






并行计算通常涉及两个不同的计算技术领域:
-
计算机架构(硬件方面):关注在结构级别上支持并行
-
并行程序设计(软件方面):关注的是充分使用计算机架构的计算能力来并发解决问题

哈佛结构
单核处理器:一个芯片上只有一个CPU
多核处理器:将多个CPU集成到单一处理器上,以在体系结构级别支持并行性
并行程序设计可以看作是将一个问题的计算分配给可用的核心以实现并行的过程。
串行程序:计算机程序解决一个问题时,会很自然的把这个问题分成许多运算块,每个运算块执行一个指定任务。
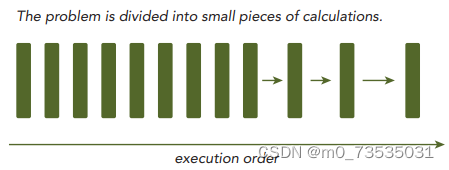
并行程序:有些是有执行次序的,所以必须串行执行;其他的没有执行次序的约束,则可以并发执行。所有包含并发执行任务的程序都是并行程序。一个并行程序中可能会有一些串行部分。
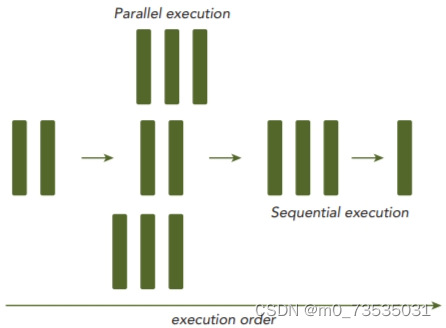
两种基本并行类型:
-
任务并行:许多任务或函数可以独立地、大规模地并行执行。重点在于利用多核系统对任务进行分配。
-
数据并行:同时处理许多数据。重点在于利用多核系统对数据进行分配。CUDA编程适合解决数据并行计算问题。数据并行处理可以将数据映射给并行线程。
数据并行程序设计第一步是把数据依据线程进行划分,以使每个线程处理一部分数据。有两种数据划分方法:
-
块划分:一组连续的数据被分到一个块内,每个数据块以任意次序被安排给一个线程,线程通常在同一时间只处理一个数据块。
-
周期划分:更少的数据被分到一个块内,相邻的线程处理相邻的数据块,每个线程可以处理多个数据块。为一个待处理的线程选择一个新的块,就意味着要跳过和现有线程一样多的数据块。
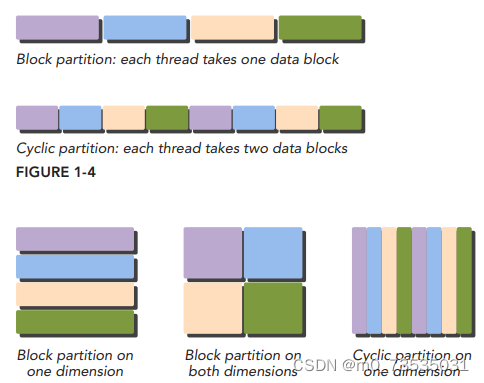
通常数据是在一维空间中存储的。即便是多维逻辑数据,仍要被映射到一维物理地址空间中。
根据指令和数据进入CPU的方式,将计算机架构分为4种不同的类型:
-
SISD:单指令单数据。一种串行架构,在这种计算机上只有一个CPU。在任何时间点上只有一个指令流在处理一个数据流。
-
SIMD:单指令多数据。一种并行架构,在这种计算机上有多个CPU。在任何时间点上所有CPU只有一个指令流处理不同的数据流。向量机是一种典型SIMD类型的计算机。SIMD的优势是 ,在CPU上编写代码时,程序员可以按串行逻辑思考但对并行数据操作实现并行加速,其他细节由编译器来负责。
-
MISD:多指令单数据。
-
MIMD:多指令多数据。多个核心使用多个指令流来异步处理多个数据流,从而实现空间上的并行性。许多MIMD架构还包括SIMD执行的子组件。

为了实现以下目的,在架构层次上已经取得了许多进展:
-
降低延迟:延迟是一个操作从开始到完成所需要的时间,常用微秒来表示。
-
提高带宽:带宽是单位时间内可处理的数据量,通常表示为MB/s或GB/s。
-
提高吞吐量:吞吐量是单位时间内成功处理的运算数量,通常表示为gflops。
延迟用来衡量完成一次操作的时间,而吞吐量用来衡量在给定的单位时间内处理的操作量。
计算机架构也能根据内存组织方式进一步划分:
-
分布式内存的多节点系统:大型计算引擎是由许多网络连接的处理器构成的,每个处理器有自己的本地内存,而且处理器之间可以通过网络进行通信。
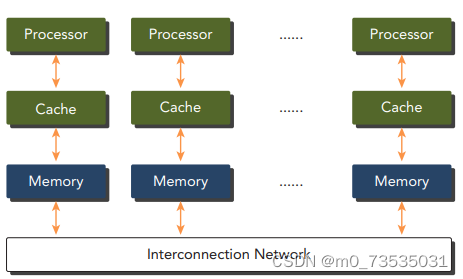
典型的分布式内存的多节点系统,这种系统通常被称作集群
-
共享内存的多处理器系统:多处理器架构的大小通常是从双处理器到几十个或几百个处理器之间。要么是与同一个物理内存相关联,要么共用一个低延迟链路(如PCI-Express或PCIe)。
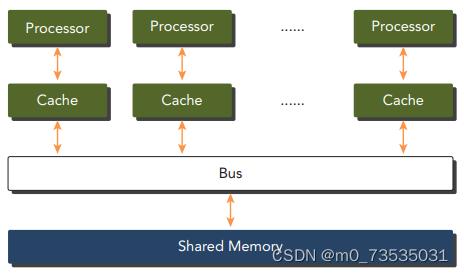
众核:通常是指有很多核心(几十或几百个)的多核架构。GPU代表一种众核架构,几乎包括了前文描述的所有并行结构:多线程、MIMD、SIMD,以及指令级并行。NVIDIA称这种架构为SIMT。
异构计算:CPU和GPU是两个独立的处理器,它们通过单个计算节点中的PCI-Express总线相连。异构计算使用一个处理器架构来执行一个应用,为任务选择适合它的架构,使其最终对性能有所改进。
一个异构应用包括两个部分:
-
主机代码:在CPU上运行
-
设备代码:在GPU上运行
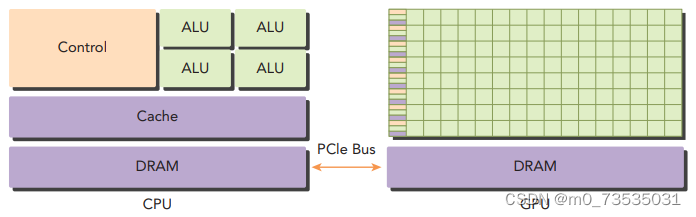
描述GPU容量的两个重要特征:
-
CUDA核心数量
-
内存大小
评估GPU性能的指标:
-
峰值计算性能:通常定义为每秒能处理的单精度或双精度浮点运算数量,通常用GFlops或TFlops来表示。
-
内存带宽:从内存中读取或写入数据的比率,通常用GB/s表示。
可以从两个方面来区分CPU和GPU应用的范围:
-
并行级
-
数据规模

为了获得最佳性能,可以同时使用CPU和GPU来执行应用程序,在CPU上执行串行部分或任务并行部分,在GPU上执行数据密集型并行部分。这种代码的编写方式能保证GPU与CPU相辅相成,从而使CPU+GPU系统的计算能力 得以充分利用。为了支持使用CPU+GPU异构系统架构来执行应用程序,NVIDIA设计了 一个被称为CUDA的编程模型。

CPU线程:通常是重量级实体,操作系统必须交替线程使用启用或关闭CPU执行通道以提供多线程处理功能。上下文的切换缓慢且开销大。
GPU线程:GPU上的线程是高度轻量级的。在一个典型的系统中会有成千上万的线程排队等待工作。如果GPU必须等待一组线程执行结束,那么它只要调用另一组线程执行其他任务即可。 CPU的核被设计用来尽可能减少一个或两个线程运行时间的延迟,而GPU的核是用来处理大量并发的、轻量级的线程,以最大限度地提高吞吐量。
