






大数据归档-冷热数据分离
虽然之前我们的数据是分散在不同的分片中,但是日积月累分片中的数据越来越多,数据迁移的成本就大大提高,所以能不能将数据进行分离。
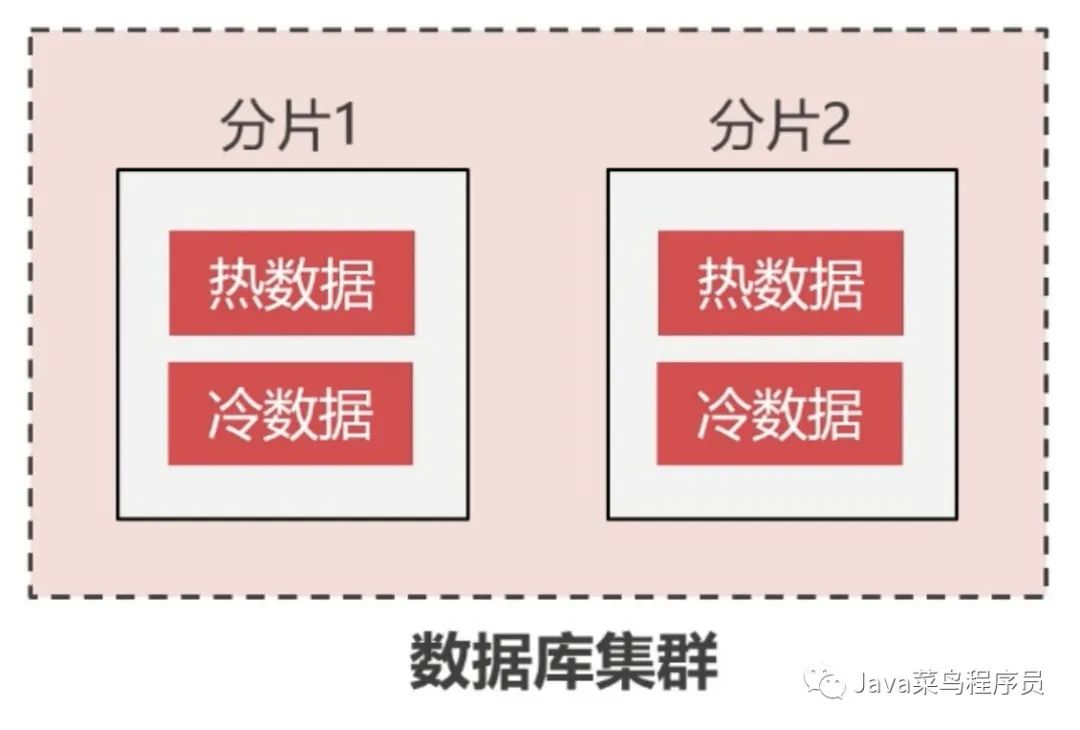
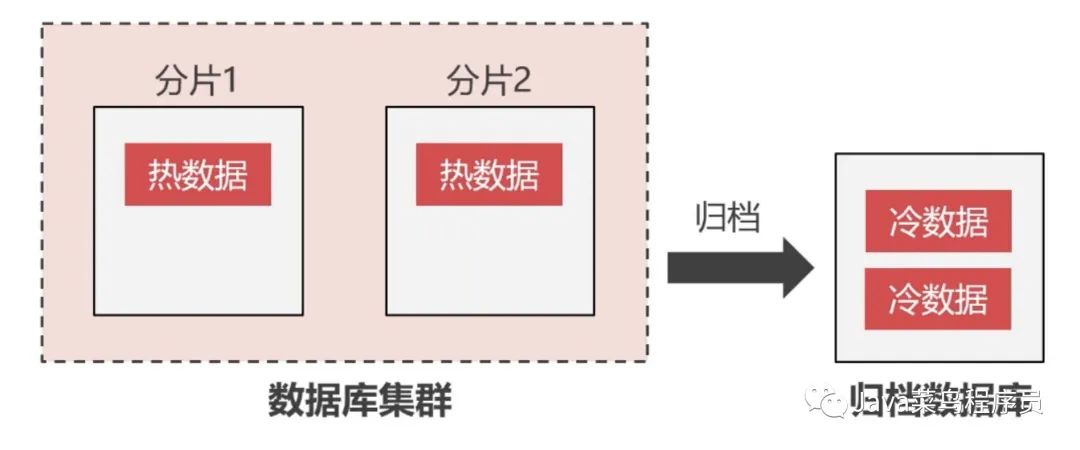
我们可以将很少使用到的数据,从分片中归档到归档数据库中。
InnoDB 写入慢的原因
因为 InnoDB 本身使用的是 BTree 索引,正因为如此,每次写入都需要用 IO 进行索引树的重排。特别是当数据量特别大的时候,效率并不够高。
什么是 TokuDB
TokuDB 是一个支持事务的“新”引擎,有着出色的数据压缩功能,由美国 TokuTek 公司(现在已经被 Percona 公司收购)研发。拥有出色的数据压缩功能,如果我们的数据写多读少,而且数据量比较大,我们就可以使用 TokuDB,以节省空间成本,并大幅度降低存储使用量和 IOPS 开销,不过相应的会增加 CPU 的压力。
特点:
- 高压缩比,高写入性能,(可以达到压缩比 1:12,写入速度是 InnoDB 的 9~20 倍)
- 在线创建索引和字段
- 支持事务
- 支持主从同步
安装 TokuDB
在之前的文章(一)中单独安装过 percona 数据库,我们现在不再重新安装 Percona 数据库。
安装 jemalloc 库
yum install -y jemalloc
修改 my.cnf
vim /etc/my.cnf
在mysqld_safe节点下增加 malloc-lib。
……
[mysqld_safe]
malloc-lib=/usr/lib64/libjemalloc.so.1
……
然后启动 MySQL 服务。
systemctl restart mysqld
开启 Linux 大页内存
为了保证 TokuDB 的写入性能,我们需要关闭 linux 系统的大页内存管理,默认情况下 linux 的大页内存管理是在系统启动时预先分配内存,系统运行时不再改变了。
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/defrag
安装 TokuDB
版本必须和 Percona 的版本一致,我们前面安装的是 Percona5.7,所以此处也需要安装 toku5.7,否则提示版本冲突。
yum install -y Percona-Server-tokudb-57.x86_64
输入 Mysql 的 root 帐号密码,完成启动。
ps-admin --enable -uroot -p
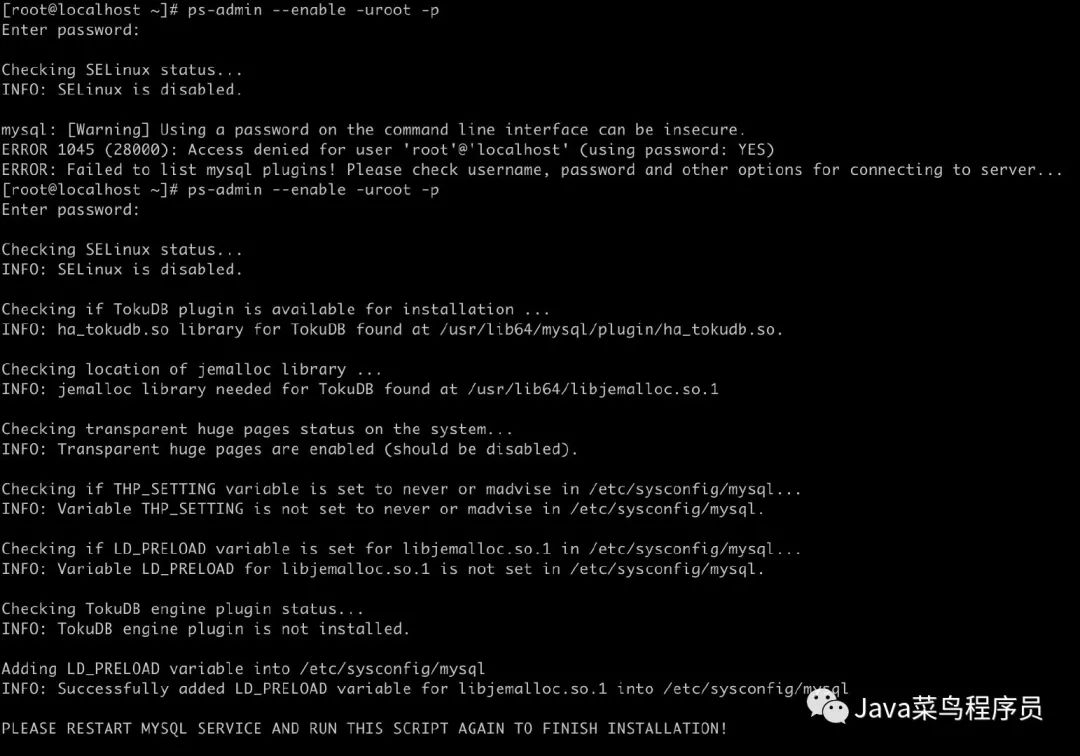
启动完成之后重启一下 mysql
systemctl restart mysqld
重启之后再激活一次 tokudb,重新执行一下命令
ps-admin --enable -uroot -p
查看 TokuDB 引擎是否安装成功
进入 MySQL:
mysql -u root -p
执行 show engines;
show engines;
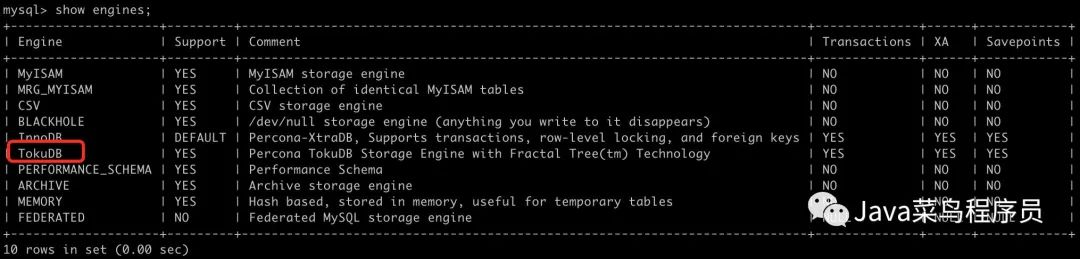
成功之后,另一台虚拟机也是同样步骤。
使用 TokuDB 引擎
如果是 sql 语句建表,只需要在语句的结尾加上ENGINE = TokuDB ,注意只能使用 sql 语句创建表才有效。
CREATE TABLE student(
.........
) ENGINE = TokuDB;
归档库的双机热备
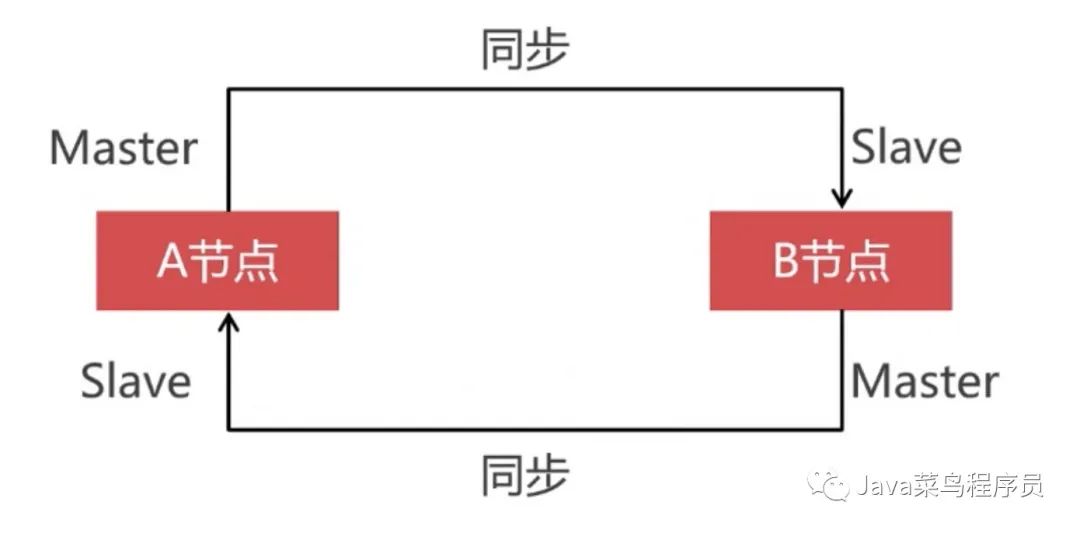
我们选用两个 Percona 数据库节点组成 Replication 集群,这两个节点配置成双向同步,因为 Replication 集群的主从同步是单向的,如果配置成单向的主从同步,主库挂掉以后,我们还可以向从库写入数据,但是主库恢复之后主库是不会像从库那同步数据的,所以两个节点的数据不一致,如果我们配置成双向同步,无论哪一个节点宕机了,在上线的时候他都会从其他的节点同步数据。这就可以保证每一个节点的数据是一致的。当然这个一致性是弱一致性,跟 PXC 集群的强一致性有本质区别的。

由于已经启动了 8 台虚拟机了,为了节省硬件资源,每个 PXC 节点我只启动一个 PXC 节点,和一个 MyCat 实例,这样就只有三台虚拟机同时运行。
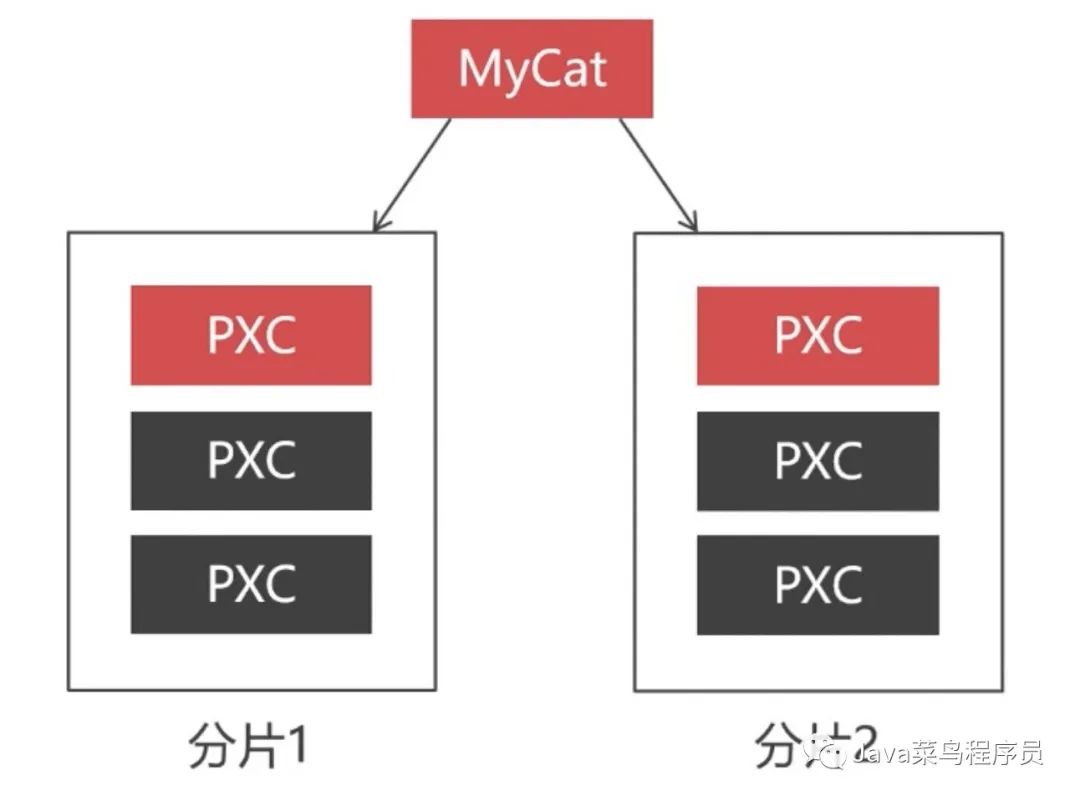
另外别忘记了,在 MyCat 的配置文件中需要将 balance=0 ,然后将用不到的 PXC 节点删除掉。
vim schema.xml
<?xml version="1.0"?>
mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="test" checkSQLschema="false" sqlMaxLimit="100">
<table name="t_test" dataNode="dn1,dn2" rule="mod-long" />
