







 这篇博客介绍了Feature Denoising for Improving Adversarial Robustness的研究,主要探讨了如何使用去噪U-net和高级表示引导降噪技术来增强深度神经网络对对抗性攻击的抵抗力。研究者针对ImageNet数据集,通过改进的U-net结构和高层表示指导的去噪策略,减少对抗噪声的影响,提高模型的稳定性。
这篇博客介绍了Feature Denoising for Improving Adversarial Robustness的研究,主要探讨了如何使用去噪U-net和高级表示引导降噪技术来增强深度神经网络对对抗性攻击的抵抗力。研究者针对ImageNet数据集,通过改进的U-net结构和高层表示指导的去噪策略,减少对抗噪声的影响,提高模型的稳定性。
阅读由来
Feature Denoising for Improving Adversarial Robustness的参考文献
【论文阅读】Feature Denoising for Improving Adversarial Robustness_dujuancao11的博客-CSDN博客
目录
3. 方法
3.1. 像素引导降噪
3.1.1 去噪U-net
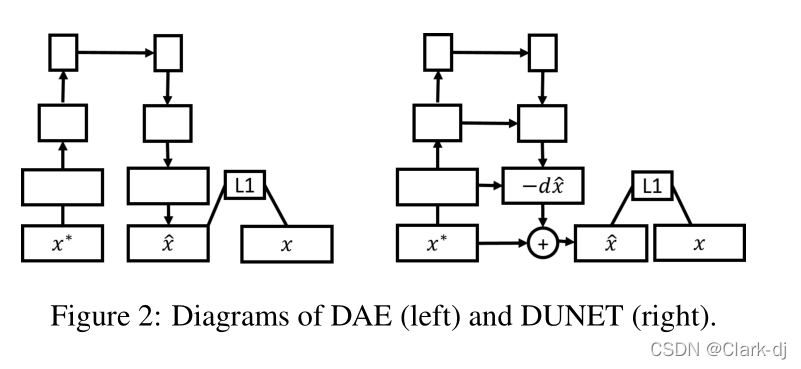
去噪自动编码器(DAE)[32]是一种常用的去噪模型。在之前的工作[9]中,DAE以多层感知器的形式被用来保护目标模型免受对抗攻击。然而,实验是在相对简单的MNIST[17]数据集上进行的。为了更好地表示ImageNet数据集中的高分辨率图像,我们在实验中使用了卷积版的DAE(见图2)。
DAE在编码器和解码器之间存在瓶颈结构。这一瓶颈可能会限制重建高分辨率图像所必需的精细尺度信息的传输。为了克服这个问题,我们用U-net[27]结构修改DAE,提出去噪U-net (DUNET,见右图2)。
DUNET与DAE有两个不同之处。
- 首先,与阶梯网络[25]类似,DUNET以相同的规模将编码器层的横向连接添加到相应的解码器层。
