






CUDA架构是围绕一个流式多处理器SM的可扩展阵列搭建的。
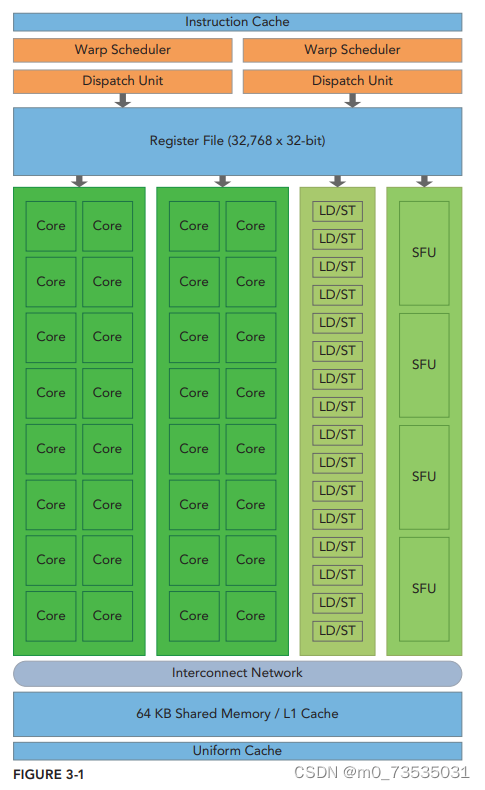
Fermi SM的关键组件:
- CUDA核心
- 共享内存/一级缓存
- 寄存器文件
- 加载/存储单元
- 特殊功能单元
- 线程束调度器。
每个GPU通常有多个SM,每个SM都能支持数百个线程并发执行,所以在一个GPU上并发执行数千个进程是有可能的。
启动内核 -> 线程块分布在可用SM上 -> 线程块一旦被调度到一个SM上,其中的线程只会在那个指定的M上并发执行
CUDA采用单指令多线程(SIMT)架构来管理和执行线程,每32个线程为一组,被称为线程束。线程束中所有线程同时执行相同的指令。
SIMT包含3个SIMD(单指令多数据)所不具备的关键特征:
- 每个线程都有自己的指令地址计数器
- 每个线程都有自己的寄存器状态
- 每个线程可以有一个独立的执行路径
一个线程块只能在一个SM上被调度。一旦线程块在一个SM上被调度,就会保存在该 SM上直到执行完成。在同一时间,一个SM可以容纳多个线程块。

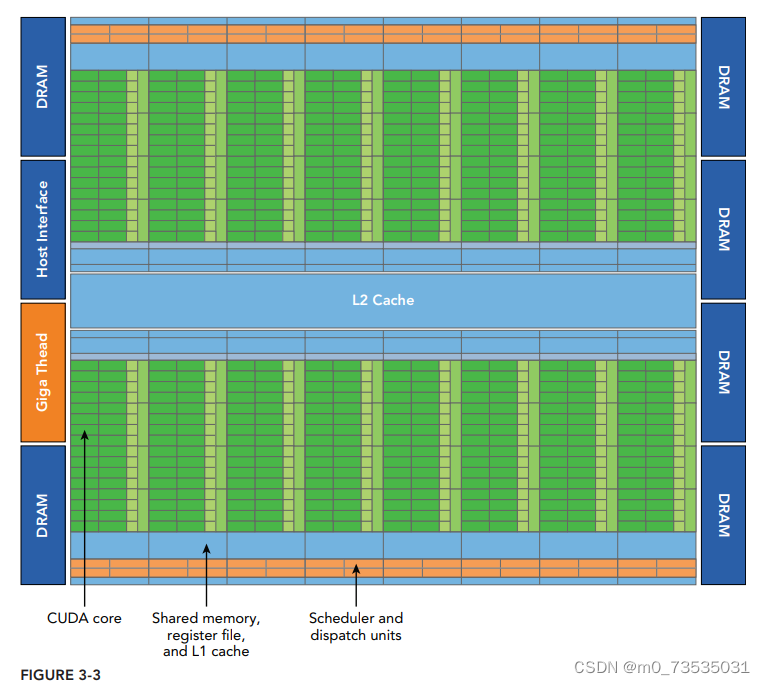
Fermi架构
512个加速器核心(CUDA核心)。每个CUDA 核心都有一个全流水线的整数算术逻辑单元(ALU)和一个浮点运算单元(FPU),每个时钟周期执行一个整数或是浮点数指令。
CUDA核心被组织到16个SM中,每个SM含有32个CUDA核心。
Fermi架构有6个384位的GDDR5 DRAM存储器接口,支持多达 6GB的全局机载内存。
主机接口通过PCIe总线将GPU与CPU相连。
GigaThread引擎(图示左侧第三部分)是一个全局调度器,用来分配线程块到SM线程束调度器上。
Fermi架构包含一个耦合的768 KB的二级缓存,被16个SM所共享。
一个垂直矩形条表示一个SM,包含了以下内容:
- 执行单元(CUDA核心)
- 调度线程束的调度器和调度单元
- 共享内存、寄存器文件和一级缓存
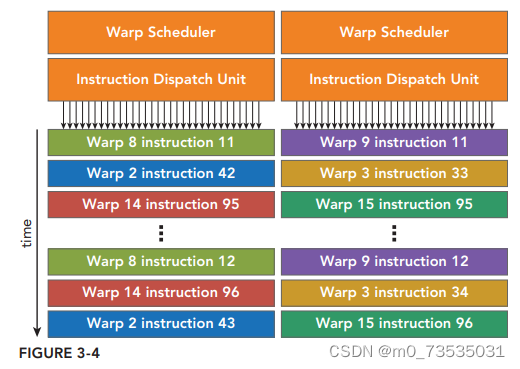
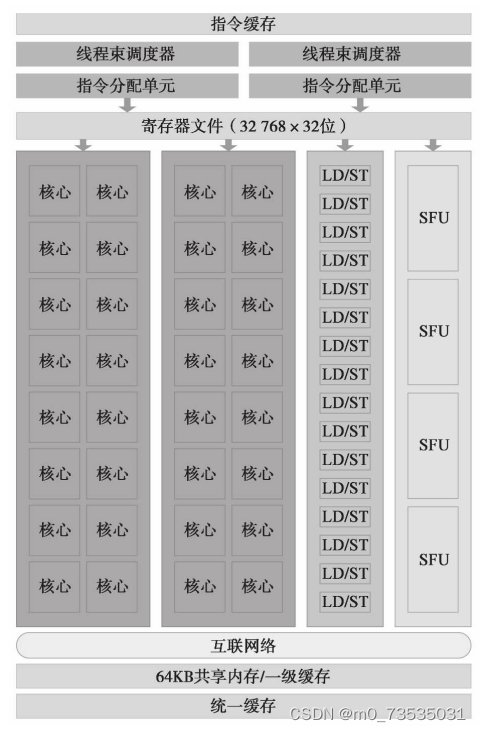
当一个线程块被指定给一个SM时,线程块中的所有线程被分成了线程束。两个线程束调度器选择两个线程束,再把一个指令从线程束中发送到一个组上,一个组里有16个CUDA核心、16个加载/存储单元或4个特殊功能单元(SFU)。
