






本系列简单梳理一下《Deep Visual Domain Adaptation: A Survey》这篇综述文章的内容,囊括了现在用深度网络做领域自适应DA(Domain Adaptation)的各个方面的一些文章。
原文链接:Deep Visual Domain Adaptation: A Survey
Class Criterion
类别准则:使用标签信息作为指导在不同领域之间迁移知识
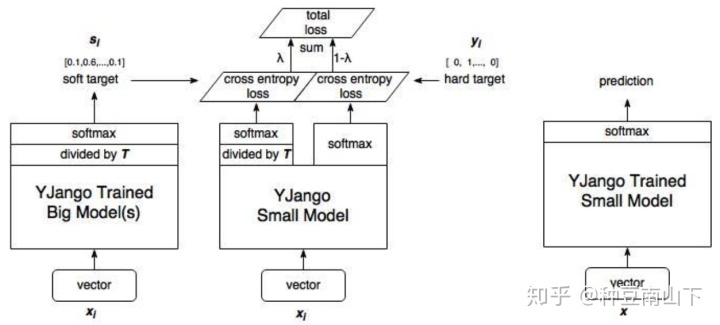
- Distilling the knowledge in a neural network
Hinton 2015年的工作,distilling knowledge是一个实用的trick,使用软标签soft label替代硬标签hard label将不同类别之间的关系保存。这种关系可以从源域迁移到目标域。
- Simultaneous deep transfer across domains and tasks.
源域有label,目标域有少量label。在普通的domain adaptation分类器与域判别器的基础上,再加一个soft label判别器,迁移源域中类别的关系信息。通过源域训练的分类器,对源域数据进行分类,得到不同类别之间的关系(比如一共三个类别,瓶子、水杯、键盘,那么如果水杯的概率是0.6,瓶子可能是0.3,键盘是0.1,由此看出水杯和瓶子联系更紧密)。所以对于目标域中的标签是水杯的数据,我们希望训练出来的 {水杯,瓶子,键盘} = {0.6, 0.3, 0.1} 而不是one-hot的 {1, 0, 0} ,这样视为将label之间的关系也进行了迁移,可以通过这些少数的目标域label对网络进行fine-tune。
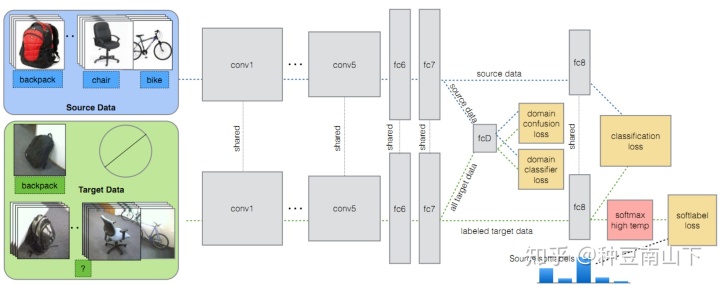
- Fine-grained Recognition in the Wild: A Multi-Task Domain Adaptation Approach
源域有label,目标域有少量label。在上篇文章的基础上,将soft label判别器加入细粒度识别任务。细粒度识别就是比较精细的图像识别,比如识别的是不同品种的狗,不同牌子的汽车等。
- Deep Transfer Metric Learning