- 其次,DUNET的学习目标是对抗噪声(dˆx图2),而不是像DAE那样重建整个图像。
- 残差学习[34]是通过从输入到输出的捷径来实现的,并将它们相加。干净的图像可以很容易地通过从损坏的输入中减去噪声(添加-dˆx)获得。
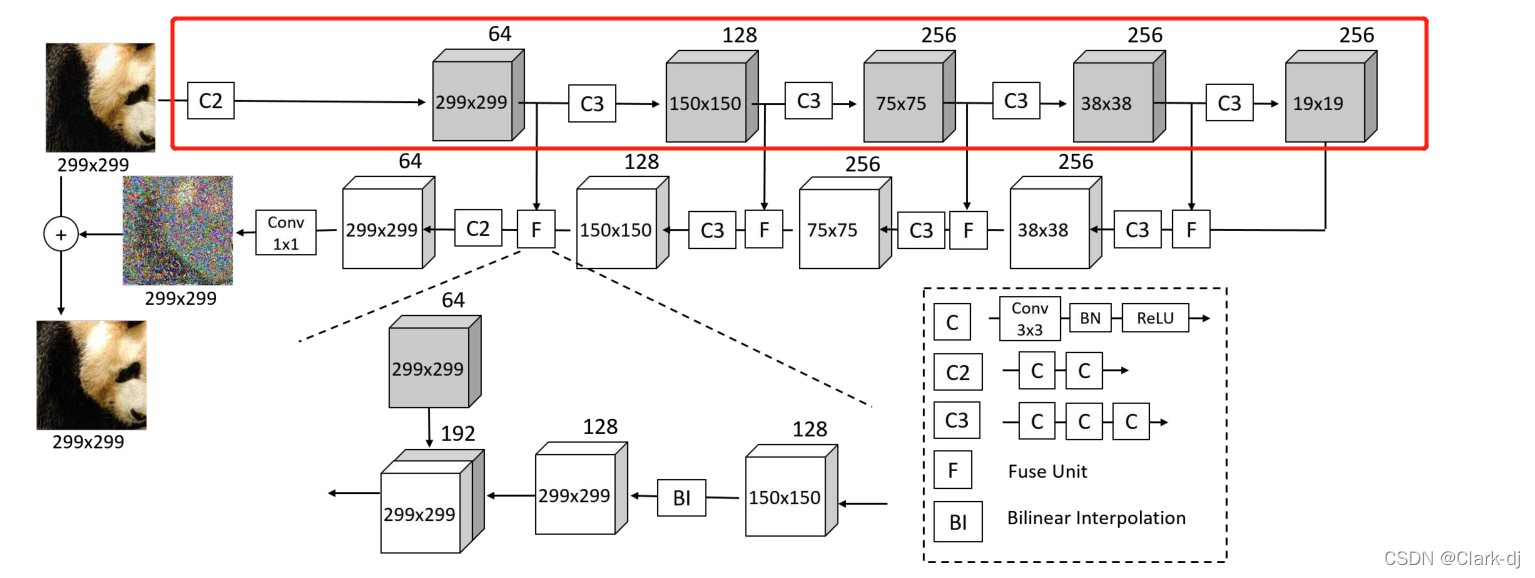
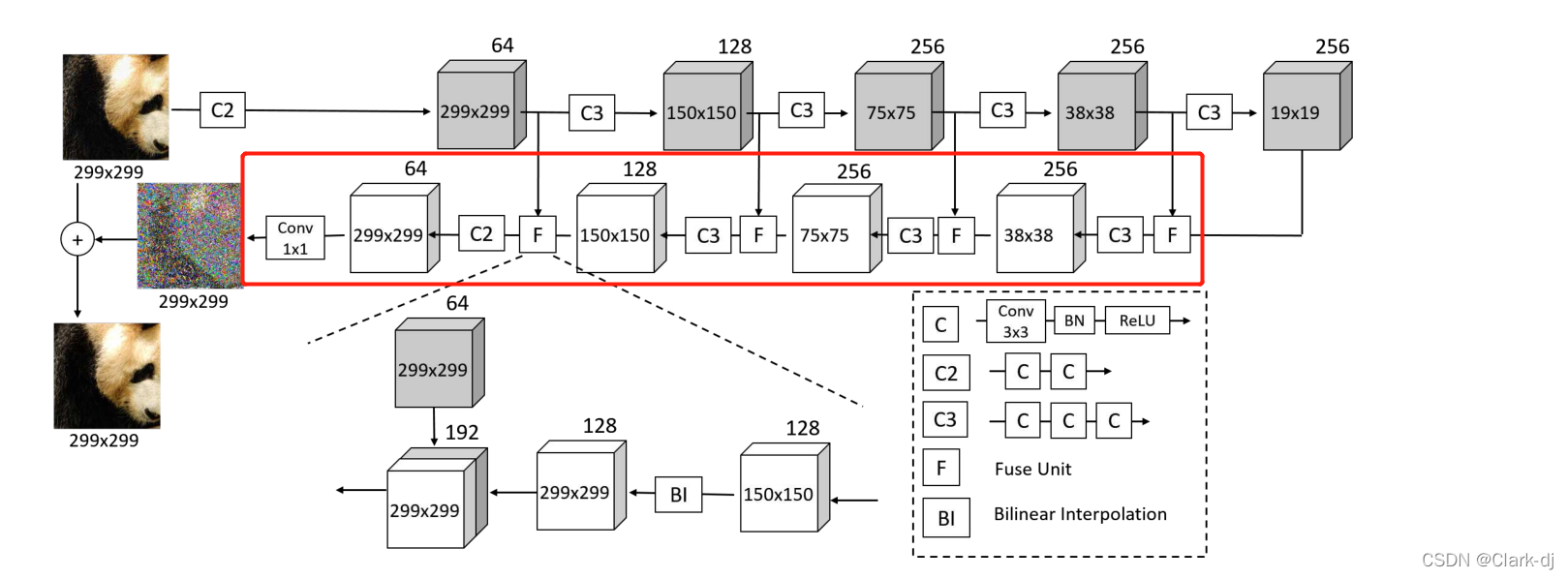
3.1.2 网络体系结构
我们以DUNET为例来说明体系结构(图3)。只需从DUNET中移除横向连接,就可以简单地获得DAE。C定义为层序列的堆栈,每个序列包含一个3×3 convolution、批量归一化层[13]和纠偏线性单元(rectified linear unit)。
(这句咋翻译)该网络由一个前馈路径和一个反馈路径组成。
图3:DUNET的细节。每个立方体内的数字表示width×height,立方体外的数字表示通道数。在前馈路径的所有C3中,第一个C的跨步2×2
- 前馈路径由5个块组成,分别对应1个C2和4个C3。每个C3有2×2步长的第一个卷积,而其他所有层的步长是1×1。前馈路径接收图像作为输入,生成一组分辨率越来越低的特征图(见图3的顶部路径)。
- 反馈路径由四个模块和一个1×1卷积组成。每个块接收来自反馈路径的反馈输入和来自前馈路径的横向输入。
1. 它首先使用双线性插值将反馈输入采样到与横向输入相同的大小,
2. 然后用Ck处理连接的反馈和横向输入。
从上到下,使用三个C3和一个C2。
在反馈路径上,特征图的分辨率越来越高。
最后一个块通过1x1卷积的输出转换为负噪声−dˆx(见图3的底部路径),最终的输出为负噪声与输入图像的和:

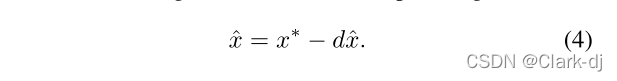
3.2. 高级表示引导降噪
PGD的一个潜在问题是对抗噪声的放大效应。对抗性的例子与清晰的图像差别很小。然而,这种微小的扰动会逐渐被深度神经网络放大,并产生错误的预测。即使去噪器可以显著抑制像素级的噪声,剩余的噪声仍然可能扭曲目标模型的高层响应。详见5.1节。