<table name="t_user" dataNode="dn1,dn2" rule="mod-long" />
<table name="t_customer" dataNode="dn1,dn2" rule="sharding-customer">
<childTable name="t_orders" primaryKey="ID" joinKey="customer_id" parentKey="id"/>
table>
schema>
<dataNode name="dn1" dataHost="cluster1" database="test" />
<dataNode name="dn2" dataHost="cluster2" database="test" />
<dataHost name="cluster1" maxCon="1000" minCon="10" balance="0"writeType="1" dbType="mysql" dbDriver="native" switchType="1"slaveThreshold="100">
<heartbeat>select user()heartbeat>
<writeHost host="W1" url="192.168.3.137:3306" user="admin"password="Abc_123456">
writeHost>
dataHost>
<dataHost name="cluster2" maxCon="1000" minCon="10" balance="0"writeType="1" dbType="mysql" dbDriver="native" switchType="1"slaveThreshold="100">
<heartbeat>select user()heartbeat>
<writeHost host="W1" url="192.168.3.141:3306" user="admin"password="Abc_123456">
writeHost>
dataHost>
mycat:schema>
最后重启 MyCat。
./mycat start
配置 Replication 集群
Replication 集群同步原理
当我们在 Master 节点写入数据,Master 会把这次操作会记录到 binlog 日志里边,Slave 节点会有专门的线程去请求 Master 发送 binlog 日志,然后 Slave 节点上的线程会把收到的 Master 日志记录在本地 realy_log 日志文件中,slave 节点通过执行 realy_log 日志来实现数据的同步,最后把执行过的操作写到本地的 binlog 日志里。
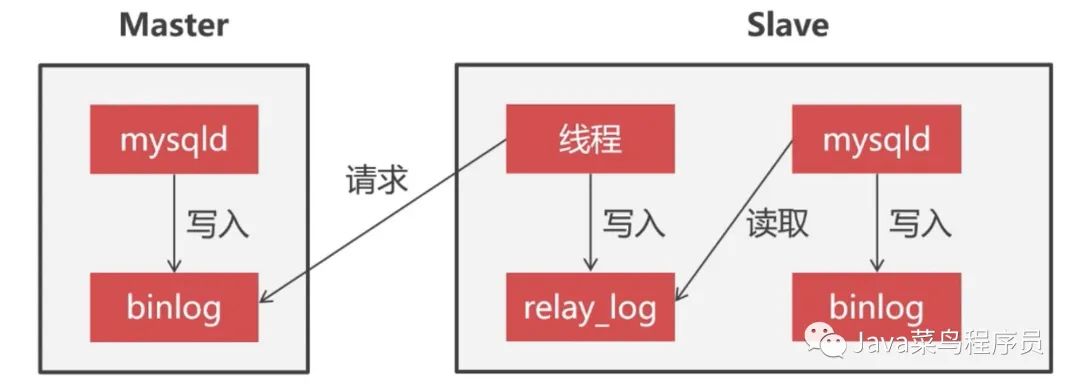
通过上图我们能总结出 Replication 集群的数据同步是单向的,我们在 Master 上写入数据,在 slave 上可以同步到这些数据,但是反过来却不行,所以要实现双向同步,两个数据库节点互为主从关系才行。
创建同步账户
我们给两个节点的数据库都创建上一个同步数据的账户。
CREATE USER 'backup'@'%' IDENTIFIED BY 'Abc_123456' ;
GRANT super, reload, replication slave ON *.* TO 'backup'@'%' ;
FLUSH PRIVILEGES ;
修改两个 TokuDB 的配置文件
vim /etc/my.cnf
[mysqld]
server_id = 101
log_bin = mysql_bin
relay_log = relay_bin
……
[mysqld]
server_id = 102
log_bin = mysql_bin
relay_log = relay_bin
重启 MySQL
systemctl restart mysqld
配置主从同步
我的 A 节点为:192.168.3.151
B 节点为:192.168.3.152
我们先在 B 节点上关闭主从同步的服务。
#关闭同步服务
stop slave;
#设置同步的Master节点
change master to master_host="192.168.3.151",master_port=3306,master_user="backup",
master_password="Abc_123456";
#启动同步服务
start slave;
#查看同步状态
show slave status\G;
如果看到下图 Slave_IO_Running 和 Slave_SQL_Running都为 yes 即说明配置成功。

然后我们去 A 节点进行上述配置,将master_host="192.168.3.152"改为 152 即可。这样我们就实现了双向同步。
创建归档表
因为是双向同步,我们在哪一个节点创建归档表,另一个节点都会同步到数据。
CREATE DATABASE test;
