





摘要:笔记记录爬取上期所持仓数据的过程,本次爬取使用的工具是python,使用的IDE是pycharm
进群:864573496 获取源码!
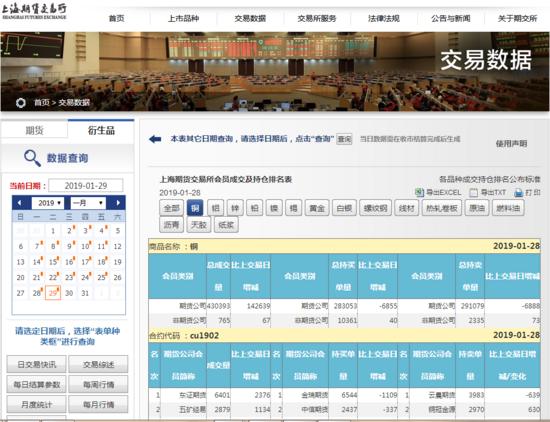
一、查看网页属性,分析数据结构
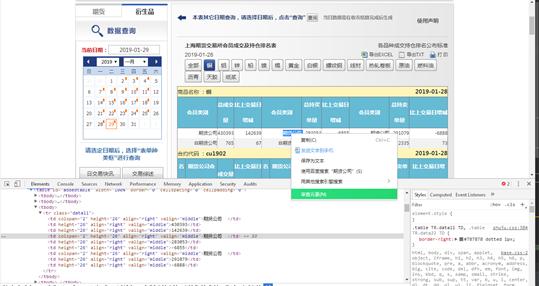
在浏览器中打开上期所网页,按F12或者选择表格文字-右键-审查元素,调出控制台:
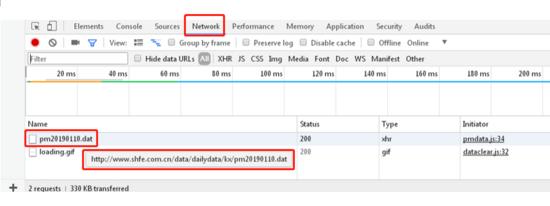
在Network中可以看到目标数据:http://www.shfe.com.cn/data/dailydata/kx/pm20190110.dat,其中 20190110 是数据代表的日期:
二、将数据下载到本地文件夹
1.在pycharm中新建一个python文档,将目标dat文件下载到本地文件夹,需要用到的包可以在CMD控制台中通过 ‘pip install [包名]’ 安装:
import xlwtimport requestsimport osmydate = "20190111" #指定需要的数据日期url = "http://www.shfe.com.cn/data/dailydata/kx/pm" + mydate + ".dat"root = "F://py//SQ//"path = root + url.split('/')[-1] + ".txt" #指定下载的目录,保存为txt文件r = requests.get(url)with open(path, 'wb') as f: f.write(r.content) f.close() print("文件保存成功")2.运行代码后,可以看到文件夹中多了个pm20190111.dat.txt文件,用记事本打开文件,可以看到文件是Json格式的表格,接下来用json包将其解析成python的dataframe格式:

代码:
import jsonfile = open("F://py//SQ//pm" + mydate + ".dat.txt

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









