







分享人工智能技术干货,专注深度学习与计算机视觉领域!

你还在用mtcnn来进行人脸检测吗?其实,笔者就有发现自己的同事还在习惯性使用mtcnn用于人脸检测数据处理,诚然,mtcnn出现的当年,以其模型小、时延短、精度高以及多任务可同时实现人脸框和人脸关键点预测,受到了热捧,那时的人脸算法相关任务大多都用到了mtcnn来完成人脸检测,以至于现在还有不少人还在继续使用,可见mtcnn影响足够深远!
但是,你知道吗?前几个月,来自人工智能头部企业深兰科技(DeepBlue)开源了一个各方面性能更优的人脸检测算法DBFace,正如本文开头图像所示,该算法的性能非常优秀,可以在世界最大的自拍照里检测到最多的人脸,密密麻麻的检测框,看着是不是有密集恐惧症了!
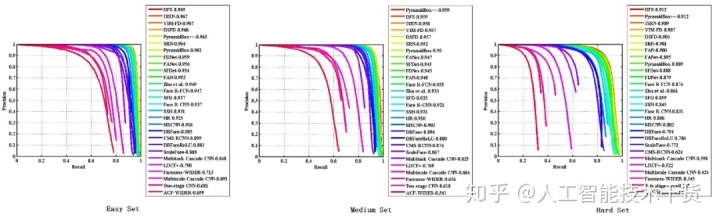
DBFace的主要特点是模型小、检测实时、精度高且是单阶基于anchor free思想设计的多任务人脸检测器,不仅可以预测人脸框还可以预测5个人脸关键点,其主要关注单尺度原图输入,不对输入多尺度变换等操作进行mAP结果比较,因为DBFace更加考虑的是落地使用,不是为了刷分而存在,足见其就是奔着工业实际应用而诞生的。那么,DBFace在WiderFace这个常用的最大人脸检测测试数据集上的表现如何呢?官方给出的结果显示,其在WiderFace的easy、medium、hard等级别上分别取得了0.925、0.920、0.847的准确率,不仅打败了mtcnn还打败了诸如RetinaFace等著名的人脸检测算法,如下是官方给出的一张PR曲线PK图,PR曲线越靠近右上角表明其性能更优。
这样一个优秀的人脸检测器,值得我们去研究其源码实现,因此,笔者决定基于DBFace开源代码对其进行分析,并推出一系列相关分析文章。

本篇文章,我们就先从DBFace的输入数据处理部分入手,对于我们理解如何基于DBFace框架构造训练数据非常有帮助,这也是所有模型框架绕不开的步骤!
打开DBFace源码项目,在主目录下的train文件夹有放了DBFace两个small模型的训练源码,一个模型有ext部分即检测的head模块是否有CBA(Conv+BN+Activation)模型大小约1.7M,另一个模型则没有ext部分模型大小约1.3M,对于输入数据的处理两个是一样的,因此,我们只研究其中的一个源码就好,我们以没有ext部分小模型的输入数据处理进行分析。
DBFace的输入数据主要由LDataset这个继承自pytorch原生Dataset的类来进行处理,我们需要向LDataset类指明相应的labelfile标签文件和imagesdir图像放置目录,而这两个参数又是由封装的App应用类进行传递的。那么,labelfile标签文件的结构是怎么样的呢?其实,大部分的数据处理部分都是在common.py文件内实现的,我们从common.load_webface使用到这两个参数的接口进行分析入手,大概的流程处理如下所示!

1. load_webface主要是组装训练图像路径和对应的人脸框人脸关键点处理对象到files列表内,供LDataset进一步处理,那么分析其源码,我们可以得出DBFace的标签文件组织结构应该是如下面所示的,这样我们就可以很容易切入再训练了!
# xxxx.jpg
bbx bby bbw bbh lmx1 lmy1 lmt1 lmx2 lmy2 lmt2 lmx3 lmy3 lmt3 lmx4 lmy4 lmt4 lmx5 lmy5 lmt5
bbx bby bbw bbh lmx1 lmy1 lmt1 lmx2 lmy2 lmt2 lmx3 lmy3 lmt3 lmx4 lmy4 lmt4 lmx5 lmy5 lmt5
# yyyy.jpg
bbx bby bbw bbh lmx1 lmy1 lmt1 lmx2 lmy2 lmt2 lmx3 lmy3 lmt3 lmx4 lmy4 lmt4 lmx5 lmy5 lmt5
bbx bby bbw bbh lmx1 lmy1 lmt1 lmx2 lmy2 lmt2 lmx3 lmy3 lmt3 lmx4 lmy4 lmt4 lmx5 lmy5 lmt5
bbx bby bbw bbh lmx1 lmy1 lmt1 lmx2 lmy2 lmt2 lmx3 lmy3 lmt3 lmx4 lmy4 lmt4 lmx5 lmy5 lmt5其中,以“#”开头的是图片相对路径名,其与imagesdir组合即为该图片的绝对路径,人脸框的形式是“x y w h”,每个人脸关键点的形式则为“x y t”,t代表这个人脸关键点是否有效,当任意一个关键点的t等于-1时人脸框内所有关键点将被过滤掉,源码设定总共有5个人脸关键点。
2. parse_facials_webface则是依据标签文件的组织结构去解析对应的人脸框和人脸关键点的,它会检查人脸框像素面积是否小于4x4个像素,如果小于4x4个像素那么该人脸框和其人脸关键点都会被直接过滤掉,另外,由于人脸关键点标签有t的存在,当任何一个关键点的t为-1时都会将人脸框内对应的关键点全部过滤掉,而相应的人脸框却被保留继续参与训练的。最终该接口返回的是一个ts列表,其内元素是一个个实例化了的BBox对象。
3. BBox是一个处理人脸框和人脸关键点的类,它提供了获取人脸框宽、高、面积、中心点和人脸关键点坐标及其它各类坐标值等的API接口能力,我们会发现该类会在后续的数据处理中经常被引用,数据处理很大一部分都是通过内存共享的方式进行的。