CUDA提供了两层API来管理GPU设备和组织线程:
-
CUDA驱动时API:低级API。
-
CUDA运行时API:高级API。每个运行时API函数都被分解为更多传给驱动API的基本运算。
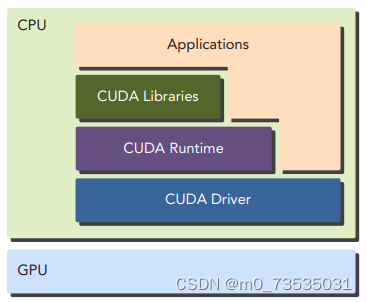
主机代码是标准的C代码,使用C编译器进行编译。设备代码,也就是核函数, 是用扩展的带有标记数据并行函数关键字的CUDA C语言编写的。设备代码通过nvcc进行 编译。在链接阶段,在内核程序调用和显示GPU设备操作中添加CUDA运行时库。
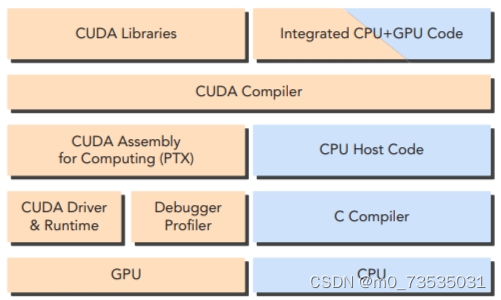
CUDA nvcc编译器是以广泛使用LLVM开源编译系统为基础的。在GPU加速器的支持下,通过使用CUDA编译器SDK,可以创建或扩展编程语言。
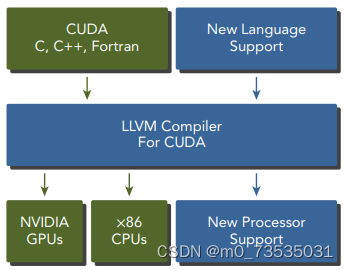
CUDA平台也是支持多样化并行计算生态系统的基础。

环境配置:(24条消息) 图文并茂讲解CUDA, CUDA Toolkit, CUDA Driver, CUDA Runtime, nvcc之间的关系及其版本兼容性_仝竞奇的博客-CSDN博客
Linux 下的 CUDA 安装和使用指南 - 知乎 (zhihu.com)
注:虚拟机没法使用cuda,因为虚拟机环境下无法识别到显卡版本,只有一个虚拟机的环境。
写一个CUDA C程序步骤:
-
用专用扩展名.cu来创建一个源文件
-
使用CUDA nvcc编译器来编译程序
-
从命令行运行可执行文件,这个文件有可在GPU上运行的内核代码
在linux下运行cuda的.cu文件:
举个例子:test.cu
编译:nvcc -o test test.cu
运行:./test
检查CUDA编译器是否安装正确:

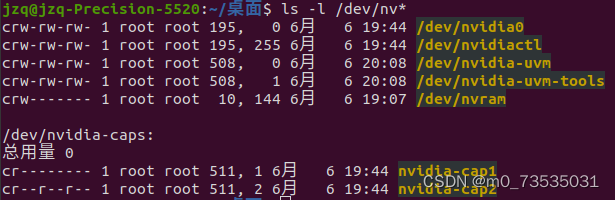
检查机器上是否安装了GPU加速卡:
__global__:内核函数,告诉编译器这个函数从CPU调用,在GPU上执行
helloFromGPU<<<1,10>>>();:三重尖括号意味着从主线程到设备端代码的调用。一个内核函数通过一组线程来执行,所有线程执行相同的代码。
cudaDeviceRest():显式的释放和清空当前进程中与当前设备有关的所有资源
#include <stdio.h>
__global__ void helloFromGPU(void) {
printf("Hello World from GPU!\n");
}
int main(void) {
printf("Hello World from CPU!\n");
//启动内核函数
helloFromGPU << <1, 10 >> > (); //有10个GPU线程被调用
cudaDeviceReset();
//cudaDeviceSynchronize();
return 0;
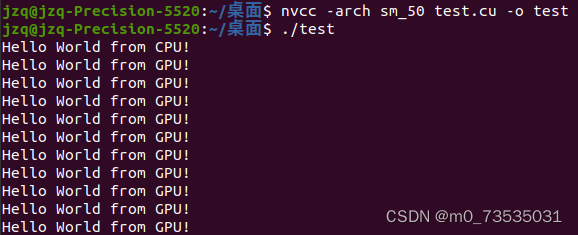
}编译此段代码需要查GPU算力,可以查看CUDA GPU | NVIDIA Developer,比如GPU是Quadro M1200,对应的算力是5,则写成sm_50或compute_50。然后进行编译和运行,结果如下:
典型CUDA编程结构包括5个主要步骤:
-
分配GPU内存
-
从CPU内存中拷贝数据到GPU内存
-
调用CUDA内核函数来完成程序指定的运算
-
将数据从GPU拷回CPU内存
-
释放GPU内存空间
cuda Error_t cudaMalloc(void** devPtr,size_t size):用于执行GPU内存分配,向设备分配一定字节的线性内存,并以devPtr的形式返回指向所分配内存的指针。
cudaError_t cudaMemcpy(void* dst,const void* src,size_t count,cudaMemcpyKind kind):负责主机和设备之间的数据传输,从src指向的源存储区复制一定数量的字节到dst指向的目标存储区,复制方向由kind指定。
kind种类:
cudaMemcpyHostToHost
cudaMemcpyHostToDevice
cudaMemcpyDeviceToHost:将存在GPU上的计算结果复制到主机的数组gpuRef中
cudaMemcpyDeviceToDevice
cudaMemcpy()以同步方式执行,在cudaMemcpy函数返回以及传输操作完成之前主机应用程序是阻塞的。除了内核启动之外的CUDA调用都会返回一个错误的枚举类型cudaError_t。如果GPU内存分配成功,函数返回cudaSuccess,否则返回cudaErrorMemoryAllocation。
char* cudaGetErrorString(cudaError_t error):CUDA运行时函数将错误代码转化为可读的错误消息。与C语言中的strerror函数类似。
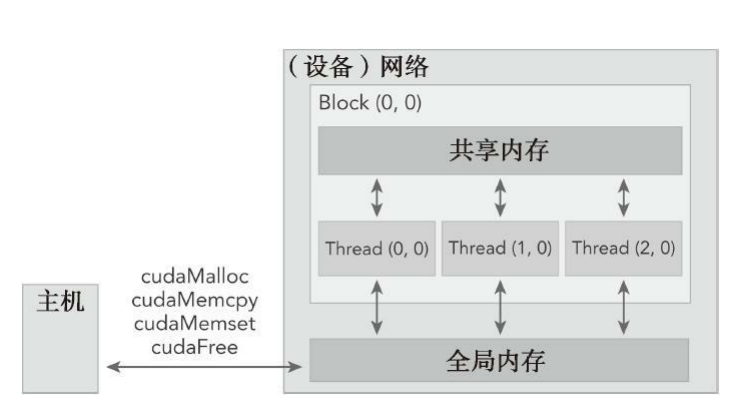
在GPU内存层次结构中,最主要的两种内存是全局内存和共享内存。全局类似于CPU的系统内存,而共享内存类似于CPU的缓存。然而GPU的共享内存可以由CUDA C的内核直接控制。
//主机端数组相加,C语言实现
#include <stdlib.h>
#include <string.h>
