






机器之心发布
作者:Xiangteng He、Yuxin Peng、Liu Xie
北京大学彭宇新教授团队建立了第一个包含 4 种媒体类型(图像、文本、视频和音频)的细粒度跨媒体检索公开数据集和评测基准 PKU FG-XMedia,并且提出了一种能够同时学习 4 种媒体统一表征的深度网络模型 FGCrossNet。该论文已经被 CCF A 类国际会议 ACM MM 2019 大会接收。

- 本文链接:https://arxiv.org/abs/1907.04476
- 数据集链接:http://59.108.48.34/tiki/FGCrossNet
- 源码和模型链接:https://github.com/PKU-ICST-MIPL/FGCrossNet_ACMMM2019
- 课题组主页:http://www.wict.pku.edu.cn/mipl
- 课题组 Github 主页:https://github.com/PKU-ICST-MIPL
缺乏数据集和评测基准:现有跨媒体数据集一般是针对粗粒度跨媒体检索,而细粒度跨媒体检索还缺乏数据集和评测基准,因此相关研究比较少。
异构鸿沟:这是跨媒体检索面临的经典难题,是指不同媒体类型的数据有着不同的分布和特征表示,导致跨媒体检索十分困难,对细粒度跨媒体检索更是难上加难。
类间差异小,类内差异大:这是细粒度分类面临的挑战。其中,类间差异小是指不同的细粒度类别具有相似的外表(图像、视频)、描述(文本)和声音(音频);类内差异大是指由于视角、光照、描述、背景等不同,相同的细粒度类别又存在外表、描述和声音差异大的现象。上述问题导致难以准确检索特定细粒度类别的媒体数据,相比粗粒度跨媒体检索更具挑战。
建立了细粒度跨媒体检索的公开数据集和评测基准 PKU FG-XMedia;
提出了能够同时学习 4 种媒体统一表征的深度网络模型 FGCrossNet。
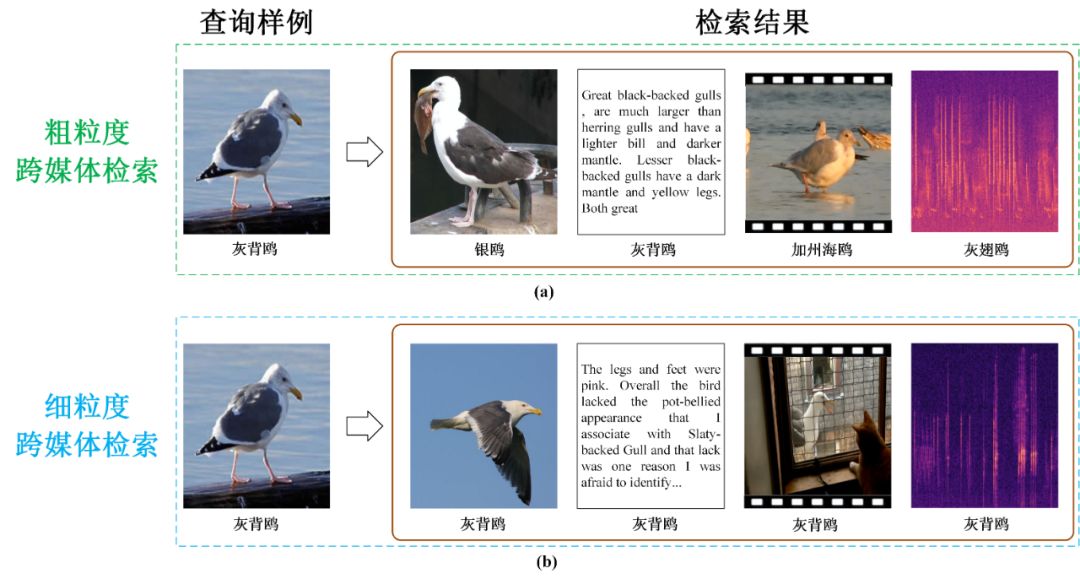
图 1:粗粒度跨媒体检索与细粒度跨媒体检索的区别