use test;
CREATE TABLE t_purchase_202011 (
id INT UNSIGNED PRIMARY KEY,
purchase_price DECIMAL(10,2) NOT NULL,
purchase_num INT UNSIGNED NOT NULL,
purchase_sum DECIMAL (10,2) NOT NULL,
purchase_buyer INT UNSIGNED NOT NULL,
purchase_date TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
company_id INT UNSIGNED NOT NULL,
goods_id INT UNSIGNED NOT NULL,
KEY idx_company_id(company_id),
KEY idx_goods_id(goods_id)
)engine=TokuDB;
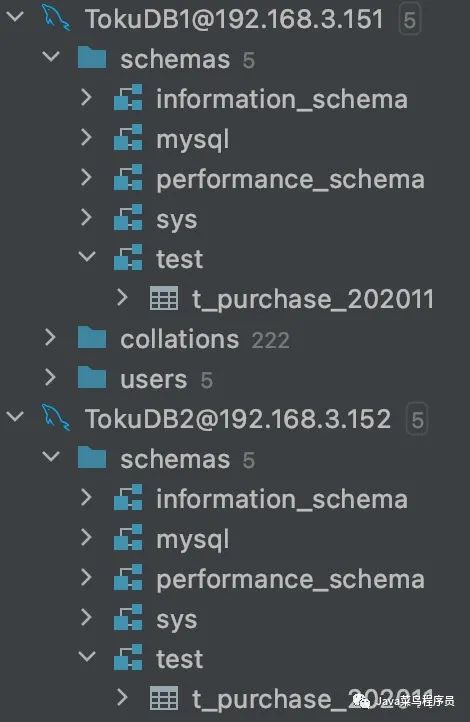
搭建 Haproxy
之前文章已经安装过 Haproxy 了,这里就不在啰嗦了。两个节点一样的步骤。
yum install -y haproxy
修改配置文件:
vim /etc/haproxy/haproxy.cfg
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
listen admin_stats
bind 0.0.0.0:4001
mode http
stats uri /dbs
stats realm Global\ statistics
stats auth admin:abc123456
listen proxy-mysql
bind 0.0.0.0:4002
mode tcp
balance roundrobin
#日志格式
option tcplog
server backup_1 192.168.3.151:3306 check port 3306 maxconn 2000
server backup_2 192.168.3.152:3306 check port 3306 maxconn 2000
#使用keepalive检测死链
option tcpka
开启防火墙的 VRRP 协议,开启 4001 端口和 4002 端口。
firewall-cmd --direct --permanent --add-rule ipv4 filter INPUT 0 --protocol vrrp -j ACCEPT
firewall-cmd --zone=public --add-port=4001/tcp --permanent
firewall-cmd --zone=public --add-port=4002/tcp --permanent
firewall-cmd --reload
启动 Haproxy
service haproxy start
浏览器访问如下地址即可访问:
http://192.168.3.151:4001/dbs
如下图:即说明成功,两个节点都看一下。
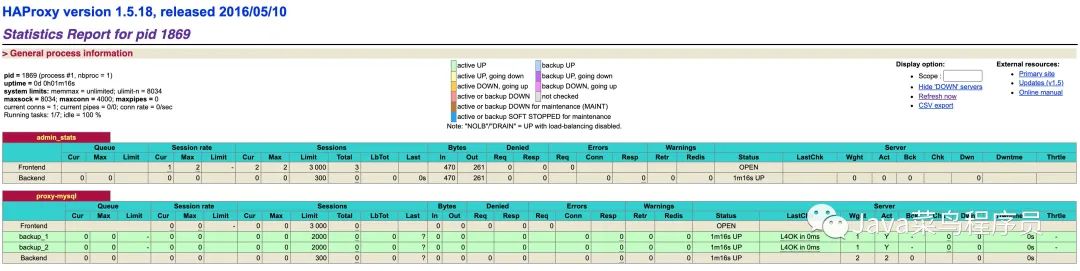
搭建 Keepalived
还是在两台节点上一样的操作。
yum install -y keepalived
编辑配置文件:
vim /etc/keepalived/keepalived.conf
vrrp_instance VI_1 {
state MASTER
interface enp0s3
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 123456
}
virtual_ipaddress {
192.168.3.177
}
}
配置说明:
state MASTER:定义节点角色为 master,当角色为 master 时,该节点无需争抢就能获取到 VIP。集群内允许有多个 master,当存在多个 master 时,master 之间就需要争抢 VIP。为其他角色时,只有 master 下线才能获取到 VIPinterface enp0s3:定义可用于外部通信的网卡名称,网卡名称可以通过ip addr命令查看virtual_router_id 51:定义虚拟路由的 id,取值在 0-255,每个节点的值需要唯一,也就是不能配置成一样的priority 100:定义权重,权重越高就越优先获取到 VIPadvert_int 1:定义检测间隔时间为 1 秒authentication:定义心跳检查时所使用的认证信息auth_type PASS:定义认证类型为密码auth_pass 123456:定义具体的密码
virtual_ipaddress:定义虚拟 IP(VIP),需要为同一网段下的 IP,并且每个节点需要一致
完成以上配置后,启动 keepalived 服务:
service keepalived start
我们 ping 一下我们的虚拟地址试试,也是 OK 的!