Fermi架构的一个关键特征是有一个64KB的片内可配置存储器,它在共享内存与一级缓存之间进行分配。 共享内存允许一个块上的线程相互合作,这有利于芯片内数据的广泛重用,并大大降低了片外的通信量。
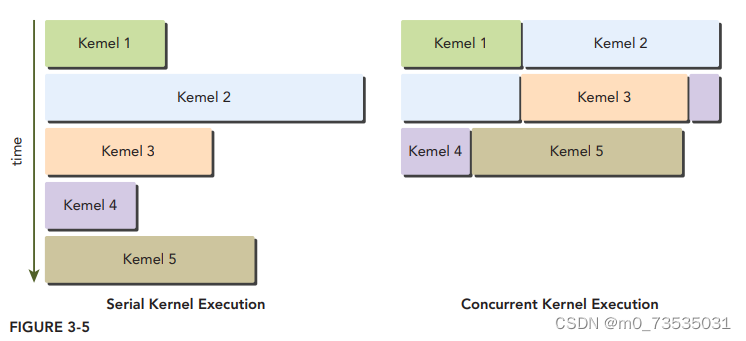
Fermi架构也支持并发内核执行:在相同的GPU上执行相同应用程序的上下文中,同时启动多个内核。并发内核执行允许执行一些小的内核程序来充分利用GPU。Fermi架构允许多达16个内核同时在设备上运行。从程序员的角度看,并发内核执行使GPU表现得更像MIMD架构。
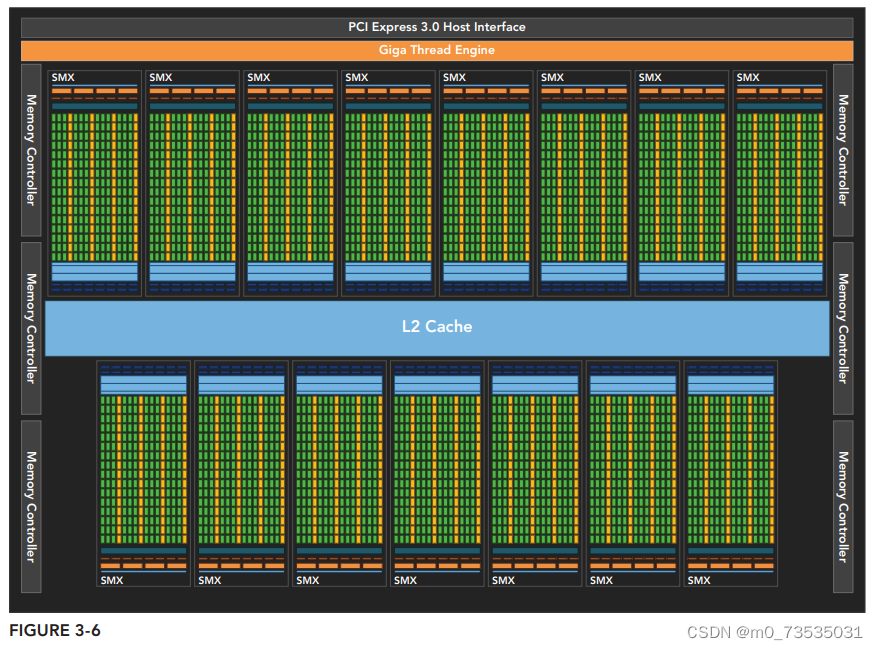
Kepler架构
15个SM和6个64位的内存控制器。每个SM包含192个单精度CUDA核心,64个双精度单元,32个特殊功能单元(SFU)以及32个加载/存储单元(LD/LT)。每个SM包含4个线程束调度器和8个指令调度器,以确保在单一的SM上同时发送和执行4个线程束。
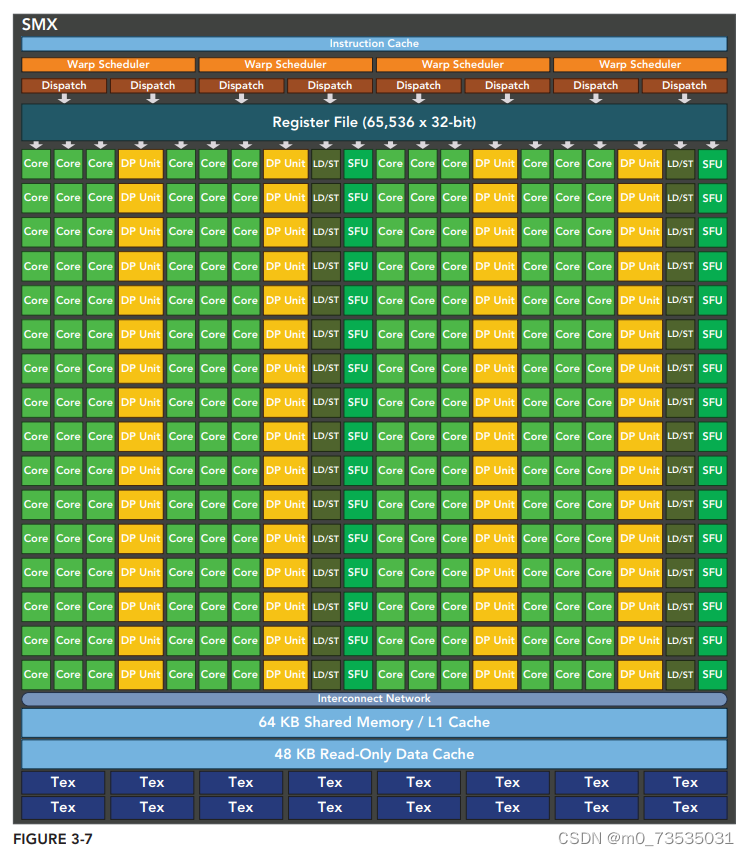
3个重要创新:
- 强化的SM
- 动态并行
- Hyper-Q技术
动态并行是Kepler GPU的一个新特性,它允许GPU动态启动新的网格。有了这个特点,任一内核都能启动其他的内核,并且管理任何核间需要的依赖关系来正确地执行附加的工作。这一特点也让你更容易创建和优化递归及与数据相关的执行模式。有了动态并行,GPU能够启动嵌套内核,消除了与CPU通信的需求。
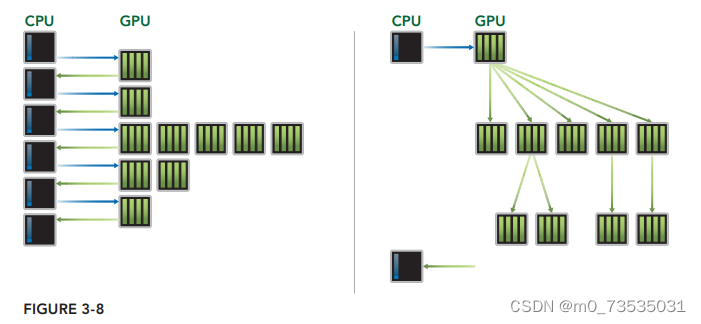
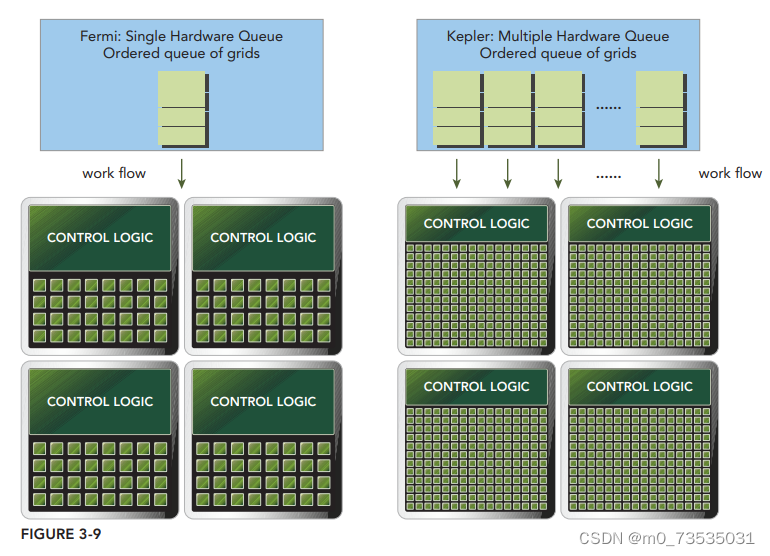
Hyper-Q技术:增加了更多的CPU和GPU之间的同步硬件连接,以确保CPU核心能够在GPU上同时运行更多的任务。Fermi GPU依赖一个单一的硬件工作队列来从CPU到GPU间传送任务,这可能会导致一个单独的任务阻塞队列中在该任务之后的所有其他任务。Kepler Hyper-Q消除了这个限制。
性能分析工具:nvvp(独立的可视化分析器) / nvprof(命令行分析器)
3种常见的限制内核性能的因素:
- 存储带宽
- 计算资源
- 指令和内存延迟
线程束是SM中基本执行单元。当一个线程块的网格被启动后,网格中的线程块分布在SM中。一旦线程块被调度到一个SM上,线程块中的线程会被进一步划分为线程束。一个线程束由32个连续的线程组成,在一个线程束中,所有的线程按照单指令多线程(SIMT)方式执行;也就是说,所有线程都执行相同的指令,每个线程在私有数据上进行操作。