图 2:PKU FG-XMedia 数据集中的样例,如图展示了 7 种细粒度类别的图像、文本、视频和音频数据,其中音频数据用声谱图可视化。
PKU FG-XMedia 细粒度跨媒体数据集 PKU FG-XMedia 数据集包含超过 50,000 个样例,其中 11,788 个图像样例、8,000 个文本样例、18,350 个视频样例和 12,000 个音频样例。具有媒体类型多、类别细粒度和数据来源多的特点:媒体类型多:包含图像、文本、视频和音频 4 种媒体类型;
类别细粒度:包括鸟的 200 个细粒度类别,如灰背鸥、银鸥、加州海鸥和灰翅鸥等;
数据来源多:数据来源于不同的网站,导致数据质量不同,因此增加了检索的难度。
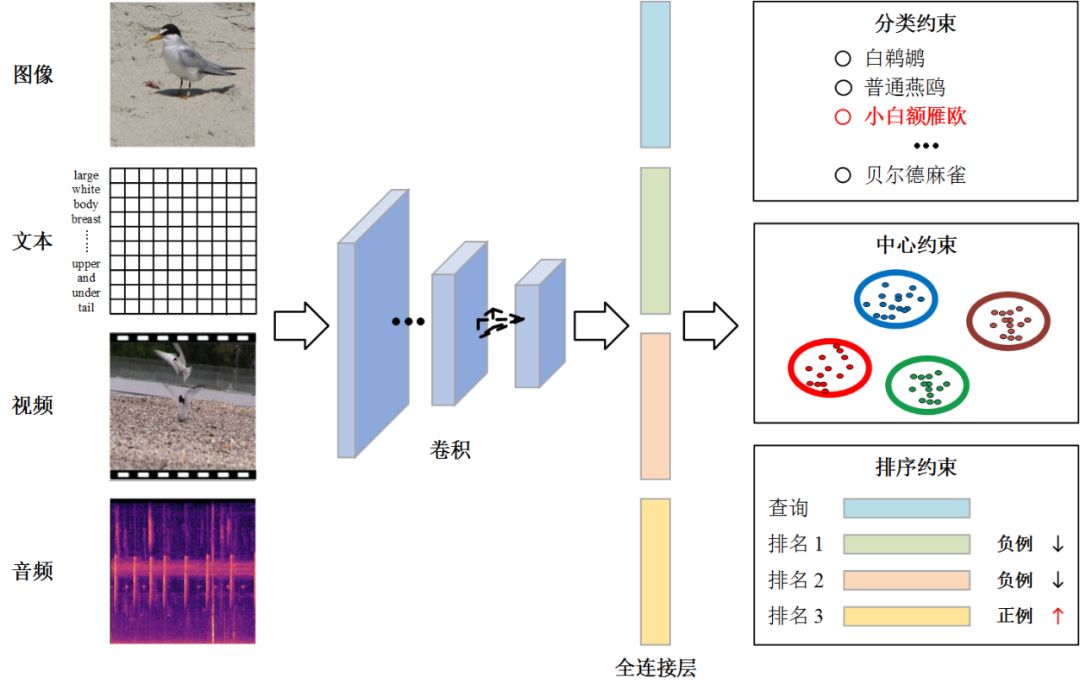
图 3:FGCrossNet 网络框架
本文在损失函数的设计上考虑了 3 种不同的约束:分类约束(Classification Constraint):确保细粒度类别统一表征的辨识性;
中心约束(Center Constraint):确保相同细粒度类别统一表征的紧凑性;
排序约束(Ranking Constraint):确保不同细粒度类别统一表征的松散性。
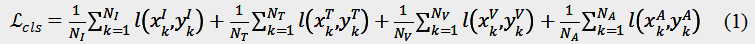
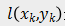 是交叉损失函数,I,T,V,A 分别表示图像、文本、视频和音频。
以图像为例,
是交叉损失函数,I,T,V,A 分别表示图像、文本、视频和音频。
以图像为例,
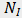 表示训练集中图像的数目,
表示训练集中图像的数目,
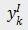 表示第 k 个图像样本的类别标签,
表示第 k 个图像样本的类别标签,
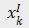 表示第 k 个图像样本的特征向量,在本文实验中为 FGCrossNet 网络模型最后一层全连接层的输出。
需要注意的是,本文采用视频帧进行网络模型的训练,因此
表示第 k 个图像样本的特征向量,在本文实验中为 FGCrossNet 网络模型最后一层全连接层的输出。
需要注意的是,本文采用视频帧进行网络模型的训练,因此
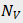 表示的是训练集中视频帧的数目。
中心约束(Center Constraint)
为了使得相同细粒度子类别的样本(包括图像、文本、视频和音频)在统一空间中具有相近的特征,本文通过中心约束来减少类内特征的距离以缩短模态之间的差异,其定义如下:
表示的是训练集中视频帧的数目。
中心约束(Center Constraint)
为了使得相同细粒度子类别的样本(包括图像、文本、视频和音频)在统一空间中具有相近的特征,本文通过中心约束来减少类内特征的距离以缩短模态之间的差异,其定义如下:
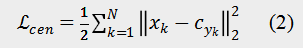
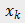 表示训练集中第 k 个样本的特征,在这里不区分媒体类型,因为目的是使得相同细粒度子类别的所有媒体数据的特征相近。
表示训练集中第 k 个样本的特征,在这里不区分媒体类型,因为目的是使得相同细粒度子类别的所有媒体数据的特征相近。
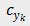 表
示
表
示
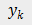 细粒度子类别的质心的特征,N 表示训练集中所有训练样本的数目。
排序约束(Ranking Constraint)
为了使得不同细粒度子类别的样本在统一空间中的距离尽可能大,本文定义了排序约束:
细粒度子类别的质心的特征,N 表示训练集中所有训练样本的数目。
排序约束(Ranking Constraint)
为了使得不同细粒度子类别的样本在统一空间中的距离尽可能大,本文定义了排序约束:
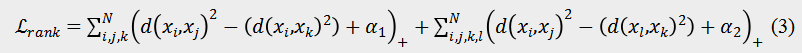
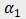 和
和
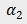 表示边界阈值用于平衡公式(3)
中的两项。
需要注意的是,在一次训练过程中,网络模型同时接收 4 种媒体的训练样本,且其中两个样本属于相同细粒度子类别,另外两个样本属于其他两个细粒度子类别。
通过上述三种约束,FGCrossNet 网络模型能够学习到具有辨识性、紧凑性和松散性的统一表征,以实现细粒度的跨媒体检索。
实验
本文在 PKU FG-XMedia 数据集上,通过两种细粒度跨媒体检索任务验证了 FGCrossNet 网络的有效性:
表示边界阈值用于平衡公式(3)
中的两项。
需要注意的是,在一次训练过程中,网络模型同时接收 4 种媒体的训练样本,且其中两个样本属于相同细粒度子类别,另外两个样本属于其他两个细粒度子类别。
通过上述三种约束,FGCrossNet 网络模型能够学习到具有辨识性、紧凑性和松散性的统一表征,以实现细粒度的跨媒体检索。
实验
本文在 PKU FG-XMedia 数据集上,通过两种细粒度跨媒体检索任务验证了 FGCrossNet 网络的有效性:
双模态细粒度跨媒体检索(Bi-modality Fine-grained Cross-media Retrieval):查询样例是任意一种媒体数据,检索结果是另外一种媒体数据,表示为 X→Y,其中 X,Y 分别为两种不同的媒体数据。例如,I→T 表示图像检索文本。
多模态细粒度跨媒体检索(Multi-modality Fine-grained Cross-media Retrieval:):查询样例是任意一种媒体数据,检索结果是 4 种媒体数据,表示为 X→All。例如,I→All 表示图像检索图像、文本、视频和音频 4 种媒体数据。

