Mrs. James (Ellen Needs)",female,47,1,0,363272,7,,S
894,2,"Myles, Mr. Thomas Francis",male,62,0,0,240276,9.6875,,Q
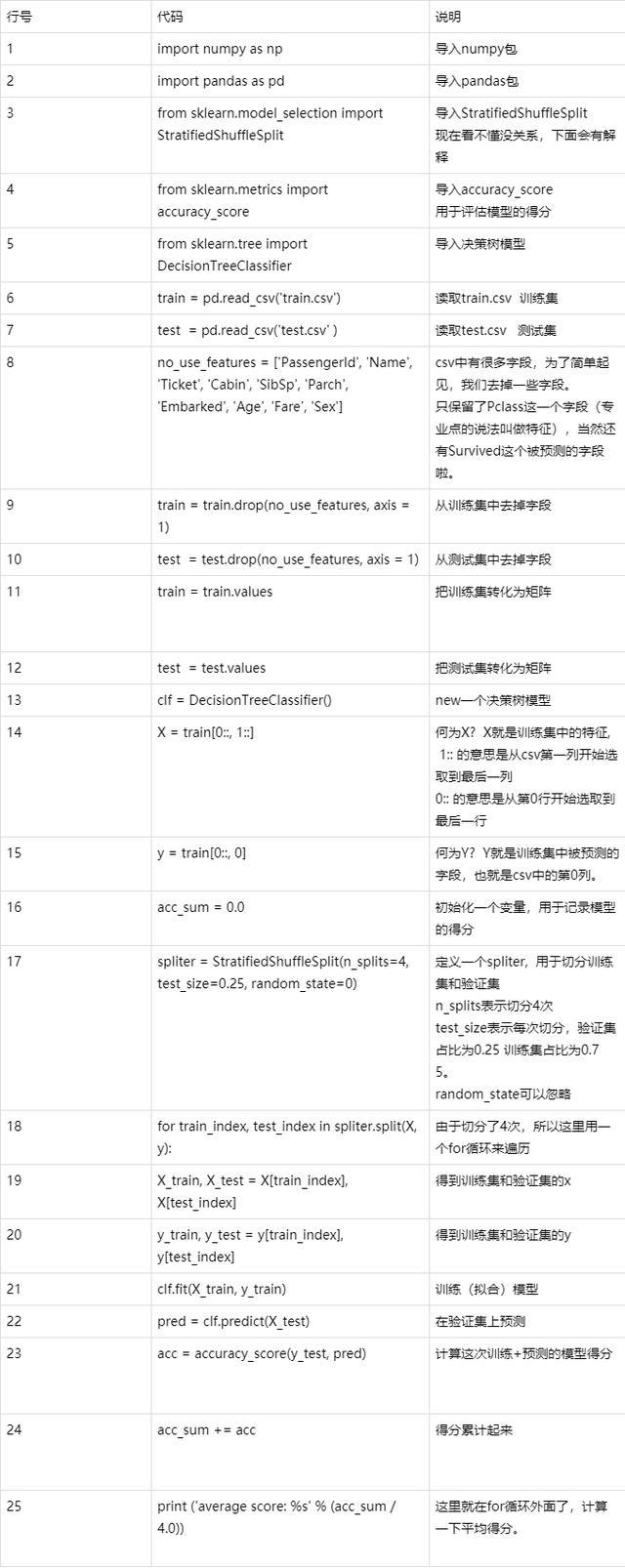
代码解析
敲黑板,进入重点了,大家注意听,让我们来一行一行地解析这25行代码。
运行结果
python ML.py
average score: 0.6547085201793722
模型性能
说到性能,程序员们通常都会想到“cpu idle”,或者 “运行时间”,“内存占用”等。 但是,对于一个机器学习项目, 其性能指的是准确率得分(accuracy_score), 得分越接近于1.0, 就认为模型的性能越好。
后记
通过上面的运行结果,我们知道这个25行代码的决策树模型的得分为0.65,距离1.0还比较遥远。
但是,一个完整的机器学习项目已经实现了。
在以后的文章中,小编会继续介绍如何优化这个模型的性能,提前透露一下,最终模型的得分可以达到0.97,是不是很棒。














 924
924











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