使用数据库连接工具测试,也是 OK 的!
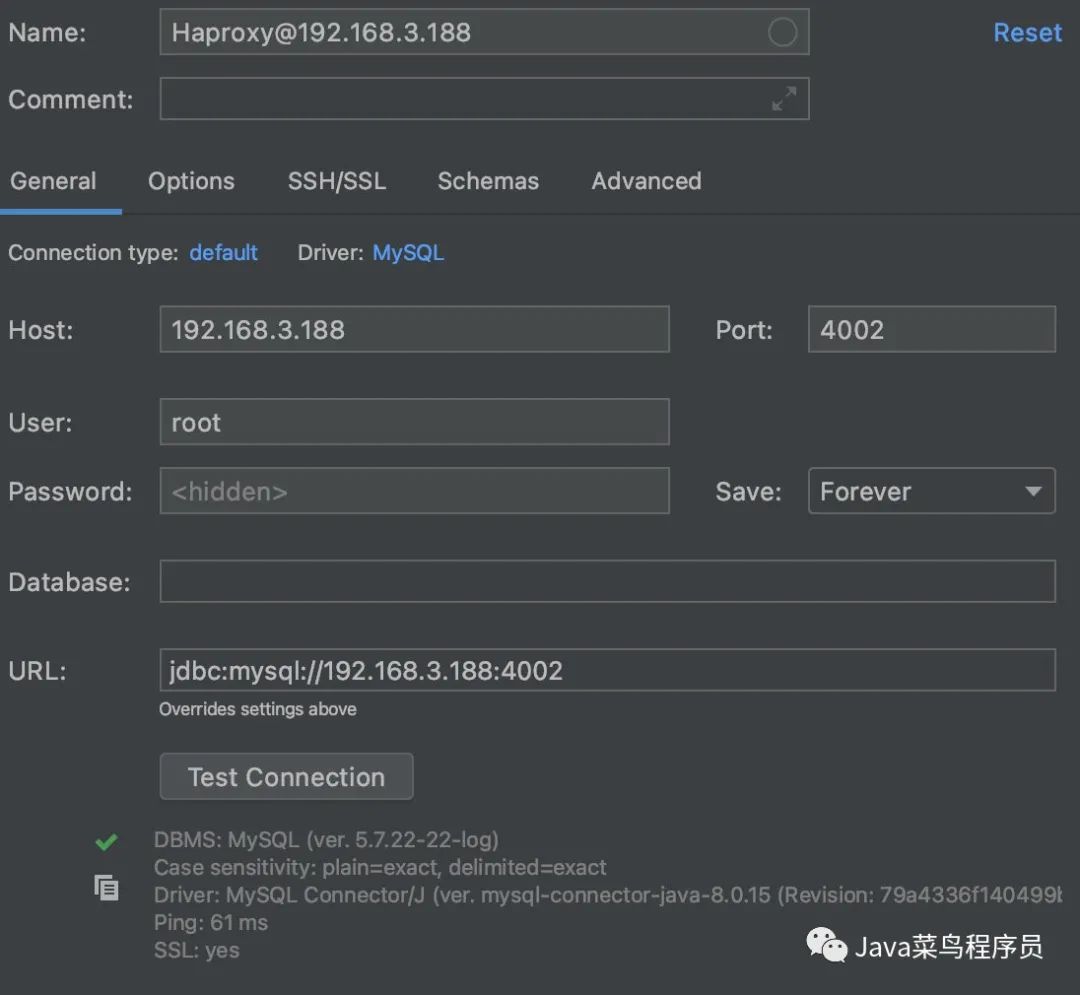
现在即使哪一台挂掉,都不会影响高可用。上一篇文章中已经演示了,这里就不再演示了。
准备归档数据
我们在 PXC 的两个分片中,创建一个进货表,注意这里创建进货表时没指定 tokuDB 引擎。(如果不知道两个 PXC 分片的话查看之前文章)
use test;
CREATE TABLE t_purchase (
id INT UNSIGNED PRIMARY KEY,
purchase_price DECIMAL(10,2) NOT NULL,
purchase_num INT UNSIGNED NOT NULL,
purchase_sum DECIMAL (10,2) NOT NULL,
purchase_buyer INT UNSIGNED NOT NULL,
purchase_date TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
company_id INT UNSIGNED NOT NULL,
goods_id INT UNSIGNED NOT NULL,
KEY idx_company_id(company_id),
KEY idx_goods_id(goods_id)
)
修改 MyCat 配置文件
增加了表之后,我们需要在 MyCat 的配置文件中增加该表:
<table name="t_purchase" dataNode="dn1,dn2" rule="mod-long" />
然后重启 MyCat。
./mycat restart
然后我使用 Java 代码来进行批量插入数据,这次没有使用 LoadData,大家可以对比一下 10 万条数据,和 1000 万条数据的时间差。
/**
* @author 又坏又迷人
* 公众号: Java菜鸟程序员
* @date 2020/11/27
* @Description:
*/
public class InsertDB {
public static void main(String[] args) throws SQLException {
DriverManager.registerDriver(new Driver());
String url = "jdbc:mysql://192.168.3.146:8066/test";
String username = "admin";
String password = "Abc_123456";
Connection connection = DriverManager.getConnection(url, username, password);
String sql = "insert into t_purchase(id, purchase_price, purchase_num, purchase_sum, purchase_buyer, purchase_date, company_id, goods_id)" +
" VALUES (?,?,?,?,?,?,?,?)";
connection.setAutoCommit(false);
PreparedStatement pst = connection.prepareStatement(sql);
for (int i = 0; i 100000; i++) {
pst.setObject(1, i);
pst.setObject(2, 5.0);
pst.setObject(3, 100);
pst.setObject(4, 500.0);
pst.setObject(5, 12);
pst.setObject(6, "2020-11-27");
pst.setObject(7, 20);
pst.setObject(8, 9);
pst.addBatch();
if (i % 2000 == 0) {
pst.executeBatch();
connection.commit();
}
}
pst.close();
connection.close();
System.out.println("执行结束");
}
}
安装归档工具
Percona 公司为我们提供了一套非常便捷的工具包 Percona-Toolkit,这个工具包包含了用于数据归档的pt-archiver,用这个归档工具我们可以轻松的完成数据的归档。
pt-archiver 的用途
- 导出线上数据,到线下数据作处理
- 清理过期数据,并把数据归档到本地归档表中,或者远端归档服务器
下载:
yum install -y percona-toolkit --nogpgcheck

执行归档
pt-archiver --source h=192.168.3.146,P=8066,u=admin,p=Abc_123456,D=test,t=t_purchase --dest h=192.168.3.188,P=3306,u=root,p=123456,D=test,t=t_purchase_202011 --no-check-charset --where 'purchase_date="2020-11-27 00:00:00"' --progress 5000 --bulk-delete --bulk-insert --limit=10000 --statistics