LDataset类获取到相应的图像路径和BBox对象后,在__getitem__实现内主要做了两件事,一件事预处理图像,另外一件事预处理各预测输出的ground truth。
前者主要通过augment.webface接口对图像进行各种各样的数据增强操作,其中包含随机的颜色扰动(亮度、对比度、饱和度及光照)、随机翻转、随机缩放裁剪及随机旋转(正负45度范围内)等,值得注意的是,在数据增强过程中,如果有动到了与坐标相关的操作比如随机翻转均会对坐标进行相应的处理,最终,图像被缩放到800x800的分辨率大小。在这之后,图像被除以255归一化,然后减去均值[0.408, 0.447, 0.47]再除以方差[0.289, 0.274, 0.278]完成各通道像素的归一化处理。

后者主要是处理制作各预测输出的ground truth,包括高斯热力图、人脸框、人脸关键点的ground truth换算及其对应的权重因子设定等,源码比较复杂,但主要是要换算得到如下的数组,为后续的各损失计算进行准备。

对于高斯热力图,可以理解为其为一个椭圆形,且其中心点值为1,其余则依据与中心点的距离和特定公式渐渐衰减成大小不同的值,这部分主要涉及到heatmap_gt、heatmap_posweight、keep_mask这三个数组。heatmap_gt由common.truncate_radius和common.draw_truncate_gaussian这两个接口进行生成,前者依据人脸框的宽高在输出特征图上对应再缩小4倍分别得到w_radius和h_radius,之后再由后者进行高斯值计算。heatmap_posweight主要是为了解决anchor free对大目标检测不够鲁棒的问题,它的存在是要增加大目标在损失里的权重占比,其由common.draw_gaussian进行权重分配计算。keep_mask主要是为了过滤掉小于12x12大小的人脸框被错误用于负例样本的问题,作者认为小于12x12不应该被当做负例样本对loss产生贡献,而应该被直接过滤掉,这样既能够保证大目标检测性能的同时提升小目标的检测精度。因此,我们在源码里可以看到当人脸像素低于12x12时,其对应keep_mask坐标是被直接置0的,即不参与损失贡献,且对应的人脸关键点也不会参与计算损失值,但如果人脸像素面积同时高于4x4时其对应的人脸框却会参与损失计算。

对于人脸框,主要涉及reg_tlrb、reg_mask及distance_map这三个数组。reg_tlrb就是人脸框换算后的坐标值,分别存放了左上右下的坐标值,当人脸框像素面积介于4x4和12x12时即对于小目标(以下说的小目标都是指人脸框像素面积介于4x4和12x12时的人脸),reg_tlrb总是参与损失贡献,但对于大目标,如果在数据增强中有对图像做了大于正负30度的旋转操作,那么reg_tlrb会被直接过滤掉,这么做的考量,作者的原话是“为啥会忽略旋转增强,是因为旋转后的图像,人脸的框是不能使用旋转前的结果的,等同于没有gt,那么怎么去训练呢?当然我们也考虑过使用旋转后计算的大概框,然而效果是不好的”。除此以外,当在数据增强中未有对图像做了大于正负30度的旋转操作时,且如果某个像素坐标坐落在其对应高斯热力图范围内,且其与目标中心点的距离缩放到(1 - my_gaussian_value)后依然大于distance_map里的1000元素值,那么对应的reg_tlrb也会被过滤掉,但这种情况应该不多见,其实distance_map的作用就是用于辅助判断这种情况的,并没有看到有作他用。至于reg_mask,其实它就是标记目标中心处为1其余为0,以备在计算损失值时该处bbox参与贡献。


对于人脸关键点,主要涉及landmark_gt和landmark_mask这两个数组。landmark_gt的计算比较特别,它是将每一个值减去对应的目标中心坐标,之后经过common.log特别设计的log函数进行求取再除以4得出,这么做的目的是当landmark不依赖人脸框(上述有说过人脸框可能被过滤)仅仅依赖人脸中心的时候,需要对landmark值进行压缩设计。而landmark_mask仅仅标记了目标中心坐标值为1,用于告知损失计算时该处landmark应参与损失贡献。

值得注意的是,由于网络结构对输入原图下采样4倍,因此每一个对应原图的坐标值都应该要除以stride=4,源码中多处有做了这个操作,对于输入为800x800那么经过下采样可得200x200(fm_height x fm_width)的输出特征图。
以上即为DBFace人脸检测算法的详细源码分析之输入数据处理部分,仅供参考!
推荐阅读:
OpenCV实战系列(三):基于OpenCV的视频流处理方法mp.weixin.qq.com




粉丝福利:
CelebA-Spoof含有丰富标注信息的大型人脸反欺诈数据集mp.weixin.qq.com















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