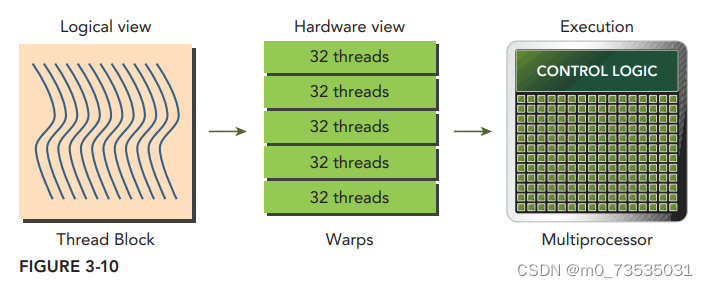
一个线程块中线程束的数量=向正无穷取整(一个线程块中线程的数量/线程束大小)
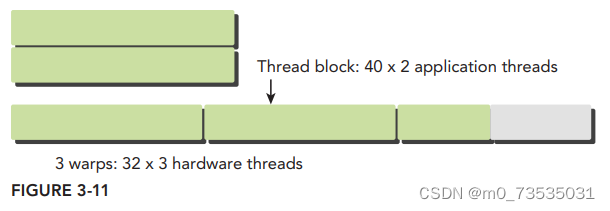
个在x轴中有40个线程、在y轴中有2个线程的二维线程块。从应用程序的角度来看,在一个二维网格中共有80个线程。硬件为这个线程块配置了3个线程束,使总共96个硬件线程去支持80个软件线程。注意,最后半个线程束是不活跃的。即使这些线程未被使用,它们仍然消耗SM的资源,如寄存器。
线程束分化
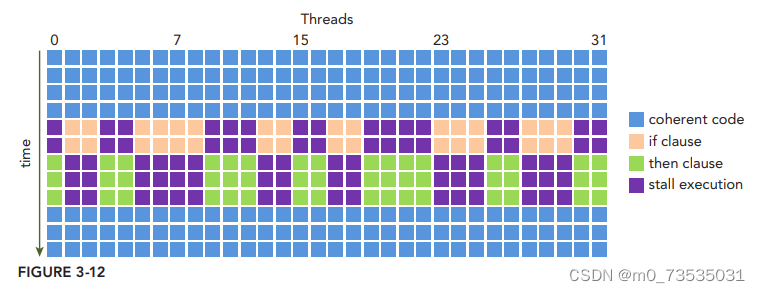
GPU是相对简单的设备,没有分支预测机制。一个线程束中的所有线程在同一周期必须执行相同的指令。
假设在一个线程束中16个线程执行这段代码,cond为true,但对于其他16个来说cond为false。一半的线程束需要执行if语句块中的指令,而另一半需要执行else语句块中的指令。在同一线程束中的线程执行不同的指令,被称为线程束分化。
if(cond){
...
}else{
...
}如果一个线程束中的线程产生分化,线程束将连续执行每一个分支路径,而禁用不执行这一路径的线程。线程束分化会导致性能明显地下降。在上面的例子中可以看到,线程束中并行线程的数量减少了一半:只有16个线程同时活跃地执行,而其他16个被禁用了。
Note:线程束分化只发生在同一个线程束中。在不同的线程束中,不同的条件值不会 引起线程束分化。
例:下面这个kernel可以产生一个比较低效的分支
__global__ void mathKerne1(float* c) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float a, b;
a = b = 0.0f;
if (tid % 2 == 0) {
a = 100.0f;
}
else {
b = 200.0f;
}
c[tid] = a + b;
}如果使用线程束方法(而不是线程方法)来交叉存取数据,可以避免线程束分化,并 且设备的利用率可达到100%。假设只配置一个x=64的一维线程块,那么只有两个线程束。
__global__ void mathKerne2(void) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float a, b;
a = b = 0.0f;