- --source h=192.168.3.146, P=8066, u=admin, p=Abc_123456, D=test, t=t_purchase 代表的是取哪个服务器的哪个数据库的哪张表的
- --dest h=192.168.3.188, P=3306, u=root, p=123456, D=test, t=t_purchase_202011 代表的是归档库的连接信息
- --no-check-charset 代表的是归档过程中我们不检查数据的字符集
- --where 归档数据的判断条件
- --progress 5000 每归档 5000 条数据往控制台打印一下状态信息
- --bulk-delete 批量的删除归档数据
- --bulk-insert 批量的新增归档数据
- limit=10000 批量一万条数据进行一次归档
- --statistics 打印归档的统计信息
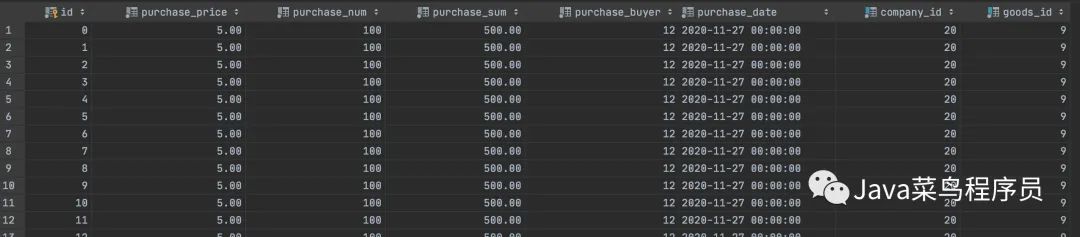
执行完成后,可以看到在 MyCat 节点进行查询已经没有数据了。
在我们的 ToKuDB 的 Haproxy 虚拟节点上查询可以看到数据已经都过来了。
小结
- 使用 TokuDB 引擎保存归档数据,拥有高速写入特性
- 使用双机热备方案搭建归档库,具备高可用性
- 使用 pt-archiver 执行归档数据,简便易行
数据分区
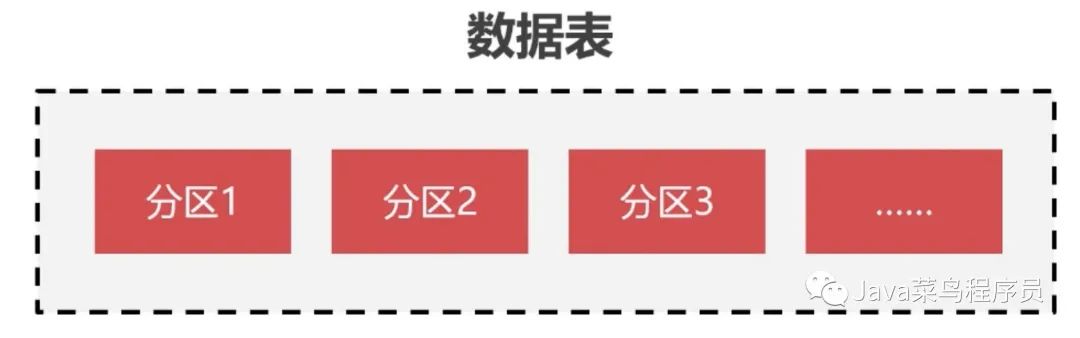
什么是表分区
表分区就是按照特定的规则,将数据分成许多小块,存储在磁盘中不同的区域,通过提升磁盘 IO 能力来加快查询的速度。
分区不会更改数据表的结构,发生变化的只是存储方式。从逻辑上看还是一张表,但底层是由多个物理分区来组成的。我们可以按照不同的方式来进行切分。
表分区的优缺点
优点:
- 表分区的数据可以分布在不同的物理设备上,从而高效地利用多个硬件设备
- 单表可以存储更多的数据
- 数据写入和读取的效率提高,汇总函数计算速度也变快了
- 不会出现表锁,只会锁住相关分区
缺点:
- 不支持存储过程、存储函数和某些特殊函数
- 不支持按位运算符
- 分区键不能子查询
- 创建分区后,尽量不要修改数据库模式
为什么在集群中引入表分区
当热数据过多的情况下,我们增加一个 PXC 分片,就要花费三台服务器。而且还要数据迁移。

如果我们使用表分区的话,我们可以给每个分区增加一个硬盘。这样我们就可以用少量的分片就可以存储更多的热数据。
挂载硬盘
这里我们还是使用每个 PXC 集群中一个节点。
给虚拟机增加两个硬盘这里就不再演示了,根据不同的虚拟机进行配置就好。
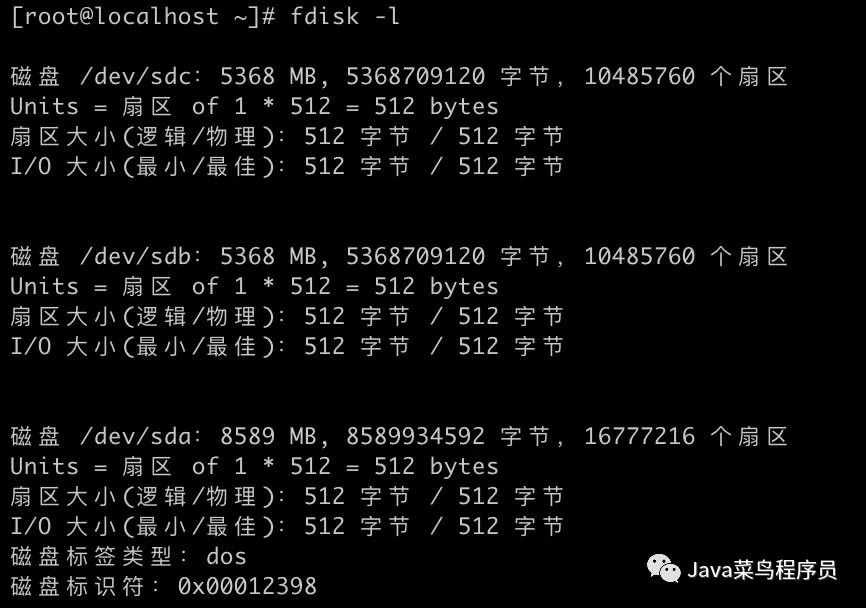
完成后 执行命令可以看到,三块硬盘已经被识别。
fdisk -l
然后我们进行分区
fdisk /dev/sdb
- n:创建新分区
- d:删除分区
- p:列出分区表
- w:把分区表写入硬盘并退出
- q:退出而不保存
然后根据图中的步骤即可:

然后格式化分区
mkfs -t ext4 /dev/sdb1
接下来修改文件进行挂载。
vim /etc/fstab
最下面追加内容:
/dev/sdb1/ /mnt/p0 ext4 defaults 0 0
执行完成后进行重启
reboot
查看是否挂载成功。
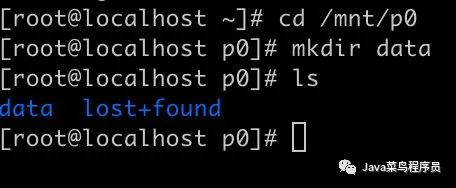
没有问题,之后我们就把数据存储在 data 文件夹中。
之后再创建第三块硬盘分区
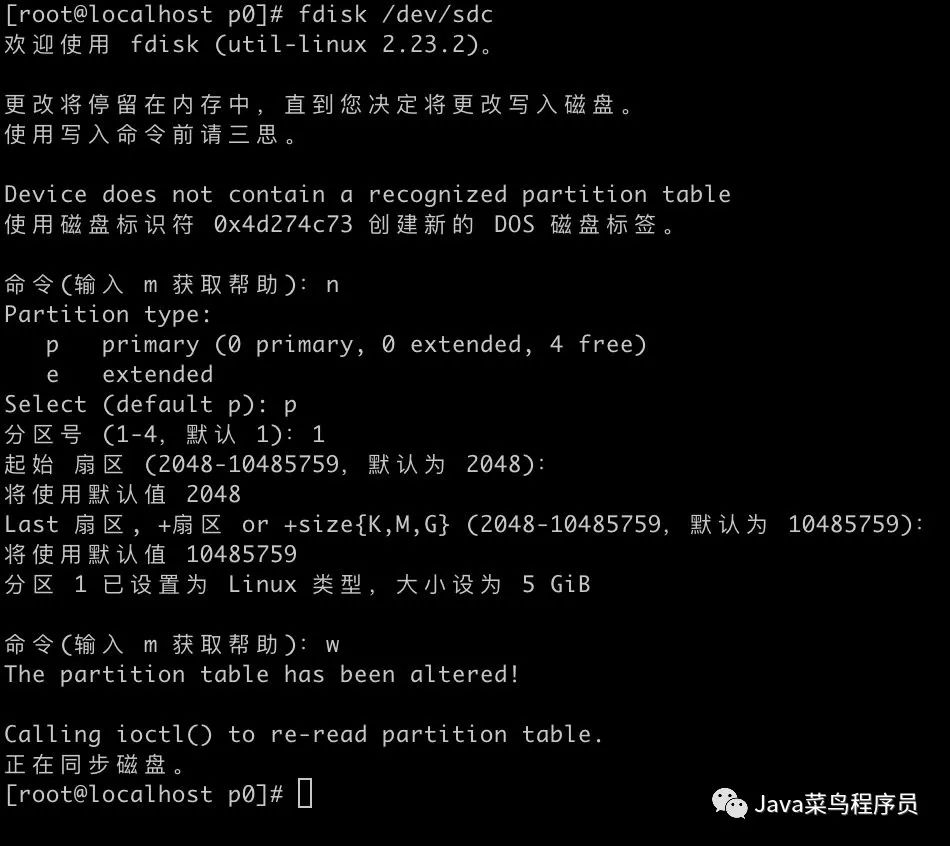
fdisk /dev/sdc
然后格式化分区
mkfs -t ext4 /dev/sdc1
接下来修改文件进行挂载。
vim /etc/fstab
最下面追加内容:
/dev/sdc1/ /mnt/p1 ext4 defaults 0 0
执行完成后进行重启
reboot
查看是否挂载成功。
cd /mnt/p1
mkdir data
这样第一个 PXC 节点的就完成了,另外一台 PXC 节点也是一样的步骤。就不再演示了。
完成后分配权限在两台节点上。
chown -R mysql:mysql /mnt/p0/data
chown -R mysql:mysql /mnt/p1/data
PXC 节点使用表分区
vim /etc/my.cnf
设置为宽容模式,还有一种模式就是严厉模式:DISABLED
pxc_strict_mode=PERMISSIVE
表分区类型
RANGE:根据连续区间值切分数据LIST:根据枚举值切分数据HASH:对整数求模切分数据KEY:对任何数据类型求模切分数据
Range 分区
Range 分区是按照主键值范围进行切分的,比如有 4 千万条数据。
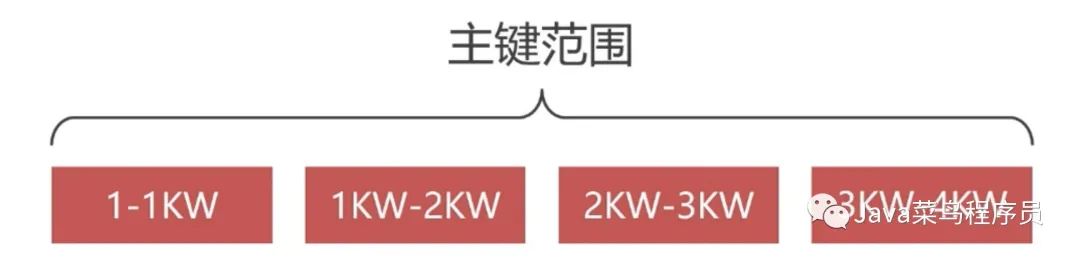
根据下面语句我们创建分区别,根据 ID 进行切分,p0 名字是可以随便起的,切分规则就是小于 1 千万条的数据切分到 p0 中,1 千万到 2 千万条在 p1 中,以此类推。
CREATE TABLE t_range_1(
id INT UNSIGNED PRIMARY KEY ,
name VARCHAR(200) NOT NULL
)
PARTITION BY RANGE(ID)(
PARTITION p0 VALUES LESS THAN (10000000),
