





前一段时间做实验,发现自己写的有些代码效率比较低,GPU利用率不高。而且现在逐渐觉得用Pytorch等框架有时不够自由,导致某些idea难以实现。所以最近在学习CUDA编程,这一系列文章会整理一下所学的东西,希望能和大家共同学习共同进步。如有文中错误的地方,希望大家不吝指出,谢谢!
我个人主要是通过以下三本书进行学习的,建议初学者从《CUDA C编程权威指南》入手进行学习。
- CUDA并行程序设计——GPU编程指南
- CUDA C编程权威指南
- 多核与GPU编程——工具、方法及实现
CUDA编程模型
本文作为系列的第一篇,主要是从软件层面介绍一些CUDA编程的基本概念。
CUDA是一种通用的并行计算平台和编程模型,是在C语言基础上扩展的。
CUDA编程模型假设系统是由一个主机(CPU)和一个设备(GPU)组成的,而且各自拥有独立的内存。而我们作为程序员,需要做的就是编写运行在主机和设备上的代码,并且根据代码的需要为主机和设备分配内存空间以及拷贝数据。而其中,运行在设备上的代码,我们一般称之为核函数(Kernel),核函数将会由大量硬件线程并行执行。
一个典型的CUDA程序是按这样的步骤执行的:
- 把数据从CPU内存拷贝到GPU内存。
- 调用核函数对存储在GPU内存中的数据进行操作的。
- 将数据从GPU内存传送回CPU内存。
CUDA编程模型有两个特色功能,一是通过一种层次结构来组织线程,二是通过层次结构来组织内存的访问。这两点和我们平时CPU编程是有较大区别的。
先说第一点,一般CPU一个核只支持一到两个硬件线程,而GPU往往在硬件层面上就支持同时成百上千个并发线程。不过这也要求我们在GPU编程中更加高效地管理这些线程,以达到更高的运行效率。在CUDA编程中,线程是通过线程网格(Grid)、线程块(Block)、线程束(Warp)、线程(Thread)这几个层次进行管理的,后面我们会详细讲到。
再说第二点,为了达到更高的效率,在CUDA编程中我们需要格外关注内存的使用。与CPU编程不同,GPU中的各级缓存以及各种内存是可以软件控制的,在编程时我们可以手动指定变量存储的位置。具体而言,这些内存包括寄存器、共享内存、常量内存、全局内存等。这就造成了CUDA编程中有很多内存使用的小技巧,比如我们要尽量使用寄存器,尽量将数据声明为局部变量。而当存在着数据的重复利用时,可以把数据存放在共享内存里。而对于全局内存,我们需要注意用一种合理的方式来进行数据的合并访问,以尽量减少设备对内存子系统再次发出访问操作的次数。
下面我们详细说说线程管理和内存管理这两点。
线程管理
首先我们需要了解线程是如何组织的,下面这幅图比较清晰地表示出了线程的组织结构。当核函数在主机端启动时,其执行会移动到设备上,此时设备中会产生大量的线程并且每个线程都执行由核函数指定的语句。
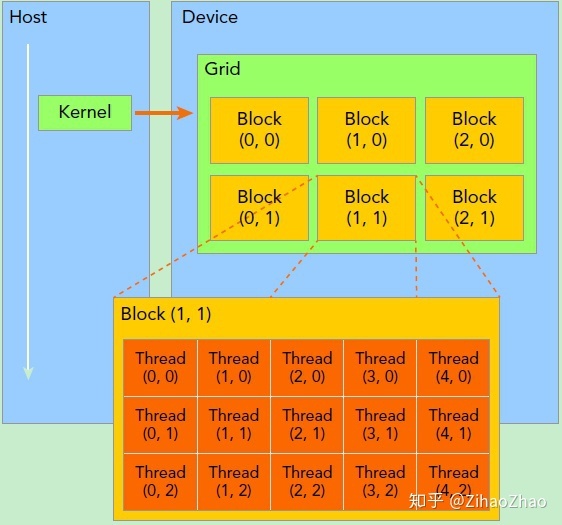