源域有label,目标域无label。结合线性判别分析(LDA)和最大均值差异(MMD),将源域和目标域距离尽量近(MMD约束)的情况下,类内距离最小,类间距离最大(LDA约束)。
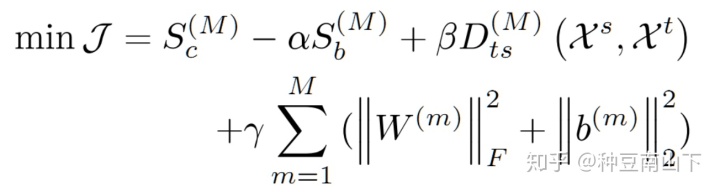
- Unified Deep Supervised Domain Adaptation and Generalization
源域有label,目标域有少量label。。这篇文章在域判别的时候构造了语义对齐损失(即类内差距)和分离损失(即类间差距),用上了目标域label的信息。一般的DA方法,无法保证在特征空间里,不同domain里相同label的数据特征是一样的。即源域第一类数据特征可能经过映射后和目标域第二类一样。作者还利用了一些技巧,使得即使只有一个目标与域样本的情况下,也能对模型起到改善作用。
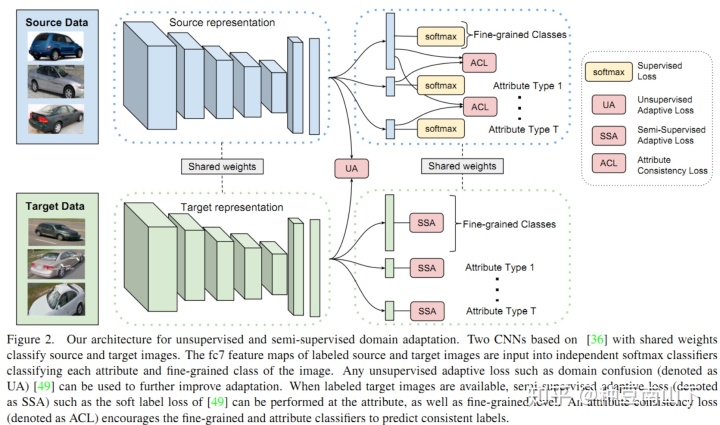
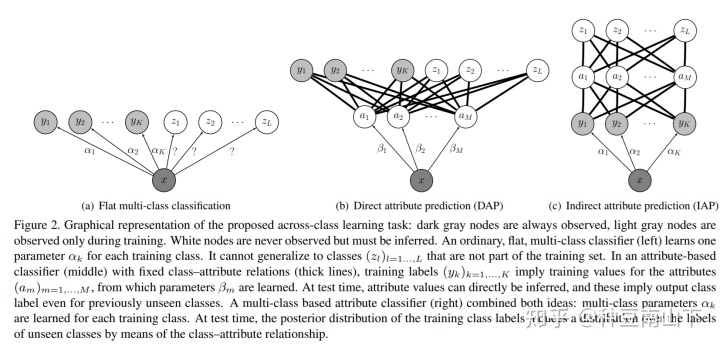
- Learning To Detect Unseen Object Classes by Between-Class Attribute Transfer
源域有label,目标域无label也无数据。使用高层次的语义属性,识别没有见过的label。但是需要人工定义属性层,属于这方面开创性的工作。
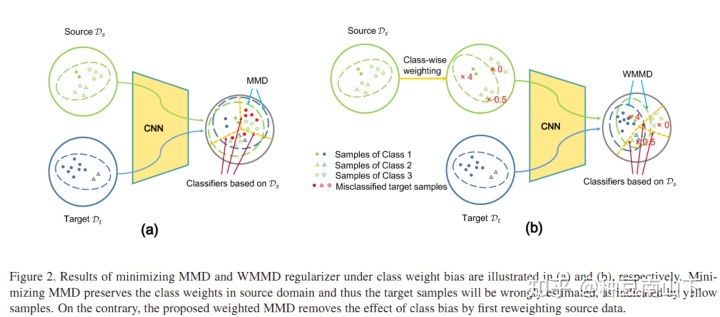
- Mind the Class Weight Bias: Weighted Maximum Mean Discrepancy for Unsupervised Domain Adaptation
提出了weighted MMD模型。源域有label,目标域无label,设计伪标签。考虑源域label的先验分布与目标域的不一样,设置pseudo-label,提出weighted MMD模型。利用CEM(classification EM algorithm)算法进行优化求解。主要的贡献有两个点:
第一,提出weighted MMD模型,将MMD度量改为如下形式:
其中,
第二, 利用CEM算法进行求解,其实是本质是解一个非凸问题,所以要用类似EM算法的机制。首先E步,通过源域训练CNN求出目标域的后验概率