if ((tid/warpSize) % 2 == 0) {
a = 100.0f;
}
else {
b = 200.0f;
}
c[tid] = a + b;
}第一个线程束内的线程编号tid从0到31,tid/warpSize都等于0,那么就都执行if语句。
第二个线程束内的线程编号tid从32到63,tid/warpSize都等于1,执行else语句。
线程束内没有分支,效率较高。
分支效率被定义为未分化的分支与全部分支之比:
分支效率=100*[(分支数-分化分支数)/分支数]
并行规约问题
N个元素的整数数组求和:
int sum=0;
for(int i=0;i<N;i++)
sum+=array[i];并行加法求和运算:
- 将输入向量划分到更小的数据块中。
- 用一个线程计算一个数据块的部分和。
- 对每个数据块的部分和再求和得出最终结果。
成对的并行求和实现可以被进一步分为以下两种:
- 相邻配对
- 交错配对
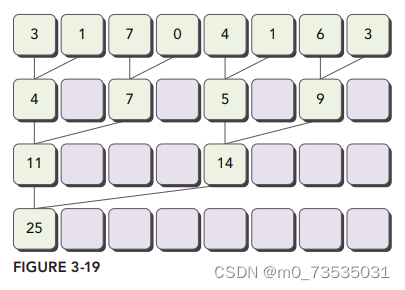
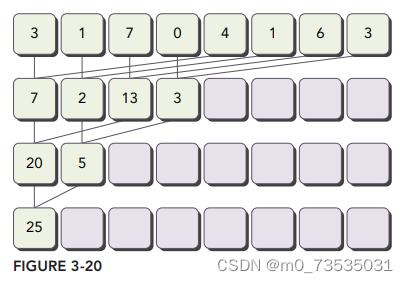
并行归约中的分化
两个全局内存数组:一个大数组用来存放整个数组,进行归约;另一个小数组用来存放每个线程块的部分和。__syncthreads(同步指令)语句可以保证,线程块中任一线程在进入下一次迭代之前,在当前迭代里每个线程的所有部分和都被保存在了全局内存中。
两个相邻元素间的距离称为跨度(stride),初始化均为1。每一次的规约循环结束后,这个间隔被乘以2。在第一次循环结束后,idata(全局数据指针)的偶数元素将会被部分和替代。在第二次循环结束后,idata的每四个元素将会被新产生的部分和替代。因为线程块间无法同步,所以每个线程块产生的部分和被复制回了主机,在那进行串行求和。

__global__ void reduceNeighbored(int* g_idata, int* g_odata, unsigned int n) {
//set thread ID
unsigned int tid = threadIdx.x;
//convert global data pointer to the local pointer of this block
int* idata = g_idata + blockIdx.x * blockDim.x;
//boundary check
if (idx >= n) return;