#include <time.h>
void sumArraysOnHost(float* A, float* B, float* C, const int N) {
for (int idx = 0; idx < N; idx++) {
C[idx] = A[idx] + B[idx];
}
}
void initialData(float* ip, int size) {
time_t t;
srand((unsigned int)time(&t));
for (int i = 0; i < size; i++) {
ip[i] = (float)(rand() & 0xFF) / 10.0f;
}
}
int main(int argc, char** argv) {
int nElem = 1024;
size_t nBytes = nElem * sizeof(float);
float* h_A, * h_B, * h_C;
h_A = (float*)malloc(nBytes);
h_B = (float*)malloc(nBytes);
h_C = (float*)malloc(nBytes);
initialData(h_A, nElem);
initialData(h_B, nElem);
sumArraysOnHost(h_A, h_B, h_C, nElem);
free(h_A);
free(h_B);
free(h_C);
return(0);
}
//nvcc -Xcompiler -std=c99 sumArraysOnHost.c -o sum
//./sum
//-Xcompiler用于指定命令行选项是指向C编译器还是预处理器
//将-std=c99传递给编译器,这里的C程序是按照C99标准写的//GPU上实现数组相加
//用cudaMalloc在GPU上申请内存
float* d_A, * d_B, * d_C;
cudaMalloc((float**)&d_A,nBytes));
cudaMalloc((float**)&d_B,nBytes));
cudaMalloc((float**)&d_C,nBytes));
//使用cudaMemcpy函数把数据从主机内存拷贝到GPU全局内存中
//cudaMemcpyHostToDevice指定数据拷贝方向
cudaMemcpy(d_A, h_A, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, nBytes, cudaMemcpyHostToDevice);
//用cudaMemcpy函数把结果从GPU复制回主机的数组gpuref中
cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost);
//调用cudaFree释放GPU内存
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);gpuRef:把结果从GPU复制回到主机的数组gpuRef中
dim3 block(5,3)
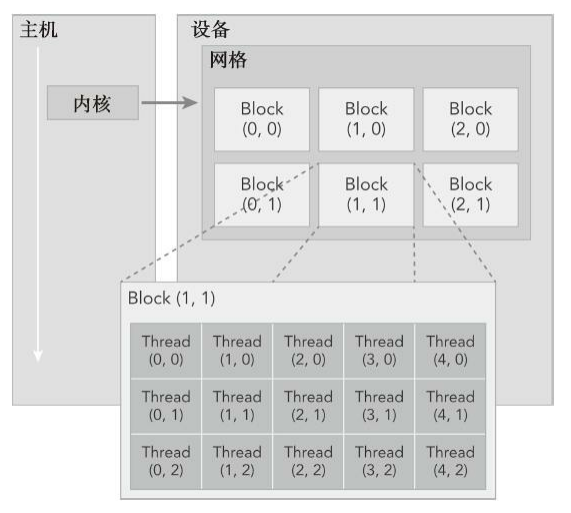
由一个内核启动所产生的所有线程统称为一个网格。同一网格中的所有线程共享相同的全局内存空间。一个网格由多个线程块构成,一个线程块包含一组线程,同一线程块内的线程协作可以通过同步和共享内存来实现。不同块内的线程不能协作。
- blockIdx:线程块在线程格内的索引,可以通过x、y、z三个字段来指定(blockIdx.x、blockIdx.y、blockIdx.z)
- threadIdx:块内的线程索引(threadIdx.x、threadIdx.y、threadIdx.z)
这些变量是核函数中需要预初始化的内置变量(例:int)。当执行一个核函数时,CUDA运行时为每个线程分配坐标变量blockIdx和threadIdx。基于这些坐标,可以将部分数据分配给不同的线程。
- blockDim:线程块的维度,用每个线程块中的线程数来表示,dim3类型变量,当定义一个dim3类型的变量时,所有未指定的元素都被初始化为1(blockDim.x,blockDim.y,blockDim.z)
- gridDim:线程格的维度,用每个线程格中的线程数来表示
一个线程格会被组织成线程块的二维数组形式,一个线程块会被组织成线程的三维数组形式。

//代码清单2-2 检查网格和块的索引和维度
//cuda_runtime会生成相应的内置预初始化的网格、块和线程变量
#include <cuda_runtime.h>
#include <stdio.h>
//在核函数中,每个线程都输出自己的线程索引、块索引、块维度和网格维度
__global__ void checkIndex(void) {
printf("threadIdx:(%d,%d,%d) blockIdx:(%d,%d,%d) blockDim(%d,%d,%d)"
"gridDim:(%d,%d,%d)\n", threadIdx.x, threadIdx.y, threadIdx.z,
blockIdx.x, blockIdx.y, blockIdx.z, blockDim.x, blockDim.y, blockDim.z,
gridDim.x, gridDim.y, gridDim.z);
}
int main(int argc, char** argv) {
//定义程序所用的数据大小
int nElem = 6;
