





标题:
Defense against Adversarial Attacks Using High-Level Representation Guided Denoiser
作者:
Fangzhou Liao∗, Ming Liang∗, Yinpeng Dong, Tianyu Pang, Xiaolin Hu†, Jun Zhu
Department of Computer Science and Technology, Tsinghua Lab of Brain and Intelligence,
Beijing National Research Center for Information Science and Technology, BNRist Lab
Tsinghua University, 100084 China
摘要
传统降噪器(denoiser )存在错误放大效应(error amplifier effect),因此很小的对抗噪声也会导致误分类。因此文章提出HGD(high-level representation guided denoiser),HGD的损失函数定义为原始图像和降噪图像之间的额差异。HGD的优势:
- 目标模型对对抗样本更加鲁棒
- 在小批量图像上进行训练,并对其他图像和未知分类表现良好
- 可以用于保护指导模型之外的模型
Introduction
1.机器学习和其他学习一样,容易受到对抗样本的攻击
2.对抗样本定义:为攻击目标模型而恶意设计的输入,相比原始输入扰动很小却能导致模型误分类
- 对抗样本的可迁移性——容易在现实世界进行攻击(对安全敏感的应用威胁很大,如身份认证和自动驾驶)
3.去噪方法的问题
- 确实能够减少对抗噪声,但没有办法移除所有对抗扰动
- 残留的扰动会被网络不断放大(错误放大效应)
4.本文工作
- 不使用像素级重建损失函数,使用高层输出的损失(原始图像和对抗样本在输出层的损失),提出high-level representation guided denoiser(HGD)
5.与最新算法相比的优势(联合对抗训练ensemble adversarial training):
- 更高准确度(不论防御白盒还是黑盒)
- 少得多的训练数据和训练时间(与ensemble adversarial training相比)
- 可以用于保护指导模型之外的模型
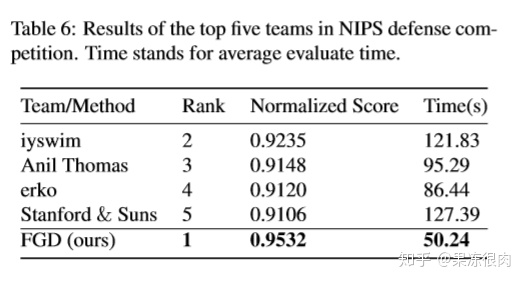
- ***HGD获得第一名,优势巨大,并且推理速度更快
对抗攻击方法
1.L-BFGS:Szegedy et al.[30] : a box-constrained L-BFGS algorithm. 最小化权值的 ε 的和,还有J(x∗,ytarget)
2.Fast Gradient Sign Method (FGSM):Goodfellow et al. [7] : 提出对抗样本可以通过累加高维模型权重的影响来生成,提出 Fast Gradient Sign Method (FGSM)
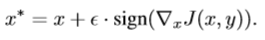
3.FGSM是无目标的(untargeted,降低整体损失而不是使模型预测为特定类别)。Targeted FGSM实现:
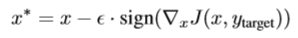
4.iterative FGSM(IFGSM):Kurakinetal.[16] :提出iterative FGSM (IFGSM) ,重复n次FGSM(IFGSMn),IFGSM比FGSM误分类更多
5.***有趣的现象:对抗样本可以迁移到其他模型,同样保持对抗性——因此可以产生现实世界的黑盒对抗样本
对抗防御方法
1.对抗训练(Adversarial training)[7, 16, 31]
- 在训练集中进行对抗噪声的增强。在一些小型数据集甚至能提高准确率(相当于做了样本扩充)
- 缺点:耗时(产生和训练对抗样本需要更多时间),因此对更复杂的攻击没有抵抗(在ImageNet数据集上的对抗训练只用到了FGSM)
2.基于预处理(Preprocessing based)
- 通过对输入图像的特定变换来移除对抗噪声(处理之后的图像输入才被输入网络)
- Gu and Rigazio[9]:denoising auto-encoders
- Osadchy et al. [20] :用一系列过滤器(filter)来移除对抗噪声( median filter, averaging filter and Gaussian low-pass filter)
- Graese et al. [8] :评估了一下预处理转换的防御性能
- Das et al. [4] :用JPEG有损压缩来降低对抗样本的影响
- Meng and Chen[18] :两个步骤,检测对抗样本->根据干净样本和对抗样本之间的差异进行重组(?)