//in-place reduction in global memory
for (int stride = 1; stride < blockDim.x; stride *= 2) {
if ((tid % (2 * stride))== 0) {
idata[tid] += idata[tid + stride];
}
//synchronize within block
__syncthreads();
}
//write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = idata[0];
}改善并行归约的分化
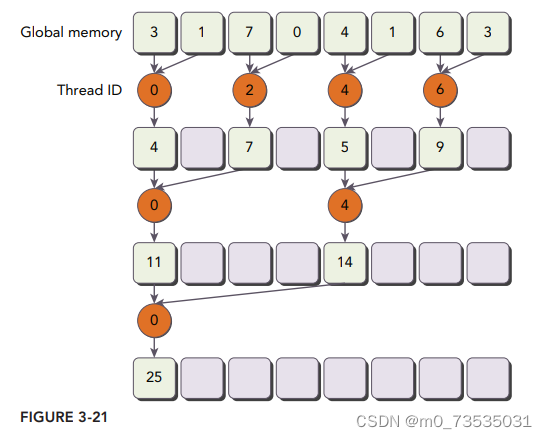
if ((tid % (2 * stride))== 0)上述语句导致很高的线程束分化。如下图所示:
第一轮,有1/2的线程没用;
第二轮,有3/4的线程没用;
第三轮,有7/8的线程没用。
通过重新组织每个线程的数组索引来强制ID相邻的线程执行求和操作,线程束分化就能被归约了。如下图所示:

__global__ void reduceNeighbored(int* g_idata, int* g_odata, unsigned int n) {
//set thread ID
unsigned int tid = threadIdx.x;
unsigned int idx = blockIdx.x * blockDim.x + threadIdx.x;
//convert global data pointer to the local pointer of this block
int* idata = g_idata + blockIdx.x * blockDim.x;
//boundary check
if (idx >= n) return;
//in-place reduction in global memory
for (int stride = 1; stride < blockDim.x; stride *= 2) {
//convert tid into local array index
int index = 2 * stride * tid; //为每个线程设置数组访问索引
if (index<blockDim.x) { //使用线程块前半部分来执行求和操作
idata[index] += idata[index + stride];
}