//线程格和线程块均使用3个dim3类型的无符号整型字段,未使用的字段将被初始化为1且忽略不计
//包含3个线程的一维线程块
dim3 block (3);
//一个基于块和数据大小定义的一定数量线程块的一维线程网格
dim3 grid((nElem + block.x - 1) / block.x);
//主机端检查网格和块维度
printf("grid.x %d grid.y %d grid.z %d\n", grid.x, grid.y, grid.z);
printf("block.x %d block.y %d block.z %d\n", block.x, block.y, block.z);
//grid个线程块,每个线程块有block个线程
checkIndex << <grid, block >> > ();
cudaDeviceReset();
return(0);
}
//nvcc -arch=sm_50 checkDimension.cu -o check
//./check运行结果:
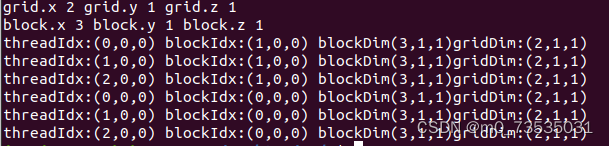
//代码清单2-3 在主机上定义网格和块的大小
#include <cuda_runtime.h>
#include <stdio.h>
int main(int argc, char** argv) {
//总数据元素量
int nElem = 1024;
//包含1024个线程的一维线程块
dim3 block(1024);
//一个基于块和数据大小定义的一定数量线程块的一维线程网格
dim3 grid((nElem + block.x - 1) / block.x);
printf("grid.x %d block.x %d\n", grid.x, block.x);
//重置block
block.x = 512;
grid.x = (nElem + block.x - 1) / block.x;
printf("grid.x %d block.x %d\n", grid.x, block.x);
//重置block
block.x = 256;
grid.x = (nElem + block.x - 1) / block.x;
printf("grid.x %d block.x %d\n", grid.x, block.x);
//重置block
block.x = 128;
grid.x = (nElem + block.x - 1) / block.x;
printf("grid.x %d block.x %d\n", grid.x, block.x);
cudaDeviceReset();
return(0);
}
//nvcc defineGridBlock.cu -o block
//./block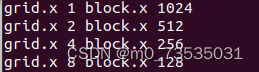
一个给定的数据大小,确定网格尺寸大小一般步骤为:
- 确定块的大小
- 在已知数据大小和块大小的基础上计算网格维度
要确定块尺寸,通常需要考虑:
- 内核性能
- GPU资源限制
C语言函数调用语句:function_name (argument list);
CUDA内核调用:kernel_name<<<grid,block>>>(argument list);
同一个块中的线程之间可以相互协作,不同块内的线程不能协作。
kernel_name<<<4,8>>>(argument list);
cudaError_t cudaDeviceSynchronize(void):强制主机端程序等待所有的核函数执行结束
异步行为:不同于C语言函数调用,所有CUDA核函数的启动都是异步的。CUDA内核调用完成后,控制权立刻返回给CPU。
核函数:__global__ void kernel_name(argument list);

核函数限制:只能访问设备内存;必须有一个void返回类型;不支持可变数量的参数;不支持静态变量;显示异步行为。
CHECK(cudaDeviceSynchronize()):会阻塞主机端线程的运行直到设备端所有的请求任务都结束,并确保最后的核函数启动部分不会出错。
//基于GPU的向量加法
#include <cuda_runtime.h>
#include <stdio.h>
#include <device_launch_parameters.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
//许多CUDA调用是异步的,所以有时候很难确定某个错误是由哪一步程序引起的
//定义一个错误处理宏封装所有的CUDA API调用,简化错误检查的过程
//定义宏过长,可以分成几行,每一行后面都加一个续行符(\)
#define CHECK(call){ \
const cudaError_t error = call; \
if (error != cudaSuccess) { \
printf("Error:%s:%d,",__FILE__, __LINE__); \
printf("code:%d,reason:%s\n", error, cudaGetErrorString(error)); \
exit(1); \
} \
} \
//主机函数:目的是验证核函数的结果是否正确
void checkResult(float* hostRef, float* gpuRef, const int N) {
double epsilon = 1.0E-8; //1.0*10^(-8)