由一个内核启动所产生的所有线程统称一个网格(Grid),同一网格中的所有线程共享相同的全局内存空间。向下一级,一个网格由多个线程块(Block)构成。再下一级,一个线程块由一组线程(Thread)构成。线程网格和线程块从逻辑上代表了一个核函数的线程层次结构,这种组织方式可以帮助我们有效地利用资源,优化性能。CUDA编程中,我们可以组织三维的线程网格和线程块,具体如何组织,一般是和我们需要处理的数据有关。上面这个示意图展示的是一个包含二维线程块的二维线程网格。
如果使用了合适的线程网格和线程块大小来正确地组织线程,内核的性能可以得到大大地提高。通常给定一个需求,我们会有多种选择来实现核函数,并且我们会有多种不同的配置来执行该核函数。而学习如何组织线程就是其中的重点之一,后面我们通过编程例子来学习具体如何合理组织。
内存管理
CUDA编程另一个显著的特点就是解释了内存层次结构,每一个GPU设备都会有用于不同用途的存储类型。
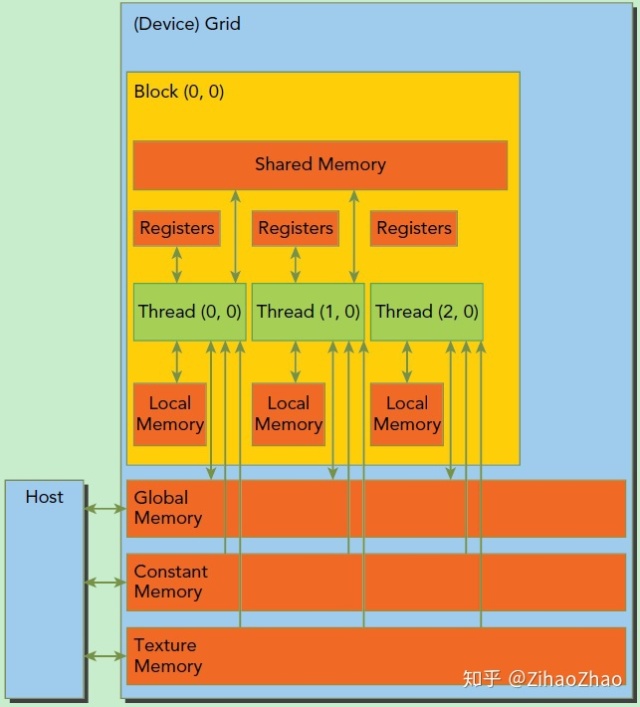
上图描绘了各种内存空间的层次结构,看不太懂没有关系,我们只需先关注这三种内存类型:寄存器(Registers)、共享内存(Shared Memory)和全局内存(Global Memory)。
其中寄存器是GPU上运行速度最快的内存空间,通常其带宽为8TB/s左右,延迟为1个时钟周期。核函数中声明的一个没有其他修饰符的自变量,通常就存储在寄存器中。最快速也最受偏爱的存储器就是设备中的寄存器,属于具有重要价值有极度缺乏的资源。
接下来是共享内存,共享内存是GPU上可受用户控制的一级缓存。共享内存类似于CPU的缓存,不过与CPU的缓存不同,GPU的共享内存可以有CUDA内核直接编程控制。由于共享内存是片上内存,所以与全局内存相比,它具有更高的带宽与更低的延迟,通常其带宽为1.5TB/s左右,延迟为1~32个时钟周期。对于共享内存的使用,主要考虑数据的重用性。当存在着数据的重复利用时,使用共享内存是比较合适的。如果数据不被重用,则直接将数据从全局内存或常量内存读入寄存器即可。
全局内存是GPU中最大、延迟最高并且最常使用的内存。全局内存类似于CPU的系统内存。在编程中对全局内存访问的优化以最大化程度提高全局内存的数据吞吐量是十分重要的。
CUDA给编程者提供了这些可以操作的GPU内存层次结构,这对我们进行数据移动和布局提供了更多可控制的支持,方便了我们以更接近底层硬件实现的思路优化程序,以达到更高的性能。这也是CUDA编程不同于CPU编程的特点之一。
小结
线程管理和内存管理,是我个人认为CUDA编程中最基础且重要的两个部分,提前了解有助于更深入地理解CUDA编程的本质。这一篇我们了解了一些软件层面的基本知识,下一篇我们会继续深入,再从硬件角度看看CUDA编程。















 3120
3120











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









