










数据预览
1.读取
读取的一般为csv文件
import pandas as pd
data=pd.read_csv(r'F:\paper\dataset\csv\archive.csv')
data.head()
最近迷上了使用剪切板

import pandas as pd
#首先选中所需数据 >> 右击复制
data = pd.read_clipboard()
data.head()
2.数据格式
查看各变量数据类型
data.dtypes
3.描述性统计
data.describe()

4.统计每个元素出现的次数
pd.value_counts(df_10.x28_1)
5.缺失值情况
查看每列缺失值个数
(data.isnull()).sum()
显示缺失值所在位置
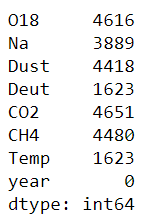
data[data.isnull().values==True]
可视化方式查看缺失值情况
import missingno as msno
%matplotlib inline
#way1
msno.matrix(data1, labels=True)
#way2
col_missing =data.isnull().any()[data.isnull().any()].index
msno.matrix(df=data[col_missing])

数据清洗
缺失值处理
备注:如果想删除一些无关紧要的列的话
data=data.drop(columns=["year"])
1.删除全为空值的行 / 列
data=data.dropna(axis=0,how='all') #行
data=data.dropna(axis=1,how='all') #列
2.删除含有空值的行 / 列
quantile=data.dropna(axis=0, how='any') #行
quantile=data.dropna(axis=1, how='any') #列
3.上下数据进行填充
#使用前一个数据进行填充
data0['Wretwd'] = data0['Wretwd'].fillna(method='pad')
#使用后一个数据进行填充
data0['Wretwd'] = data0['Wretwd'].fillna(method='bfill')
4.用插值法填充
data['灰度分'] = data['灰度分'].interpolate()
5.用KNN进行填充
from fancyimpute import BiScaler, KNN, NuclearNormMinimization, SoftImpute
dataset = KNN(k=3).complete(dataset)
6.各种值填充
#固定值
data['灰度分'] = data['灰度分'].fillna('-99')
#均值
data['灰度分'] = data['灰度分'].fillna(data['灰度分'].mean()))
#众数
data['灰度分'] = data['灰度分'].fillna(data['灰度分'].mode()))
特定值处理
#删除含有某值的某列
data=data[~data['任务状态'].isin(['已关闭'])]
#选取含有某值的某列
data[data['任务状态'].isin(['已完成'])]
索引
1.重置索引
data.reset_index(drop=True)
2.设置某一列为索引
data.set_index('year')
查找重复值
在subset后面填写所需查重的列名,即可得知重复项所在行
for i,j in enumerate(ch4.duplicated(subset = ["Gas age"])):
if j==1:
print(i)
数据透视表
根据 ‘year’ 列计算分组平均值
year_mean=pd.DataFrame(data.groupby('year').mean())
时间格式
data['Date'] = pd.to_datetime(data['Date'])














 467
467











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