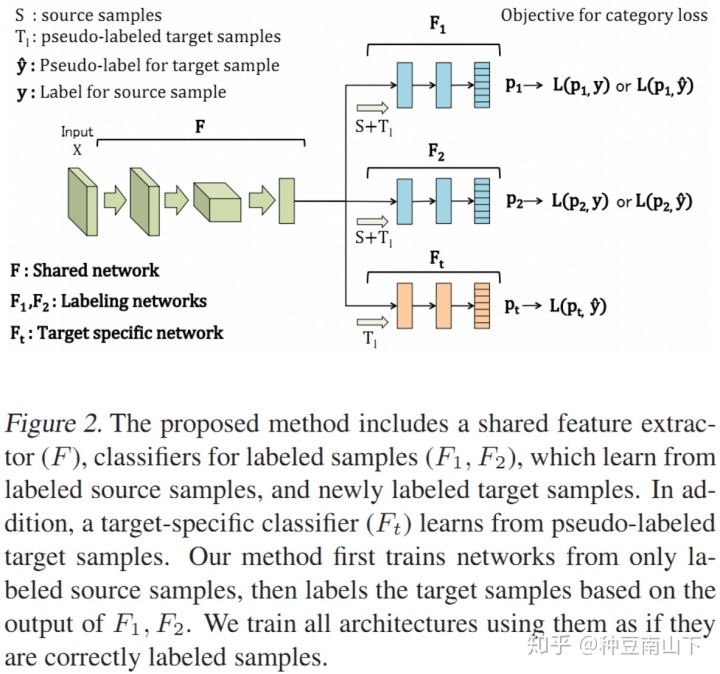
- Asymmetric tri-training for unsupervised domain adaptation
源域有label,目标域无label,设计伪标签。设计三个网络,
- Deep transfer network: Unsupervised domain adaptation
这篇文章提出了DTN方法。源域有label,目标域无label,设计伪标签。不同之处在于,假设条件分布
其中边缘分布MMD为:
条件分布MMD为:
但是要想计算

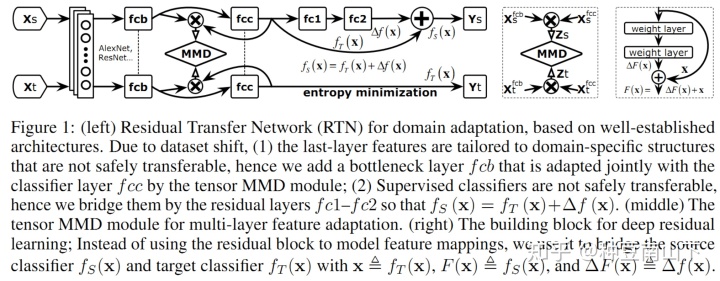
- Unsupervised Domain Adaptation with Residual Transfer Networks
源域有label,目标域无label,设计伪标签。作者假设源域和目标域的条件分布也有差异,也就是特征空间里面同样的一个点
如有错误,欢迎交流指正。^_^
转载请注明出处!!^_^
知乎:种豆南山下
个人学术主页:
About mewww.caokai.site
Domain Adaptation系列文章:
种豆南山下: 迁移学习: 领域自适应(Domain Adaptation)的理论分析
种豆南山下: Domain Adaptation:不用深度网络,如何处理源域和目标域异构问题?
种豆南山下: Deep Domain Adaptation论文集(一):基于label迁移知识
种豆南山下: Deep Domain Adaptation论文集(二):基于统计差异
种豆南山下: Deep Domain Adaptation论文集(三):基于深度网络结构差异&几何差异
种豆南山下: Deep Domain Adaptation论文集(四):基于生成对抗网络GAN
种豆南山下: Deep Domain Adaptation论文集(五):基于数据重构的迁移方法
种豆南山下: Deep Domain Adaptation论文集(六):源域与目标域特征空间不一致的处理方法















 4273
4273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









