






GBDT(Gradient Boosting Decision Tree)是被工业界广泛使用的机器学习算法之一,它既可以解决回归问题,又可以应用在分类场景中,该算法由斯坦福统计学教授 Jerome H. Friedman 在 1999 年发表。本文中,我们主要学习 GBDT 的回归部分。
在学习 GBDT 之前,你需要对 CART、AdaBoost 决策树有所了解,和 AdaBoost 类似,GBDT 也是一种 Boosting 类型的决策树,即在算法产生的众多树中,前一棵树的错误决定了后一棵树的生成。
我们先从最为简单的例子开始,一起来学习 GBDT 是如何构造的,然后结合理论知识,对算法的每个细节进行剖析,力求由浅入深的掌握该算法。
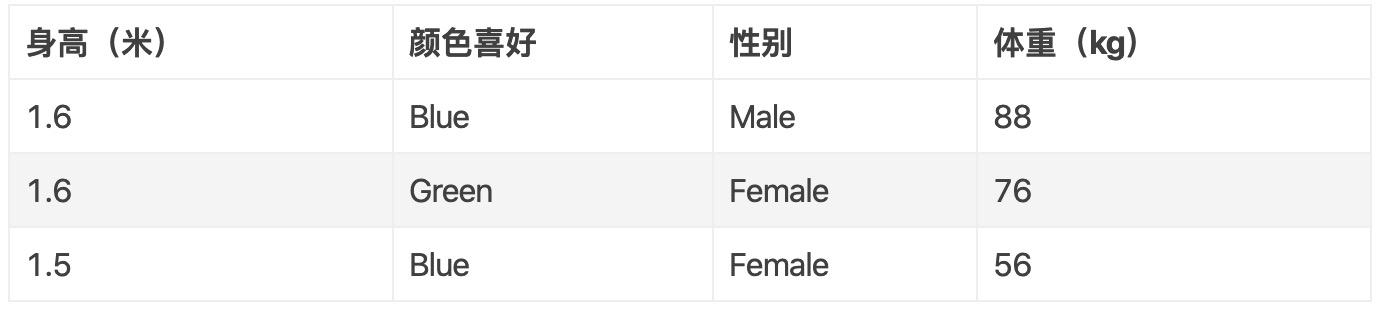
我们的极简数据集由以下 3 条数据构成,使用它们来介绍 GBDT 的原理是再好不过了,假设我们用这些数据来构造一个 GBDT 模型,该模型的功能是:通过身高、颜色喜好、性别这 3 个特征来预测体重,很明显这是一个回归问题。
构造 GBDT 决策树
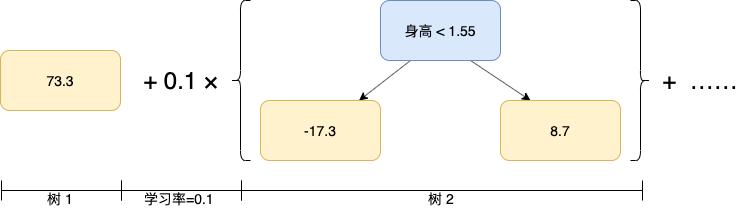
GBDT 的第一棵树只有 1 个叶子节点,该节点为所有样本的初始预测值,且该值到所有样本间的 MSE(Mean Squared Error)是最小的。实际上,初始值就是所有样本的平均值,即 (88+76+56)/3 = 73.3,原因我们在下文会详细介绍。
接下来,根据预测值,我们算出每个样本的残差(Residual),如第一个样本的残差为:88 - 73.3 = 14.7,所有样本的残差如下:
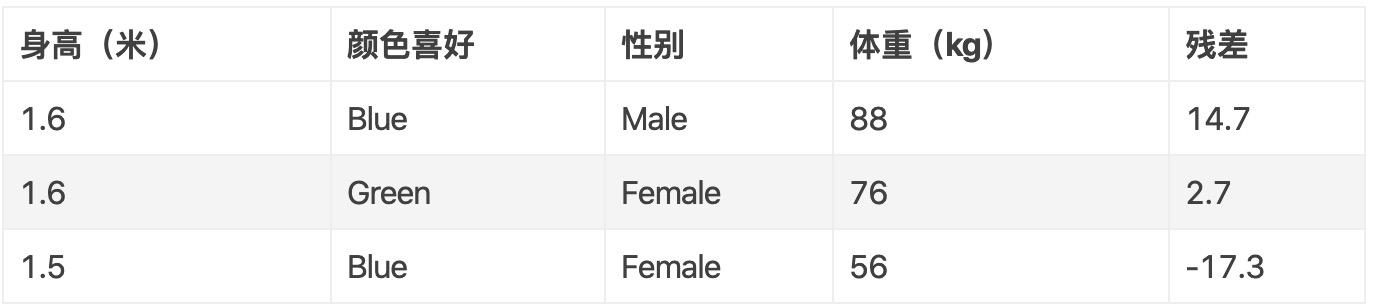
接着,我们以残差为目标值来构建一棵决策树,构造方式同 CART 决策树,这里你可能会问到为什么要预测残差?原因我们马上就会知道,产生的树如下:
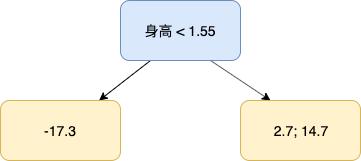
因为我们只有 3 个样本,且为了保留算法的细节,这里只用了 2 个叶子节点,但实际工作中,GBDT 的叶子节点通常在 8-32 个之间。
然后我们要处理有多个预测值的叶子节点,取它们的平均值作为该节点的输出,如下:
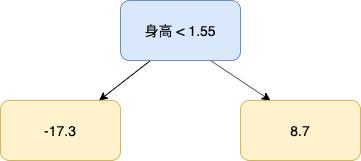