为了克服这个问题,我们用目标模型输出的重建损失代替像素级的损失函数。具体来说,给定一个目标神经网络,我们提取它在被xandˆx激活的第l层的表示,并将损失函数定义为它们的差异的L1范数:
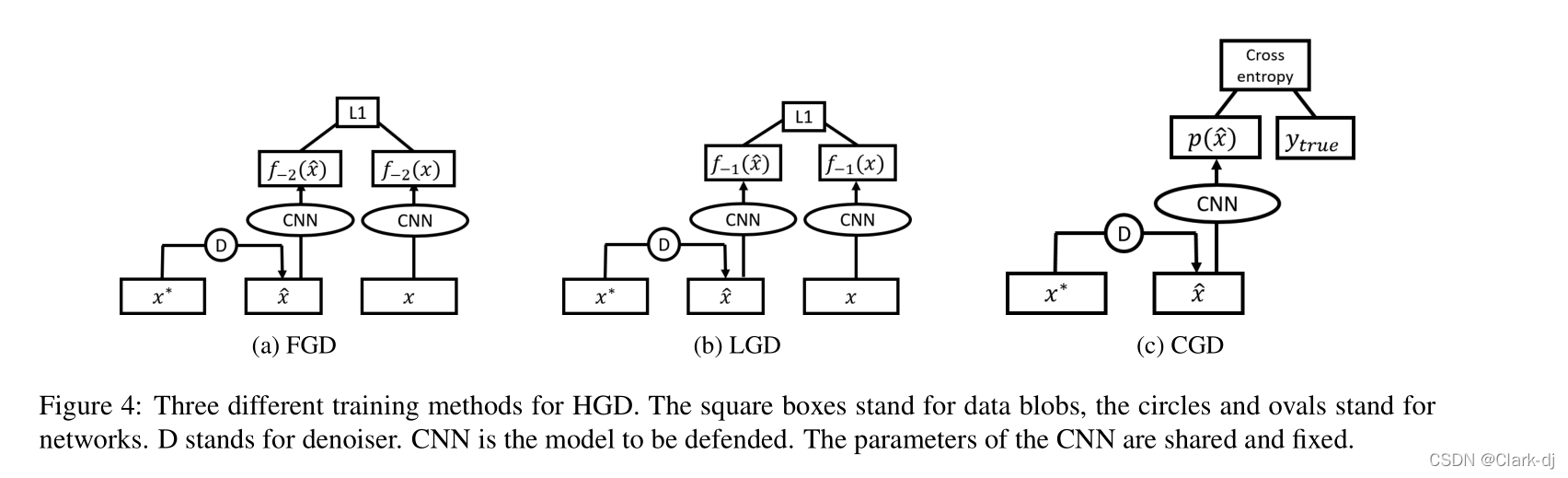
对应的模型称为HGD,其监督信号来自于目标模型的某些高层,携带着与图像分类相关的指导信息。HGD使用与DUNET相同的u -网结构。它们只是在损失函数上有所不同。
图4:三种不同的HGD训练方法。
方框代表数据块,圆形和椭圆形代表网络。D代表降噪。CNN是值得辩护的典范。CNN的参数是共享和固定的。
我们提出了两种不同选择的HGDs。
- 对于第一个HGD,我们定义 l=−2为最顶层卷积层的索引。这一层的激活经过全局平均池化后馈送给线性分类层,因此它比低卷积层更能实现分类目标。这种去噪器称为特征引导去噪器(FGD)(参见图4a)。FGD使用的损失函数也称为感知损失或特征匹配损失[26,14,6]。
- 对于第二个HGD,我们定义 l=−1为最终softmax函数之前的层的指数,即logits。这种降噪器称为对数引导降噪器(LGD)。在本例中,损失函数是ˆx和x激活的两个logit之间的差值(参见图4b)。
我们考虑FGD和LGD的原因如下。卷积特征映射提供更丰富的监督信息,而logits直接代表分类结果。
所有PGD和这些HGDs都是无监督模型,因为在他们的训练过程中不需要ground truth标签。另一种方法是使用目标模型的分类损失作为去噪损失函数,这是需要地面真实标签的监督学习。这个模型称为类标签引导去噪(CGD)(见图4c)。
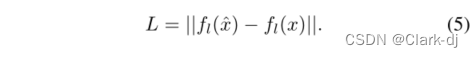



















 1660
1660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