//synchronize within block
__syncthreads(); //保证线程块中任一线程在进入下一次迭代之前,
}
//write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = idata[0];
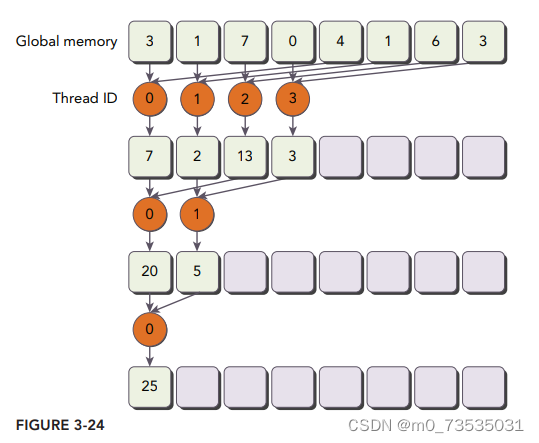
}交错配对的归约
初始跨度(stride)是线程块大小的一半,然后每次迭代中减少一半。
//Interleaved Pair Implementation with less divergence
__global__ void reduceInterleaved(int* g_idata, int* g_odata, unsigned int n) {
//set thread ID
unsigned int tid = threadIdx.x;
unsigned int idx = blockIdx.x * blockDim.x + threadIdx.x;
//convert global data pointer to the local pointer of this block
int* idata = g_idata + blockIdx.x * blockDim.x;
//boundary check
if (idx >= n) return;
//in-place reduction in global memory
for (int stride = blockDim.x / 2; stride > 0;stride>>=1) {
if (tid<stride) {
idata[tid] += idata[tid+ stride];
}
//synchronize within block
__syncthreads(); //保证线程块中任一线程在进入下一次迭代之前,
}
//write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = idata[0];
}函数中的下述语句,每个元素间的跨度被初始化为线程块大小的一半,然后在每次循环中减少一半:
for (int stride = blockDim.x / 2; stride > 0;stride>>=1)下述语句在第一次迭代时强制线程块中的前半部分线程执行求和操作,第二次迭代时是线程块的前四分之一:
if (tid<stride)展开循环