PARTITION p1 VALUES LESS THAN (20000000),
PARTITION p2 VALUES LESS THAN (30000000),
PARTITION p3 VALUES LESS THAN (40000000)
);
最后我们在查询的时候可以根据分区进行查询,就会提高效率。
SELECT * FROM t_range_1 PARTITION(p0);
由于 MySQL 只支持整数类型切分,如果想使用日期类型的话,我们就要比如提取月份,进行分区。
需要注意的是:
分区字段必须是主键、联合主键的一部分,否则会报如下错误:
A PRIMARY KEY must include all columns in the table's partitioning function

CREATE TABLE t_range_2(
id INT UNSIGNED ,
name VARCHAR(200) NOT NULL,
birthday DATE NOT NULL,
PRIMARY KEY(id,birthday)
)
PARTITION BY RANGE(MONTH(birthday))(
PARTITION p0 VALUES LESS THAN (3),
PARTITION p1 VALUES LESS THAN (6),
PARTITION p2 VALUES LESS THAN (9),
PARTITION p3 VALUES LESS THAN (12)
);
如果我们想把表分区映射到不同的磁盘,需要使用下面的 SQL,p0 和 p1 就是刚才我们创建的分区。
CREATE TABLE t_range_2(
id INT UNSIGNED ,
name VARCHAR(200) NOT NULL,
birthday DATE NOT NULL,
PRIMARY KEY(id,birthday)
)
PARTITION BY RANGE(MONTH(birthday))(
PARTITION p0 VALUES LESS THAN (6) DATA DIRECTORY='/mnt/p0/data',
PARTITION p1 VALUES LESS THAN (12) DATA DIRECTORY='/mnt/p1/data'
);
我们在 PXC 某个节点上演示一下表分区。
use test;
CREATE TABLE t_range_2(
id INT UNSIGNED ,
name VARCHAR(200) NOT NULL,
birthday DATE NOT NULL,
PRIMARY KEY(id,birthday)
)
PARTITION BY RANGE(MONTH(birthday))(
PARTITION p0 VALUES LESS THAN (6) DATA DIRECTORY='/mnt/p0/data',
PARTITION p1 VALUES LESS THAN (12) DATA DIRECTORY='/mnt/p1/data'
);
创建完成后我们写入一些数据:

我们去 PXC 节点的服务器上查询一下,可以看到我们的数据已经切分过来了。
cd /mnt/p0/data/test
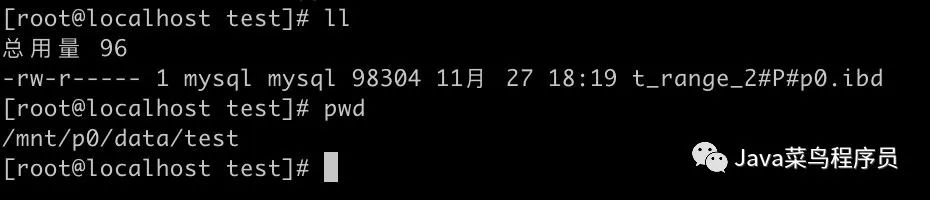
然后我们看一下 p1 的分区,也是没有问题的。

如果想查看每个分区保存了多少条数据的话,可以使用下面的 SQL:
select
PARTITION_NAME, #分区名称
PARTITION_METHOD,#分区方式
PARTITION_EXPRESSION,#分区字段
PARTITION_DESCRIPTION,#分区条件
TABLE_ROWS #数据量
from information_schema.PARTITIONS
where
TABLE_SCHEMA = SCHEMA() and TABLE_NAME = 't_range_2';

测试完成之后,我们将创建表的语句和分区在另一台 PXC 节点上创建一下。因为我们是使用 MyCat 来进行切分数据,但我们还没有规定 MyCat 切分规则,所以把我们刚才创建的两条测试数据删除掉。
完成后我们打开 MyCat 节点虚拟机。
vim /usr/local/mycat/conf/schema.xml
增加我们新建的表:
<table name="t_test" dataNode="dn1,dn2" rule="mod-long" />
进入 bin 目录重启 MyCat:
./mycat restart
然后我们连接 MyCat 节点,插入一些数据。
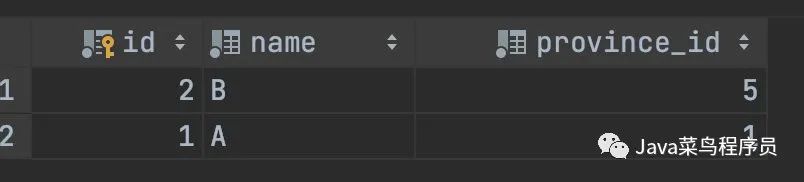
insert into t_range_2 (id,name,birthday) values (1,'A','2020-01-01');
insert into t_range_2 (id,name,birthday) values (2,'B','2020-10-10');
之后我们可以看到,数据被 MyCat 求模切分到了不同的 PXC 节点,随后又进行了日期的切分存储了不同的硬盘上,由此我们可以知道是可以共存的。
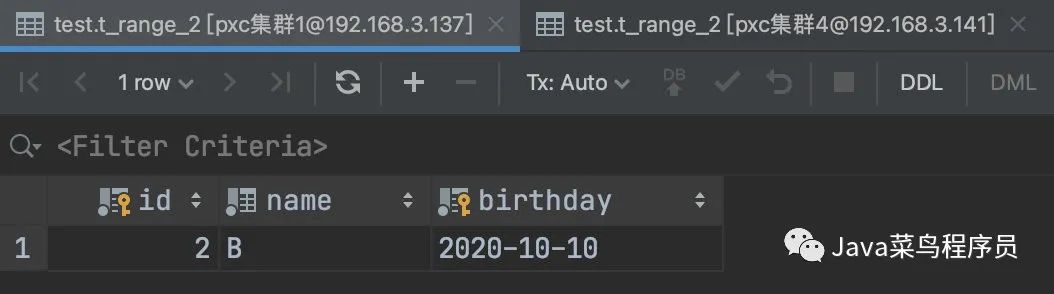
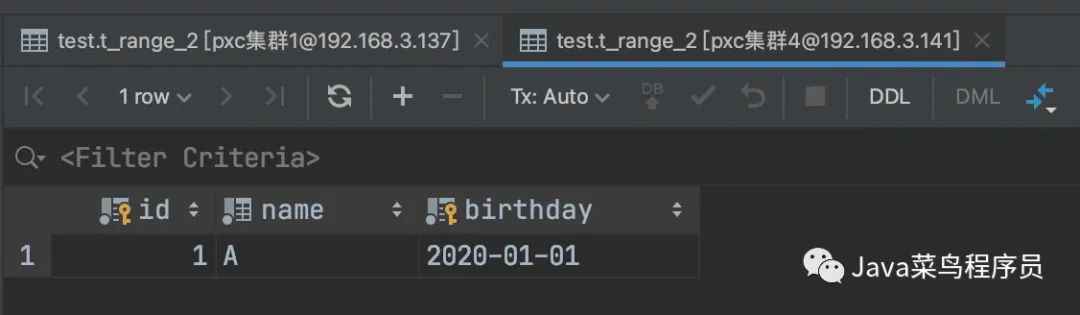
List 分区