bool match = 1;
for (int i = 0; i < N; i++) {
//计算绝对值,返回正数或负数的相反数
//cudaMemcpy函数把结果从GPU复制回到主机的数组gpuRef中
if (abs(hostRef[i] - gpuRef[i]) > epsilon) {
match = 0;
printf("Arrays do not match!\n");
//%m.nf中m代表输出数长,n代表小数点后的数长,即保留n位小数
printf("host %5.2f gpu %5.2f at current %d\n", hostRef[i],gpuRef[i], i);
break;
}
}
if (match) printf("Arrays match.\n\n");
}
//生成随机数
void initialData(float* ip, int size) {
time_t t;
srand((unsigned)time(&t));
for (int i = 0; i < size; i++) {
ip[i] = (float)(rand() & 0xFF) / 10.0f;
}
}
//主机端的向量加法C代码:将两个大小为N的向量A和B相加
void sumArrayOnHost(float* A, float* B, float* C,const int N) {
for (int idx = 0; idx < N; idx++)
C[idx] = A[idx] + B[idx];
}
//核函数:内置的线程坐标变量替换了数组索引
__global__ void sumArrayOnGPU(float* A, float* B, float* C) {
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main(int argc, char** argv) {
printf("%s Starting...\n", argv[0]);
//set up device
int dev = 0;
cudaSetDevice(dev);
//set up data size of vectors
int nElem = 32; //向量大小:32
printf("Vector size %d\n", nElem);
//malloc host memory
size_t nBytes = nElem * sizeof(float);
float* h_A, * h_B, * hostRef, * gpuRef;
h_A = (float*)malloc(nBytes);
h_B = (float*)malloc(nBytes);
hostRef = (float*)malloc(nBytes);
gpuRef = (float*)malloc(nBytes);
//initialize data at host side
initialData(h_A, nElem);
initialData(h_B, nElem);
//memset:作用是在一段内存中填充某个给定的值
memset(hostRef, 0, nBytes);
memset(gpuRef, 0, nBytes);
//malloc device global memory
float* d_A, * d_B, * d_C;
cudaMalloc((float**)&d_A, nBytes);
cudaMalloc((float**)&d_B, nBytes);
cudaMalloc((float**)&d_C, nBytes);
//transfer data from host to device
cudaMemcpy(d_A, h_A, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, nBytes, cudaMemcpyHostToDevice);
//invoke(调用) kernel at host side
dim3 block(nElem); //每个块有(nElem,1,1)个线程
dim3 grid(nElem / block.x); //网格中有(nElem/block.x,1,1)个块
sumArrayOnGPU << <grid, block >> > (d_A, d_B, d_C);
printf("Execution configuration <<<%d,%d>>>\n", grid.x, block.x); //Execution configuration:执行配置
//copy kernel result back to host side
cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost);
//add vector(矢量) at host side for result checks
sumArrayOnHost(h_A, h_B, hostRef, nElem);
//check device results
checkResult(hostRef, gpuRef, nElem);
//free device global memory
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
//free host memory
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