循环展开是一个尝试通过减少分支出现的频率和循环维护指令来优化循环的技术。循环体的复制数量被称为循环展开因子,迭代次数就变为了原始循环迭代次数除以循环展开因子。
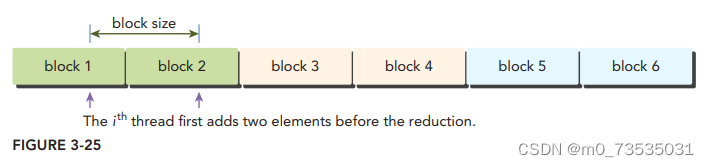
__global__ void reduceUnrolling2(int* g_idata, int* g_odata, unsigned int n) {
//set thread ID
unsigned int tid = threadIdx.x;
unsigned int idx = blockIdx.x * blockDim.x*2 + threadIdx.x;
//convert global data pointer to the local pointer of this block
int* idata = g_idata + blockIdx.x * blockDim.x*2;
//boundary check
if (idx +blockDim.x<n) g_idata[idx]+=g_idata[idx+blockDim.x];
__syncthreads();
//in-place reduction in global memory
for (int stride = blockDim.x / 2; stride > 0; stride >>= 1) {
if (tid < stride) {
idata[tid] += idata[tid + stride];
}
//synchronize within block
__syncthreads(); //保证线程块中任一线程在进入下一次迭代之前,
}
//write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = idata[0];
}
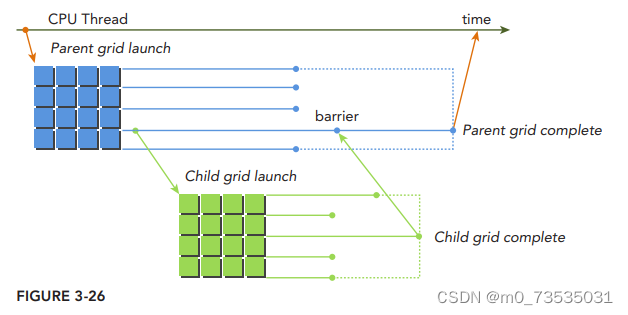
动态并行
CUDA的动态并行允许在GPU端直接创建和同步新的GPU内核。有了动态并行,可以推迟到运行时决定要在GPU上创建多少个块和网格,可以动态地利用GPU硬件调度器和加载平衡器,并进行调整以适应数据驱动或工作负载。
嵌套执行
在动态并行中,内核执行分为两种类型:父母和孩子。
















 2731
2731











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