表 1:本文方法和现有方法在双模态细粒度跨媒体检索任务上的检索准确率(MAP)。
同样,本文也在多模态细粒度跨媒体检索任务上验证了 FGCrossNet 的有效性,结果如表 2 所示。在检索准确率(MAP)上,FGCrossNet 比当前 state-of-the-art 方法提升了 18%。值得注意的是,本文提出的 FGCrossNet 可以一次性学习 4 种媒体的统一表征。而在对比方法中,MHTN 可以同时学习 4 种媒体的统一表征,但是其网络结构相对复杂,需要对每一种媒体都设计不同的分支网络;其他对比方法一次则只能学习两种媒体的统一表征,因此这些方法的训练和检索复杂度都比较高。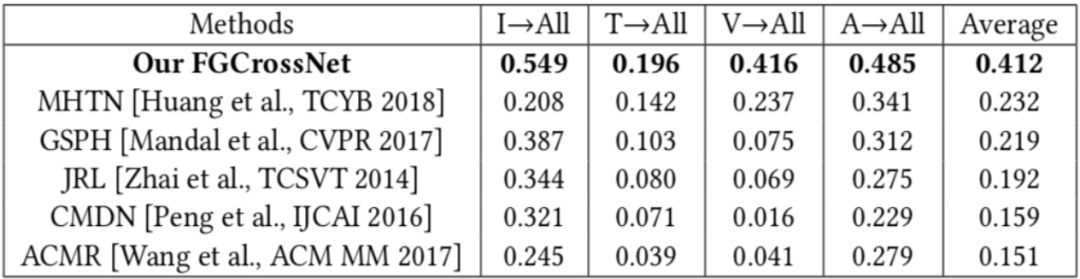

www.jiqizhixin.com/sota
PC 访问,体验更佳














 894
894











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