上面这棵树便是第 2 棵树,聪明的你一定发现了,第 2 棵树实际上是第 1 棵树和样本之间的误差,我们拿第 3 个样本作为例子,第一棵树对该样本的预测值为 73.3,此时它和目标值 56 之间的误差为 -17.3,把该样本输入到第 2 棵树,由于她的身高值为 1.5,小于 1.55,她将被预测为 -17.3。
既然后一棵树的输出是前一棵树的误差,那只要把所有的树都加起来,是不是就可以对前面树的错误做出补偿,从而达到逼近真实值的目的呢。这就是我们为什么以残差建树的原因。
当然树之间不会直接相加,而是在求和之前,乘上一个学习率,如 0.1,这样我们每次都可以在正确的方向上,把误差缩小一点点。Jerome Friedman 也说过这么做有助于提升模型的泛化能力(low variance)。
整个过程有点像梯度下降,这应该也是 GBDT 中 Gradient 的来历。GBDT 的预测过程如下图所示:
按此方法更新上述 3 个样本的预测值和残差,如下:

比较这两棵树的残差:
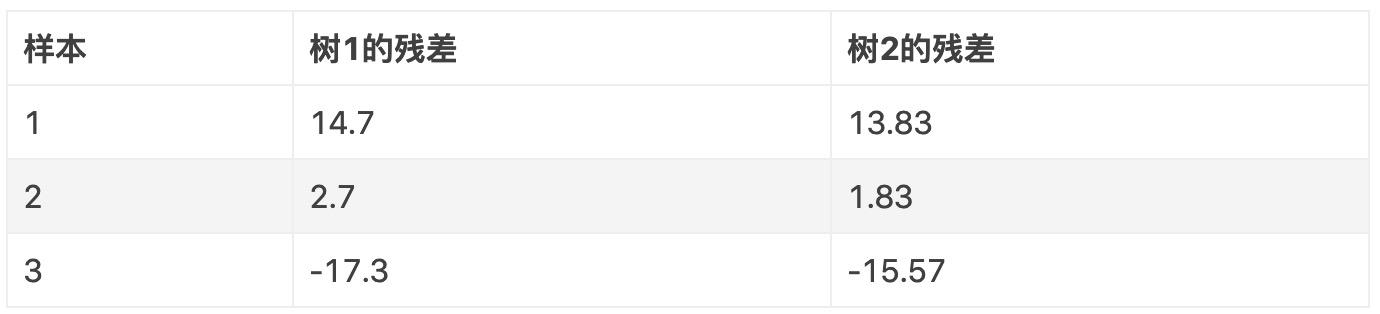
可见,通过 2 棵树预测的样本比只用 1 棵树更接近目标值。接下来,我们再使用第 2 棵树的残差来构建第 3 棵树,用第 3 棵树的残差来构建第 4 棵树,如此循环下去,直到树的棵数满足预设条件,或总残差小于一定阈值为止。以上,就是 GBDT 回归树的原理。
深入 GBDT 算法细节
GBDT 从名字上给人一种不明觉厉的印象,但从上文可以看出,它的思想还是非常直观的。对于只想了解其原理的同学,至此已经足够了,想学习更多细节的同学,可以继续往下阅读。
初始化模型
该算法主要分为两个步骤,第一步为初始化模型:
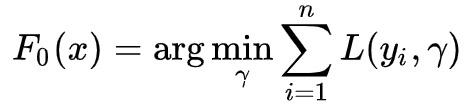
上式中,F表示模型,F_0 即模型初始状态;L 为 Loss Function,n 为训练样本的个数,y_i 为样本 i 的目标值,gamma 为初始化的预测值,意为找一个 gamma,能使所有样本的 Loss 最小。
前文提过,GBDT 回归算法使用 MSE 作为其 Loss,即:
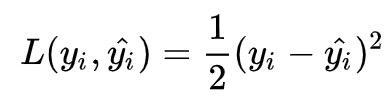
公式中 y^_i 表示第 i 个样本的预测值,我们把例子中的 3 个样本带入 F_0 中,得:
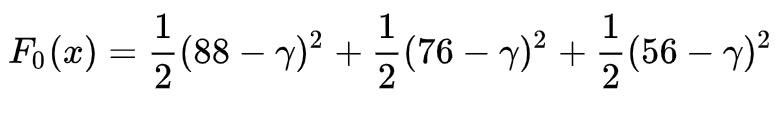
要找到一个 gamma,使上式最小,因为上式是一个抛物线,那么上式导数为 0 时,上式有最小值,于是:
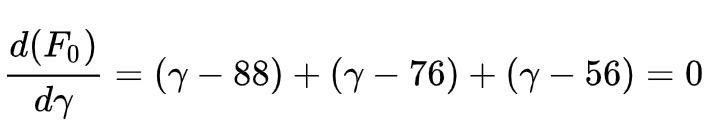
上式化简后,你一眼就可以看出 gamma = (88+76+56)/3 = 73.3,即初始值就是所有样本的平均值,
模型迭代
算法的第二个步骤是一个循环,伪代码如下:
for m = 1 to M: (A) (B) (C) (D)其中,m 表示树的序号,M 为树的总个数(通常该值设为 100 或更多),(A) (B) (C) (D) 代表每次循环中的 4 个子步骤,我们先来看 (A)
(A) 计算
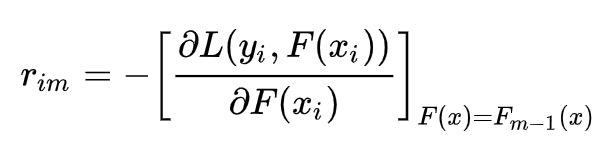
我们把 F(x_i) 换成 y^_i,该式子其实是对 Loss 求 y^_i 的偏微分,该偏微分为:
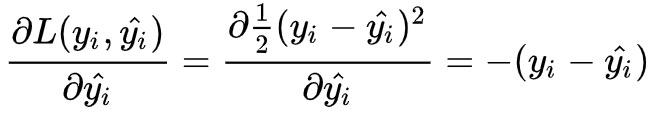
而 F(x)=F_{m-1}(x) 意为使用上一个模型来计算 y^_i,即用 m-1 棵已生成的树来预测每一个样本,那么 r_im=y_i-y^_i 就是上面说的计算残差这一步。
(B) 使用回归决策树来拟合残差 r_im,树的叶子节点标记为 R_jm,其中 j 表示第 j 个叶子节点,m 表示第 m 棵树。该步骤的细节如果不清楚可以查看《CART回归决策树》 一文。
(C) 对每个叶子节点,计算
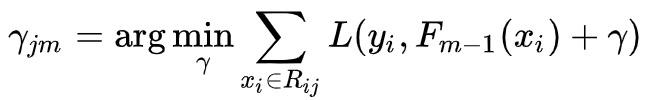
上面式子虽然较为复杂,但它和初始化步骤中的式子的目的是一样的,即在每个叶子节点中,找到一个输出值 gamma,使得整个叶子节点的 Loss 最小。
gamma_jm 为第 m 棵树中,第 j 个叶子节点的输出,sum L 表示在第 j 个叶子节点中所有样本的 Loss,如下面的树中,左边叶子节点上有 1 个样本,而右边叶子节点内有 2 个样本,我们希望根据这些样本来求得对应叶子的唯一输出,而 Loss 最小化就是解决之道。
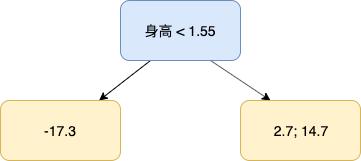
在 Loss 函数中,第 2 个参数 F_m-1(x_i) + gamma 是模型对样本 i 的预测,再加上 gamma,对于只有 1 个样本的叶子节点来说,gamma 就是该样本残差,而对于有多个样本的节点来说,gamma 为能使 Loss 最小的那个值,下面就这两种情况分别说明:
以上面这棵树为例,左边叶子节点只有 1 个样本,即样本 3,将它带入到公式中:
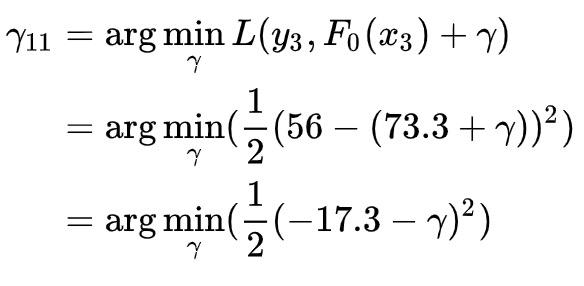
要求右边的式子最小,和上面一样,我们令其导数为 0:
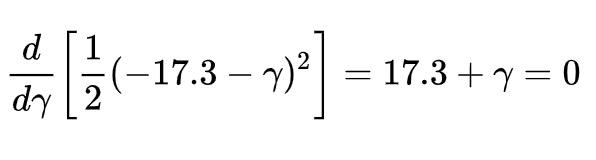
算得 gamma_11=-17.3,所以当叶子中只有 1 个样本时,该叶子的输出就是其残差。
再来看下右边这个节点,其中包含 2 个样本,同样把样本 1 和样本 2 带入到公式中,得:
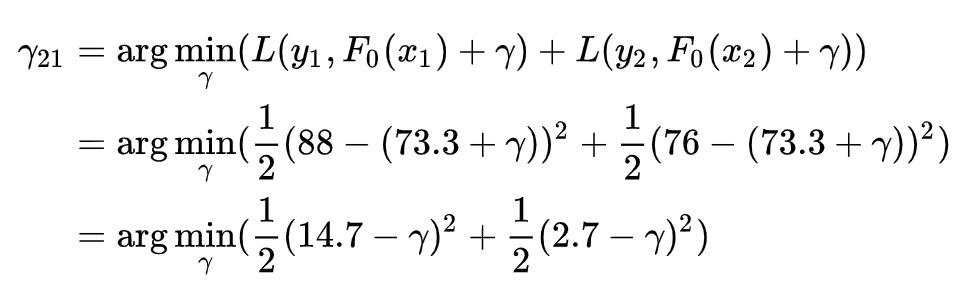
对右边求导:
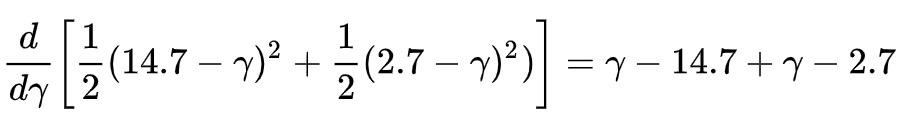
上式为 0 时,Loss 最小,即

于是
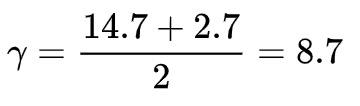
可见,当叶子中有多个样本时,该叶子的输出值就是所有样本残差的平均值。
(D) 更新模型,下次迭代中使用 m 棵树来做预测:
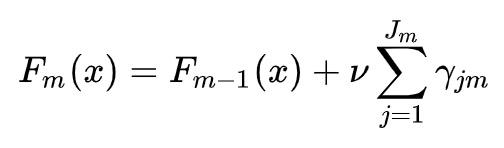
上式中,v 表示学习率。之后,训练将重新来到 (A) 步骤,进入下一棵树构建的循环中。
总结
本文我们一起学习了 GBDT 的回归算法,一开始,通过一个简单的例子描述了 GBDT 的原理,之后,我们对 GBDT 的每个步骤进行了逐一剖析,希望本文能给你带来收获。
参考:
- Greedy Function Approximation: A Gradient Boosting Machine (http://1t.click/byQA)
- Gradient Boost Part 1: Regression Main Ideas (http://1t.click/byQC)
- Gradient Boost Part 2: Regression Details (http://1t.click/byQC)
相关文章:
- 决策树算法之 AdaBoost
- 决策树算法之随机森林
- 决策树算法之 CART(Classification and Regression Trees)上
- 决策树算法之 CART(Classification and Regression Trees)下















 686
686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