- ***这些方法通常适用于小型图片,一些算法放在大图片上就没什么用了
3.梯度遮挡( gradient masking effect [22, 23, 31]):
- 使用正则化器或平滑标签,使模型对输入的扰动不那么敏感
- Gu and Rigazio [9] :deep contrastive network. 使用逐层对比惩罚项实现对输入扰动的输出不变性
- Papernot et al. [24] :使用知识蒸馏(knowledge distillation )来防御。知识蒸馏:训练一个老师模型(复杂的),再让学生模型(简单的)来学习老师模型的输出。老师模型的输出是软标签( soft labels )。
- Nayebi and Surya [19] :使用饱和网络(saturating networks)
- ***这些方法的缺陷:无法解决对抗攻击的问题,只让攻击更难了而已,现在同样会被黑盒攻击。
Pixel guided denoiser(PGD)
1.Pixel guided denoiser(PGD) :
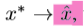
基于像素点的去噪器,将对抗样本转换为去噪样本。通过计算去噪样本和原始图像的 L1范数 来确定损失函数(基于像素点的距离)
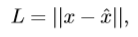
2.Denoising U-net
- Denoising autoencoder (DAE)[32] 。DAE是以多层感知机的形式来防御对抗目标模型的对抗攻击,但只是用在简单的MNIST数据集上。文章使用多层卷及网络的形式将DAE用在ImageNet上
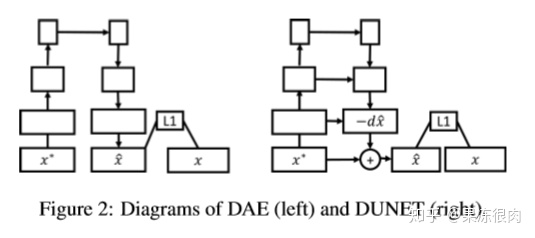
***DAE具有瓶颈结构,可能会限制高分辨率图像中细节信息的传递
- denoising U-net (DUNET)(为了避免DAE的细节丢失)
建立横向连接
目标是学习对抗噪声,不需要重建整个图像,从损坏图像中减去噪声就可以得到原始图像
3.DUNET的网络结构
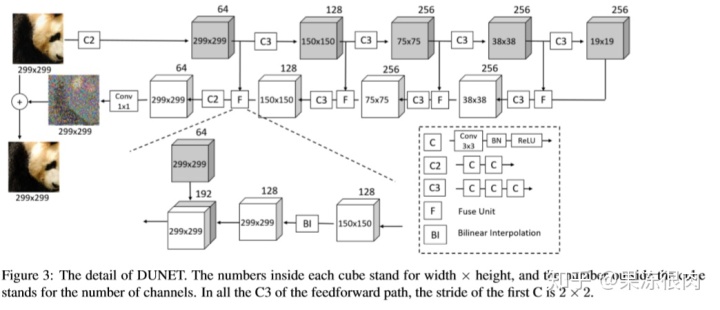
- 一些解释:
- 每个C代表一层卷积
- Ck表示有多少个连续的卷积层(C)
- 每层C包括:
- 3*3卷积
- 批处理归一化层(batch normalization layer )
- 线性修正单元(Relu函数)
- 网络组成
- 5层前馈,每一个C3设置stride为2*2,其他设置stride为1*1
- 4层反馈
- 1个 1*1 卷积
- 反馈层首先对上层输入进行上采样(使用双线性差值),然后和同一层前馈的输出结合起来
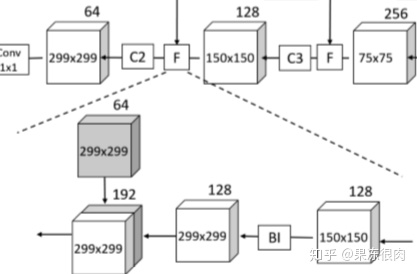
- 最后整个网络得到的输出为
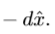
- 修复的图像为:
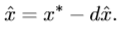
【本文最终的方法】High-level representation guided denoiser (HGD)
1.PGD存在对抗噪声增强(即上面说的错误放大效应)的问题:
-
- 虽然去除对抗噪声效果很好,但残留的噪声影响会随网络层数增加而变大,导致误分类
2.本文替换PGD的损失函数
-
- 图像像素级损失->目标模型输出层的损失
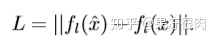
代表,修正后的
- 损失函数替换了之后,就ok了,从PGD变成HGD,(剩下所有的网络结构都跟前面介绍的DUNET一样……….)
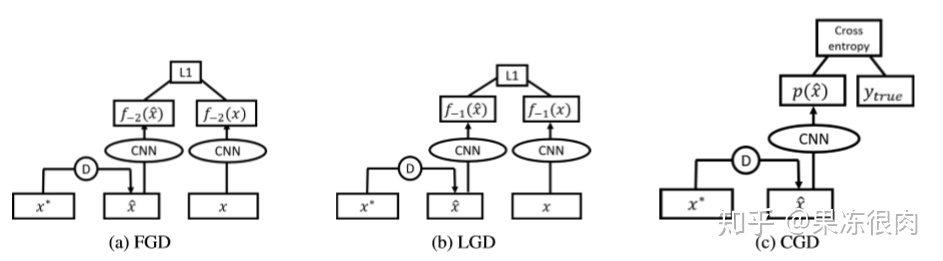
3.HGD的两个实现(取不同的
-
- FGD,是对比倒数第二层的卷积特征图的差异
- LGD:是对比最后一层,softmax之前的输出结果
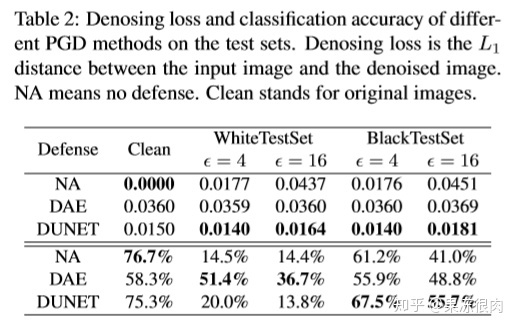
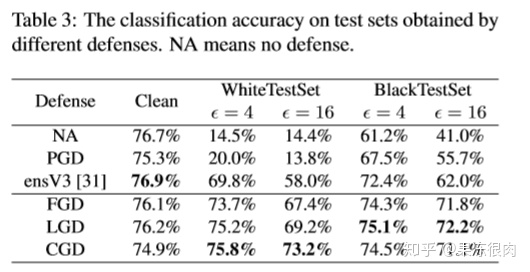
实验
- 实验设置(略)
- 数据集
- 参数
- 实验结果
比赛排名















 2108
2108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