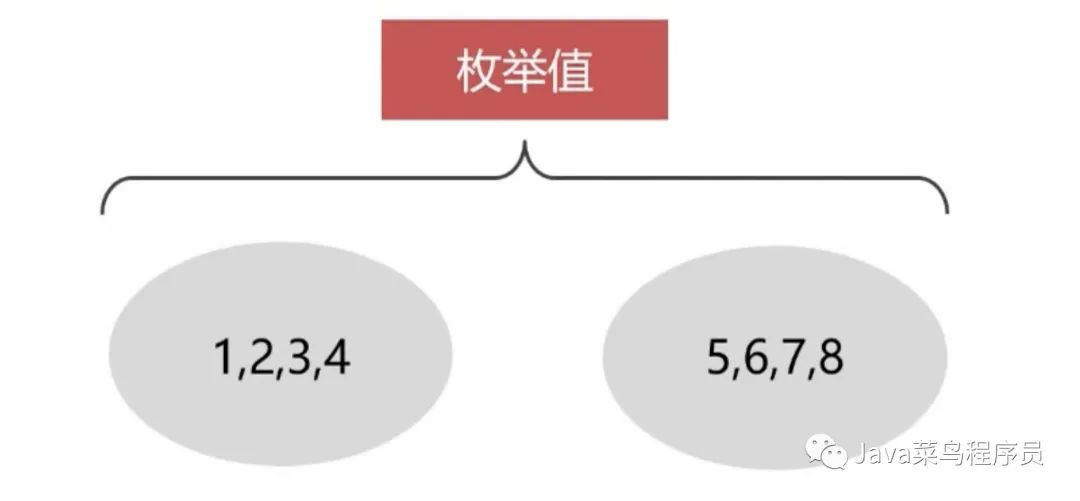
LIST 分区和 RANGE 分区非常的相似,主要区别在于 LIST 是枚举值列表的集合,RANGE 是连续的区间值的集合。二者在语法方面非常的相似。同样建议 LIST 分区列是非 null 列,否则插入 null 值如果枚举列表里面不存在 null 值会插入失败,这点和其它的分区不一样,RANGE 分区会将其作为最小分区值存储,HASH\KEY 分为会将其转换成 0 存储,主要 LIST 分区只支持整形,非整形字段需要通过函数转换成整形;5.5 版本之后可以不需要函数转换使用 LIST COLUMN 分区支持非整形字段。
我们在第一个 PXC 节点上创建表,大体的代码还是没有太大区别,只是规则从范围变成了固定的值。
create table t_list_1(
id int unsigned,
name varchar(200) not null,
province_id int unsigned,
primary key (id,province_id)
)
partition by list(province_id)(
partition p0 values in (1,2,3,4) data directory = '/mnt/p0/data',
partition p1 values in (5,6,7,8) data directory = '/mnt/p1/data'
);
然后在另一个 PXC 节点上创建,记得更改值。
create table t_list_1(
id int unsigned,
name varchar(200) not null,
province_id int unsigned,
primary key (id,province_id)
)
partition by list(province_id)(
partition p0 values in (9,10,11,12) data directory = '/mnt/p0/data',
partition p1 values in (13,14,15,16) data directory = '/mnt/p1/data'
);
随后我们进入 MyCat 的虚拟机,修改配置文件。
vim /usr/local/mycat/conf/rule.xml
增加如下代码:
<tableRule name="sharding-province">
<rule>
<columns>province_idcolumns>
<algorithm>province-hash-intalgorithm>
rule>
tableRule>
<function name="province-hash-int"class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">province-hash-int.txtproperty>
function>
保存退出后我们创建这个文件 province-hash-int.txt。这个文件创建在mycat/conf文件中
1=0
2=0
3=0
4=0
5=0
6=0
7=0
8=0
9=1
10=1
11=1
12=1
13=1
14=1
15=1
16=1
保存后我们编辑 schema.xml,增加我们新加的表:
<table name="t_list_1" dataNode="dn1,dn2" rule="sharding-province" />
随后重启 MyCat。
在 MyCat 节点上插入数据,我们看看是什么效果:
insert into t_list_1 (id,name,province_id) values (1,'A',1);
insert into t_list_1 (id,name,province_id) values (2,'B',5);
insert into t_list_1 (id,name,province_id) values (3,'A',10);
insert into t_list_1 (id,name,province_id) values (4,'B',16);
这里我就用图解的方式了:
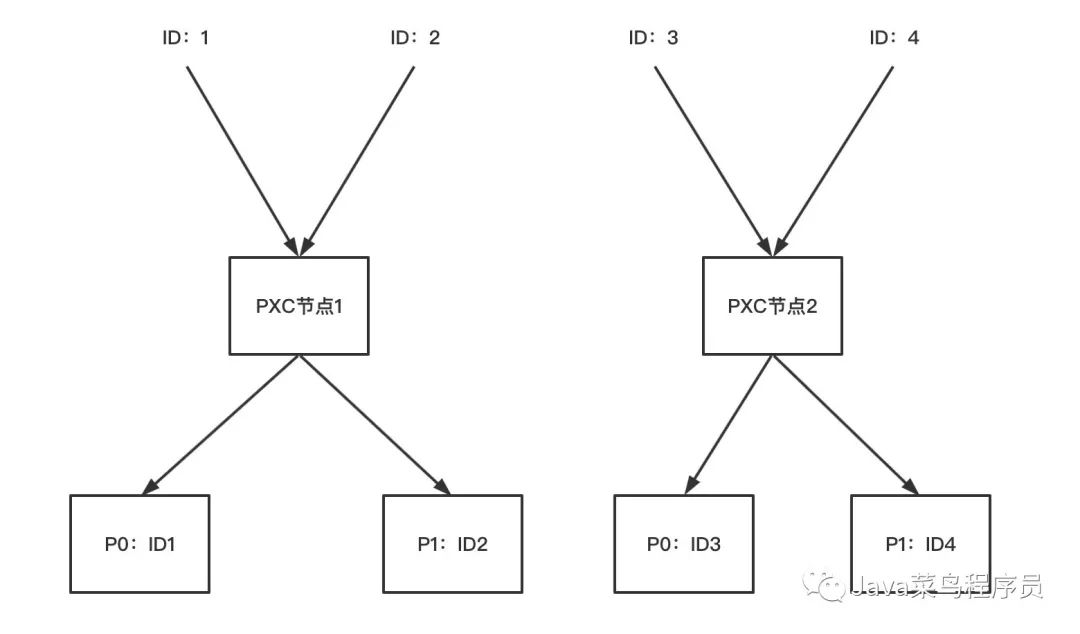
Hash 分区
基于给定的分区个数,将数据分配到不同的分区,HASH 分区只能针对整数进行 HASH,对于非整形的字段只能通过表达式将其转换成整数。表达式可以是 mysql 中任意有效的函数或者表达式,对于非整形的 HASH 往表插入数据的过程中会多一步表达式的计算操作,所以不建议使用复杂的表达式这样会影响性能。
语法如下,基本上没有太大区别,只是我们按照 2 取余数进行分区,如果等于 0 切分到 p0 如果等于 1 切分到 p1。
create table t_hash_1(
id int unsigned primary key ,
name varchar(200) not null,
province_id int unsigned not null
)
partition by hash(id) partitions 2(
partition p0 data directory = '/mnt/p0/data',
partition p1 data directory = '/mnt/p1/data'
);