return(0);
}gettimeofday系统调用:创建一个CPU计时器,以获取系统的时钟时间。它将返回自1970年1月1日零点以来到现在的秒数。程序中需要添加sys/time.h
//代码清单2-5 测试向量加法的核函数
#include <cuda_runtime.h>
#include <stdio.h>
#include <sys/time.h>
double cpuSecond() {
struct timeval tp;
gettimeofday(&tp, NULL);
return ((double)tp.tv_sec + (double)tp.tv_usec * 1.e-6);
}
__global__ void sumArraysOnGPU(float* A, float* B, float* C,const int N) {
int i = blockIdx.x*blockDim.x+threadIdx.x;
if(i<N) C[i] = A[i] + B[i];
}
int main(int argc, char** argv) {
printf("%s Starting...\n", argv[0]);
//set up device
int dev = 0;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
printf("Using Device %d:%s\n", dev, deviceProp.name);
CHECK(cudaSetDevice(dev));
//set up data size of vectors
int nElem = 1 << 24; //a<<b:a化成二进制数,然后向左移动b个位置
printf("Vector size %d\n", nElem);
//malloc host memory
size_t nBytes = nElem * sizeof(float);
float* h_A, * h_B, * hostRef, * gpuRef;
h_A = (float*)malloc(nBytes);
h_B = (float*)malloc(nBytes);
hostRef = (float*)malloc(nBytes);
gpuRef = (float*)malloc(nBytes);
double iStart, iElaps;
//initialize data at host side
iStart = cpuSecond();
initialData(h_A, nElem);
initialData(h_B, nElem);
iElaps = cpuSecond() - iStart;
memset(hostRef, 0, nBytes);
memset(gpuRef, 0, nBytes);
//add vector at host side for result checks
iStart = cpuSecond();
sumArraysOnHost(h_A, h_B, hostRef, nElem);
iElaps = cpuSecond() - iStart; //iElaps表示核函数执行时间
//malloc device global memory
float* d_A, * d_B, * d_C;
cudaMalloc((float**)&d_A, nBytes);
cudaMalloc((float**)&d_B, nBytes);
cudaMalloc((float**)&d_C, nBytes);
//transfer data from host to device
cudaMemcpy(d_A, h_A, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, nBytes, cudaMemcpyHostToDevice);
//invoke kernel at host side
int iLen = 1024;
dim3 block(iLen);
dim3 grid((nElem + block.x - 1) / block.x);
iStart = cpuSecond();
sumArraysOnGPU << <grid, block >> > (d_A, d_B, d_C, nElem);
cudaDeviceSynchronize();
iElaps = cpuSecond() - iStart;
printf("sumArraysOnGPU<<<%d,%d>>>Time elapsed %f" \
"sec\n", grid.x, block.x, iElaps);
//copy kernel result back to host side
cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost);
//check device results
checkResult(hostRef, gpuRef, nElem);
//free device global memory
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
//free host memory
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
return(0);
