






一、OpenCV中的Haar分类器
在2001年,Viola和Jones发表了经典的《Rapid Object Detection using a Boosted Cascade of Simple Features》和《Robust Real-Time Face Detection》,论文中基于Adaoosting算法,使用类haar特征对人脸进行检测,并对Adaboosting得到的强分类器级联,进而可以较准确的完成人脸检测,论文中的检测器也被称为Viola-Jones检测器。之后Rainer Lienhart和Jochen Maydt发表了文章《An Extended Set of Haar-like Features for Rapid Object Detection》,文章使用了对角特征,对Viola-Jones检测器进行了扩展,这篇文章的算法,也正是OpenCV收录的Haar分类器。
二、Haar分类器的原理
(一)OpenCV中的haar特征
- haar特征的种类:
OpenCV中有三类haar特征(5种BASIC特征,3种Core特征,6种Titled特征),如下图:
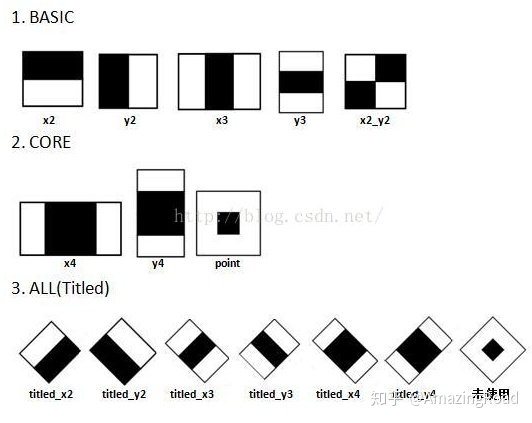
图中的黑色区域的权重为-1,白色区域权重为1。三、如何训练
2. haar特征的统计
在OpenCV的haar分类器中,默认使用的BASIC特征。我们以x3类haar特征为例,介绍如何生成haar特征。
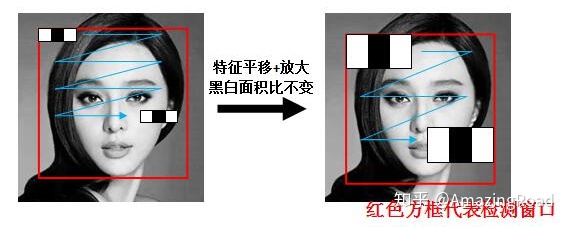
如图所示,红色框为检测区域,我们计算检测区域的haar特征。由基础的x3特征,沿x方向和y方向放大,并且在每次放大以后在检测区域内平移,会生成x3系列特征值。
假设x3特征的宽和高为w、h,检测区域的宽和高为W、H,则在x方向和y方向最大放大系数X、Y为:
产生的特征数量为:
计算时,按照x方向产生的特征数量、y方向产生的特征数量,然后相乘起来即可得到上式结果。举个例子,检测窗口为60*60时,w=3, h=1,W=H=60,一共产生1079700个子特征。
3. haar特征的计算
应用某种haar特征模板生成haar特征值时,haar特征值=整个区域像素和*权重+黑色区域像素和*权重。例如x3特征中,整个像素和的权重为1,黑色区域的权重为-3。权重的设计原则为保证白色和与黑色区域的权重和为0。
按照上述方式计算的haar特征值的范围非常大,因此在使用时,需要把haar特征值进行标准化,这里介绍OpenCV中标准化haar特征的方法:
(1)假设检测窗口为(w*h),计算(w-2)*(h-2)的图像区域的灰度值的和与平方和:
(2)计算平均值:
(3)计算标准化因子:
(4)标准化后的特征为:
4. 弱分类器和强分类器
一个完整的弱分类器包含:(1)若干haar特征和每个haar特征有一个阈值;(2)若干个leftValue和若干个rightValue。
如下图所示,是一个深度为2的弱分类器结构。
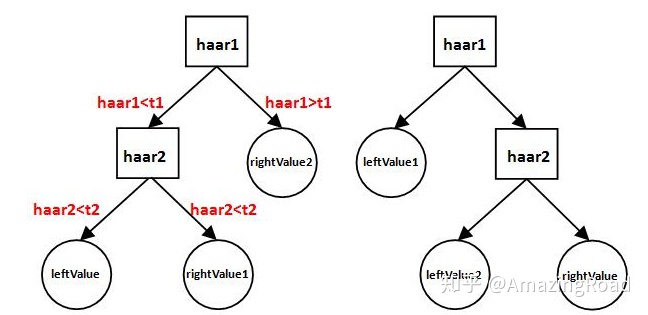
具体为:计算第一个haar特征的特征值的haar1,与阈值t1相比,如果haar1大于t1,则输出rightValue2;若haar1小于t1,则比较haar2与t2,若haar小于t2,输出leatValue,否则输出rightValue1。
强分类器是由若干个弱分类器组成的,一个强分类器里面的弱分类器相互独立。强分类器的值是弱分类器的直接求和,当强分类器的值大于强分类器的阈值时,才认为是一个目标,否则认为检测窗口不包含目标。
5. 级联分类器
强分类器是由弱分类器“并联”构成的,而级联分类器是由强分类器级联组成的。当一个检测框可以通过所有的强分类器,才认为该检测窗口包含了目标。
三、介绍训练方法
利用OpenCV的训练分类器工具,可以训练haar分类器。具体方式如下:
- 编译生成分类器工具。在编译OpenCV时,编译选项中BUILD_opencv_apps选上。如下图所示。
编译后,在build/bin目录下面生成的opencv_createsamples和opencv_traincascade两个可执行文件是我们需要的。
2. 准备正负样本。一般情况下,正样本与负样本比例小于1:5是比较合理的。使用opencv_createsamples生成用于训练的正样本文件(后缀为.vec):
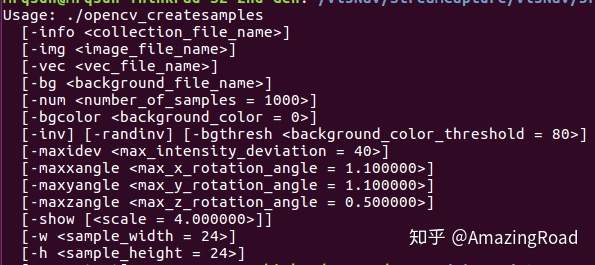
-info:用来描述正样本图片信息的文件,格式一般是txt格式。txt文件中每一行的格式为"xxx.jpg 1 0 0 20 20",每一行包含3块内容,第一个是图片的绝对路径,第二个是图片中目标数量,第三块是每一个目标框的位置(x,y,w,h)。
-vec:是生成的用于训练的正样本文件。
-num:是正样本的数量。
-show:生成过程中,是否显示每个样本。
-w:每一个正样本的宽。这个值要跟后面训练时的w值保持一致。
-h:每一个正样本的高。这个值要跟后面训练时的h值保持一致。
其他的几个参数“-img、-bg、-bgcorlor”等,是使用现有正样本进行数据增广时会用到的,一般使用默认值即可。
3. 使用opencv_traincascade训练分类器。训练时的参数列表如下图:
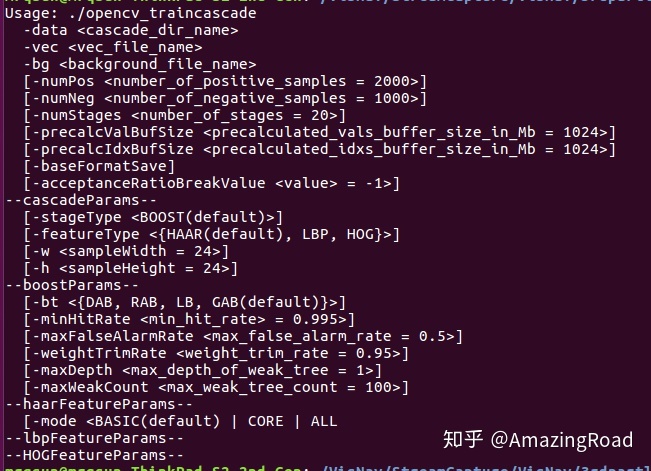
-data:最终生成的参数文件,以及一些中间的文件。
-vec:存放用opencv_createsamples生成的正样本的文件。
-bg:用来存放负样本的文件,一般格式为txt。txt文件的每一行存放了一张图片的绝对路径。
-numPos:正样本的数量,一般小于等于真实正样本的数量。
-numNeg:负样本的数量,一般小于等于真实负样本的数量。
-numStatges:级联分类器的级数。
-stageType:强分类器的类别,目前只支持BOOST。
-featureType:训练分类器使用的特征种类,一般包括HAAR、LBP、HOG,默认使用HAAR特征,人脸检测HAAR特征最好。
-w和-h:样本的宽和高,要跟opencv_createsamples生成文件时的参数值保持一致。
-bt:AdaBoosting的类别,OpenCV包含DAB(Discrete AdaBoost),RAB(Real AdaBoost),LB(LogitBoost)与GAB(Gentle AdaBoost),默认使用GAB。
-minHitRate:设置的训练目标召回率。
-maxFalseAlarmRate:最大虚警率,影响弱分类器的阈值,表示每个弱分类器将负样本误分为正样本的比例,一般默认值为0.5。
-weightTrimRate:0-1之间的阈值,影响参与训练的样本,样本权重更新排序后(从小到大),从前面累计权重小于(1-weightTrimRate)的样本将不参与下一次训练,一般默认值为0.95
-maxDepth:弱分类器的最大深度,默认为1,一般不超过2。
-maxWeakCount:每一个强分类器包含的弱分类器的数量,默认为100。
四、使用分类器进行分类
OpenCV在data目录下,提供了已经训练好的若干分类器,基于提供的分类器,提供了一份demo code,链接为:
AmazingRoad/AdaboostingFaceDetectiongithub.com
写在后面的话:
参考文章:https://blog.csdn.net/mnydxk/article/details/81034302。















 133
133











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









