






awk提供了极其强大的功能:可以进行正则表达式的匹配、样式装入、流控制、数字运算符、进程控制语句甚至于内置的变量和函数。
简单地说,awk就是一种用于处理文本的编辑语言工具,它扫描文件中的每一行,查找与命令行中所给定内容相匹配的模式,如果发现匹配内容,则进行下一个编程步骤。如果找不到匹配内容,则继续处理下一行。
@ubuntu:~$awk ' 条件1 {动作1} 条件2 {动作2} ...' file示例如下:
@ubuntu:~$awk ' i==1 {print $0 } i==2 {print $1} ' file以上命令的执行逻辑是:awk从file中读取数据,每次读取一行,读到一行数据之后判断每一个条件是否成立,如果成立则执行花括号里面的动作,如i==1成立则执行print $0,再判断i==5是否成立来决定是否执行print$1。然后读取下一行,以此类推。如果一个动作前面没有条件,则这个动作就可以“无条件”执行。

◆

为了更好理解,建一个简单的文档file来执行一遍:
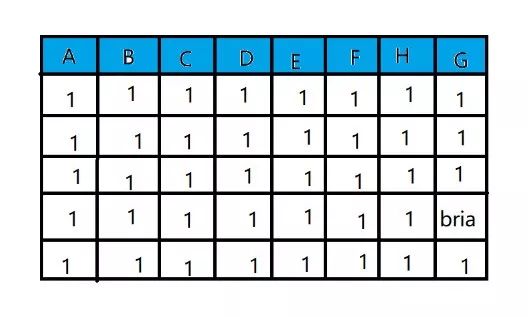
(1)打印指定列
@ubuntu:~$awk ' { print $1, $2} ' file注意,其中单引号中大括号内就是awk语句,只能被单引号包含。$1表示第一列,$2表示第二列,$n表示第n列。而$0表示整一行(即一行中的所有列)
(2)格式化输出(和C语言差不多)
@ubuntu:~$awk ' { printf " %-10s:%-d\n", $1, $2 } ' file(3)过滤(条件选择)
@ubuntu:~$awk ' { $3==8 && $4 ==9 } { print $0 } 'file其含义是读取file中的一行信息,判断第3列是否等于8而且第4列是否等于9,如果是,则打印该一行,然后再读取下一行。
(4)打印表头,引入内建变量a
@ubuntu:~$awk ' { a==1 || $3==8 } {print } 'file注意:
1、a是一个所谓的内建变量,表示已经读出的记录数(即行号);
2、print后面什么都没有,默认表示print $0。
(5)指定分隔符
@ubuntu:~$awk ' BEGIN { FS=":" } {print $1}' /etc/passwd注意:BEGIN意味着紧跟在它后面的动作{FS=":"}会在awk读取第一行之前处理。
上面的语句等价于
@ubuntu:~$awk -F:'{ print $1 }' /etc/passwd如果有多个分隔符,则可以写成
@ubuntu:~$awk -F ' [\t; : ]' ' {print $1}' /etc/paswd其中,-F '[\t;:]'的意思是指定制表符、分号以及冒号为分隔符
(6)使用正则表达式匹配字符串
@ubuntu:~$awk ' $0~/bria/ {print} ' file其含义是将所有匹配bria的行打印出来。其中,$0~/bria/是一个条件,表示所指定的域(这里是$0)要匹配的规则(这里是bria),简单说,file中有一行只要含有单词ria,就会被选出来然后打印,同时要注意,这里的单词bria被写在两个“/”之间,事实上这两个“/”之间写的就是“正则表达式”。正则表达式就是一些约定的规则,用这些规则来匹配字符串,从而达到过滤文本信息的目的,也就是使用各种字符和符号,来选出我们想要的信息。
(7)使用模式取反的例子
@ubuntu:~$awk ' $0~/bria.*/ {print} ' file含义:将所有不匹配bria的行打印出来。
(8)将A项(A列)的信息分别存放在各个文件中
@ubuntu:~$awk ' {print > $1 } ' file@ubuntu:~$awk ' {print $2, $6 > $1 } ' file@ubuntu:~$awk ' NR!= {a[$4]++} '> END{for(i in a) print i "," a[i];}' file@ubuntu:~$awk '{ sum+=$1} END{print sum}' file














 1996
1996











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