然后我们还是进入 MyCat,编辑 schema.xml,增加我们新加的表,切分算法还是使用我们刚才创建的。
<table name="t_hash_1" dataNode="dn1,dn2" rule="sharding-province" />
随后重启 MyCat。
我们插入测试数据:
insert into t_hash_1 (id,name,province_id) values (1,'A',1);
insert into t_hash_1 (id,name,province_id) values (2,'B',5);
首先会根据 province_id 去进行 MyCat 切分,1-8 的 province_id 都会被存储在一个 PXC 节点上。
随后进行 Hash 分区,我们查询一下看看是否分配到了两个硬盘上。
select
PARTITION_NAME, #分区名称
PARTITION_METHOD,#分区方式
PARTITION_EXPRESSION,#分区字段
PARTITION_DESCRIPTION,#分区条件
TABLE_ROWS #数据量
from information_schema.PARTITIONS
where
TABLE_SCHEMA = SCHEMA() and TABLE_NAME = 't_hash_1';
执行结果也是没有问题,正确的分配到了不同的硬盘上。

Key 分区
KEY 分区和 HASH 分区相似,但是 KEY 分区支持除 text 和 BLOB 之外的所有数据类型的分区,而 HASH 分区只支持数字分区,KEY 分区不允许使用用户自定义的表达式进行分区,KEY 分区使用系统提供的 HASH 函数进行分区。当表中存在主键或者唯一键时,如果创建 KEY 分区时没有指定字段系统默认会首选主键列作为分区字列,如果不存在主键列会选择非空唯一键列作为分区列,注意唯一列作为分区列时唯一列不能为 NULL。
在两个 PXC 分片中执行 sql。
create table t_key_1(
id int unsigned not null ,
name varchar(200) not null,
job varchar(200) not null ,
primary key (id,job)
)
partition by key(job) partitions 2(
partition p0 data directory = '/mnt/p0/data',
partition p1 data directory = '/mnt/p1/data'
);
MyCat 配置schema.xml,增加配置:
<table name="t_key_1" dataNode="dn1,dn2" rule="mod-long" />
然后重启 MyCat。
之后我们测试数据:
insert into t_key_1 (id,name,job) values (1,'A','管理员');
insert into t_key_1 (id,name,job) values (2,'B','保洁');
insert into t_key_1 (id,name,job) values (3,'C','网管');
执行之后,我们 id 为 1、3 的求模切分到了一个 PXC 分片中。然后我们执行查询看看 Key 是怎么分区的。
select
PARTITION_NAME, #分区名称
PARTITION_METHOD,#分区方式
PARTITION_EXPRESSION,#分区字段
PARTITION_DESCRIPTION,#分区条件
TABLE_ROWS #数据量
from information_schema.PARTITIONS
where
TABLE_SCHEMA = SCHEMA() and TABLE_NAME = 't_key_1';
我们可以看到管理员和网管都被分到了一个硬盘中。

管理表分区
管理 Range 表分区
我们之前创建的 Range 表分区是到 4 千万,我们想扩展的话,可以使用下面的语句:
alter table t_range_1 add partition (
partition p4 values less than (50000000)
);
如果想删除表分区,可以使用下面的语句:
alter table t_range_1 drop partition p3,p4;
如果想拆分某一个区域的话可以使用下面的语句:
alter table t_range_1 reorganize partition p0 into (
partition s0 values less than (5000000),
partition s1 values less than (10000000)
)
对应的合并就是下面的语句:
alter table t_range_1 reorganize partition s0,s1 into (
partition p0 values less than (10000000)
)
移除表分区,并不会丢失数据,而是将数据放到主分区中。
alter table t_range_1 remove partitioning ;
对应的其他类型的分区语法都差不多,这里就不再演示了。















 264
264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