}通常,矩阵用行优先的方法在全局内存中进行线性存储。
在矩阵加法核函数中,一个线程通常被分配一个数据元素来处理。首先要完成的任务是使用块和线程索引从全局内存中访问指定的数据。
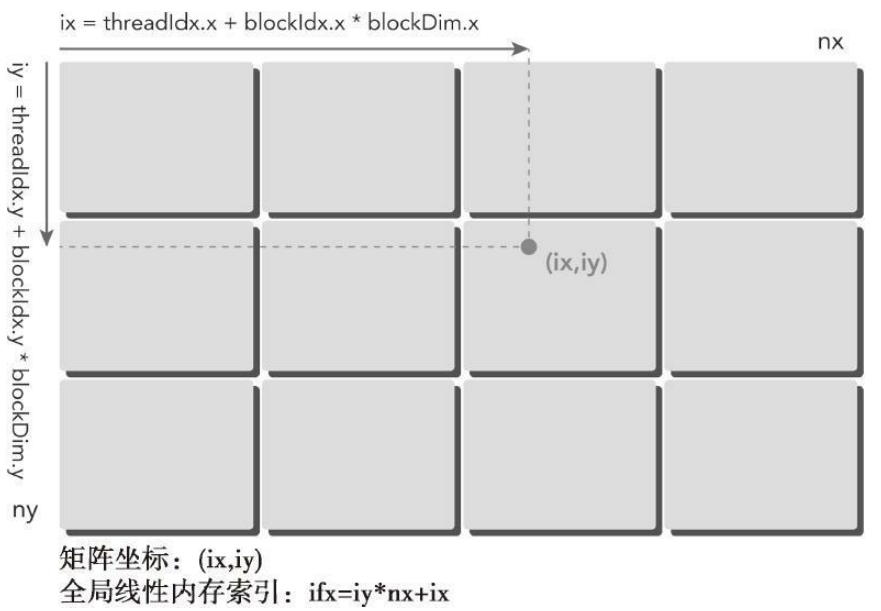
通常,对于一个二维示例来说,需要管理3种索引:
-
线程和块索引(计算线程的全局索引)
-
矩阵中给定点的坐标(ix,iy)
-
全局线性内存中的偏移量((ix,iy)对应的线性内存的位置)
第一步,把线程的块索引映射到矩阵坐标上
ix=threadIdx.x+block.x*blockDim.x
iy=threadIdx.y+block.y*blockDim.y
第二步,把矩阵坐标映射到全局内存中的存储单元上
idx=iy*nx+ix

//代码清单2-6 检查块和线程索引
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
//2.1.7 CUDA调用是异步的,有时候很难确定某个错误是由哪一步程序引起的
//定义一个错误处理宏封装所有的CUDA API调用,简化错误检查过程
#define CHECK(call){ \
const cudaError_t error = call; \
if (error != cudaSuccess) { \
printf("Error:%s:%d,",__FILE__, __LINE__); \
printf("code:%d,reason:%s\n", error, cudaGetErrorString(error)); \
exit(1); \
} \
} \
void initialInt(int* ip, int size) {
for (int i = 0; i < size; i++) {
ip[i] = i;
}
}
void printMatrix(int* C, const int nx, const int ny) {
int* ic = C;
printf("\nMatrix:(%d.%d)\n", nx, ny);
for (int iy = 0; iy < ny; iy++) {
for (int ix = 0; ix < nx; ix++) {
printf("%3d", ic[ix]);
}
ic += nx;
printf("\n");
}
printf("\n");
}
__global__ void printThreadIndex(int* A, const int nx, const int ny) {
int ix = threadIdx.x + blockIdx.x * blockDim.x;
int iy = threadIdx.y + blockIdx.y * blockDim.y;
unsigned int idx = iy * nx + ix;
printf("thread_id(%d,%d) block_id(%d,%d) coordinate"
"global index %2d ival %2d\n", threadIdx.x, threadIdx.y, blockIdx.x,
blockIdx.y, ix, iy, idx, A[idx]);
}
int main(int argc, char** argv) {
printf("%s Starting...\n", argv[0]);
//get device information
int dev = 0;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
printf("Using Device %d:%s\n", dev, deviceProp.name);
CHECK(cudaSetDevice(dev));
//set matrix dimension
int nx = 8;
int ny = 6;
int nxy = nx * ny;
int nBytes = nxy * sizeof(float);
//malloc host memory
int* h_A;
h_A = (int*)malloc(nBytes);
//initializa host matrix with integer
initialInt(h_A, nxy);
printMatrix(h_A, nx, ny);
//malloc device memory
int* d_MatA;
cudaMalloc((void**)&d_MatA, nBytes);
//transfer data fron host to device
cudaMemcpy(d_MatA, h_A, nBytes, cudaMemcpyHostToDevice);
//set up execution configuration
dim3 block(4, 2);
dim3 grid((nx + block.x - 1) / block.x, (ny + block.y - 1) / block.y);
//invoke the kernel
printThreadIndex << <grid, block >> > (d_MatA, nx, ny);
//free host and device memory
cudaFree(d_MatA);
free(h_A);
//reset device
cudaDeviceReset();
return(0);
}
//代码清单2-7 使用一个二维网格和二维块的矩阵加法。没跑通...
