







点击上方蓝色字体,选择“设为星标”
回复”资源“获取更多资源




Hbase、Kudu和ClickHouse横向对比V2.0
前言
Hadoop生态圈的技术繁多。HDFS一直用来保存底层数据,地位牢固。Hbase作为一款Nosql也是Hadoop生态圈的核心组件,它海量的存储能力,优秀的随机读写能力,能够处理一些HDFS不足的地方。Clickhouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。能够使用SQL查询实时生成分析数据报告。它同样拥有优秀的数据存储能力。
Apache Kudu是Cloudera Manager公司16年发布的新型分布式存储系统,结合CDH和Impala使用可以同时解决随机读写和sql化数据分析的问题。分别弥补HDFS静态存储和Hbase Nosql的不足。
既然可选的技术路线有这么多,本文将从安装部署、架构组成、基本操作等方面横向对比一下Hbase、Kudu和Clickhouse。另外这里还引入了几个大厂的实践作为例子予以参考。
安装部署方式对比
具体的安装步骤不过多赘述,这里只简要比较安装过程中需要依赖的外部组件。
Habse安装
依赖HDFS作为底层存储插件 依赖Zookeeper作为元数据存储插件
Kudu安装
依赖Impala作为辅助分析插件 依赖CDH集群作为管理插件,但是不是必选的,也可以单独安装
Clickhouse安装
依赖Zookeeper作为元数据存储插件和Log Service以及表的 catalog service
组成架构对比
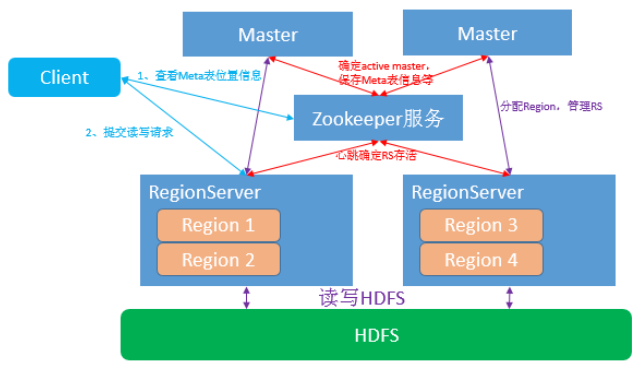
Hbase架构
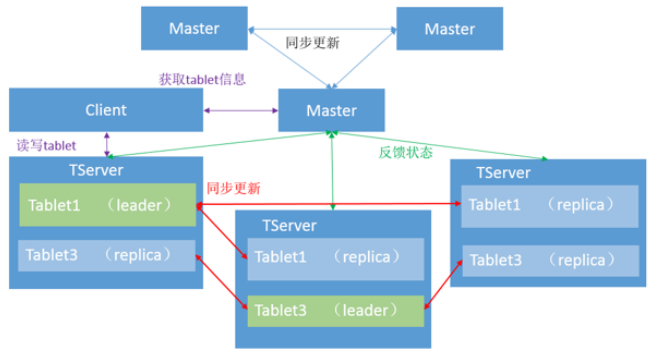
Kudu架构
Clickhouse架构
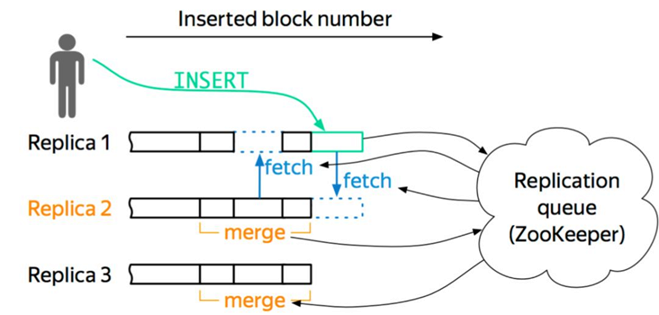
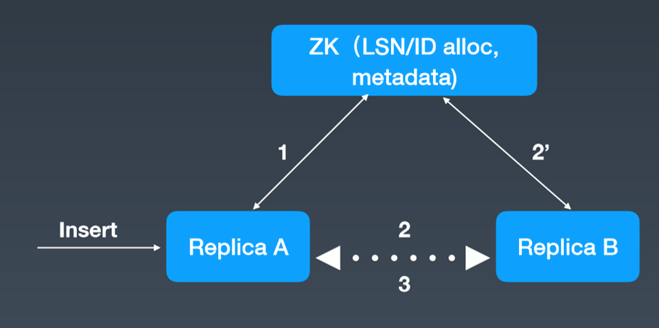
综上所示,Hbase和Kudu都是类似于Master-slave的架构而Clickhouse不存在Master结构,Clickhouse的每台Server的地位都是等价的,是multi-master模式。不过Hbase和Clickhouse额外增加了一个Zookeeper作为辅助的元数据存储或者是log server等,而Kudu的元数据是Master管理的,为了避免server频繁从Master读取元数据,server会从Master获取一份元数据到本地,但是会有元数据丢失的风险。
基本操作对比
数据读写操作
•Hbase读流程
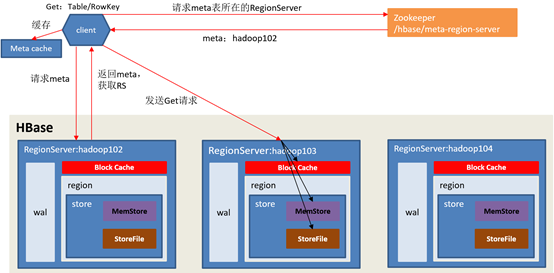
•Hbase写流程
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 496
496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