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
#include <time.h>
#define CHECK(call){ \
const cudaError_t error = call; \
if (error != cudaSuccess) { \
printf("Error:%s:%d,",__FILE__, __LINE__); \
printf("code:%d,reason:%s\n", error, cudaGetErrorString(error)); \
exit(1); \
} \
} \
void checkResult(float* hostRef, float* gpuRef, const int N) {
double epsilon = 1.0E-8; //1.0*10^(-8)
bool match = 1;
for (int i = 0; i < N; i++) {
if (abs(hostRef[i] - gpuRef[i]) > epsilon) { //cudaMemcpy函数把结果从GPU复制回到主机的数组gpuRef中
match = 0;
printf("Arrays do not match!\n");
printf("host %5.2f gpu %5.2f at current %d\n", hostRef[i], gpuRef[i], i);
break;
}
}
if (match) printf("Arrays match.\n\n");
}
double cpuSecond() {
struct timeval tp;
gettimeofday(&tp, NULL);
return ((double)tp.tv_sec + (double)tp.tv_usec * 1.e-6);
}
struct timeval {
long tv_sec;/*秒*/
long tv_usec;/*微妙*/
};
struct timezone {
int tz_minuteswest;/*和greenwich时间差*/
int tz_dsttime;
};
int gettimeofday(struct timeval* tv, struct timezone* tz);
void initialData(float* ip, int size) {
time_t t;
srand((unsigned)time(&t));
for (int i = 0; i < size; i++) {
ip[i] = (float)(rand() & 0xFF) / 10.0f;
}
}
//主函数:用于校验矩阵加法核函数是否能得出正确的结果
void sumMatrixOnHost(float* A, float* B, float* C, const int nx, const int ny) {
float* ia = A;
float* ib = B;
float* ic = C;
for (int iy = 0; iy < ny; iy++) {
for (int ix = 0; ix < nx; ix++) {
ic[ix] = ia[ix] + ib[ix];
}
ia += nx; ib += nx; ic += nx;
}
}
//核函数:采用二维线程块来进行矩阵求和
__global__ void sumMatrixOnGPU2D(float* MatA, float* MatB, float* MatC, int nx, int ny) {
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;
unsigned int iy = threadIdx.y + blockIdx.y * blockDim.y;
unsigned int idx = iy * nx + ix;
if (ix < nx && iy < ny)
MatC[idx] = MatA[idx] + MatB[idx];
}
int main(int argc, char** argv) {
printf("%s Starting...\n", argv[0]);
//set up device
int dev = 0;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
printf("Using Device %d:%s\n", dev, deviceProp.name);
CHECK(cudaSetDevice(dev));
//每个维度下的矩阵大小设置为16384个元素
int nx = 1 << 14;
int ny = 1 << 14;
int nxy = nx * ny;
int nBytes = nxy * sizeof(float);
printf("Matrix size : nx % d ny % d\n", nx, ny);
//malloc host memory
float* h_A, * h_B, * hostRef, * gpuRef;
h_A = (float*)malloc(nBytes);
h_B = (float*)malloc(nBytes);
hostRef = (float*)malloc(nBytes);
gpuRef = (float*)malloc(nBytes);
//initialize data at host side
double iStart = cpuSecond();
initialData(h_A, nxy);
initialData(h_B, nxy);
double iElaps = cpuSecond() - iStart;
memset(hostRef, 0, nBytes);
memset(gpuRef, 0, nBytes);
//add matrix at host side for result checks
iStart = cpuSecond();
sumMatrixOnHost(h_A, h_B, hostRef, nx,ny);
iElaps = cpuSecond() - iStart; //iElaps表示核函数执行时间
//malloc device global memory
float* d_MatA, * d_MatB, * d_MatC;
cudaMalloc((float**)&d_MatA, nBytes);
cudaMalloc((float**)&d_MatB, nBytes);
cudaMalloc((float**)&d_MatC, nBytes);
//transfer data from host to device
cudaMemcpy(d_MatA, h_A, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy(d_MatB, h_B, nBytes, cudaMemcpyHostToDevice);
//使用一个二维网格和二维块设置核函数的执行配置
int dimx = 32;
int dimy = 32;
dim3 block(dimx, dimy);
dim3 grid((nx + block.x - 1) / block.x, (ny + block.y - 1) / block.y);
iStart = cpuSecond();
sumMatrixOnGPU2D << <grid, block >> > (d_MatA, d_MatB, d_MatC, nx,ny);
cudaDeviceSynchronize();
iElaps = cpuSecond() - iStart;
printf("sumMatrixOnGPU2D<<<(%d,%d),(%d,%d)>>>elapsed %f sec\n",grid.x, grid.y,block.x,block.y,iElaps);
//copy kernel result back to host side
cudaMemcpy(gpuRef, d_MatC, nBytes, cudaMemcpyDeviceToHost);
//check device results
checkResult(hostRef, gpuRef, nxy);
//free device global memory
cudaFree(d_MatA);
cudaFree(d_MatB);
cudaFree(d_MatC);
//free host memory
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
//reset device
cudaDeviceReset();
return(0);
}//查询GPU设备信息
cudaError_t cudaGetDeviceProperties(cudaDeviceProp* prop,int device);
















 1087
1087











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









