






写在前面
最近实验室的项目需要使用GPU做加速,因此入门了CUDA(Compute Unified Device Architecture)。为整理知识、完成知识的输出和巩固,开个新坑记录CUDA程序设计的心得。文章内容主要围绕本人磕盐搬砖时面临的实际问题展开,大部分篇幅参考自Shane Cook编写的《CUDA Programming - A Developer's Guide to Parallel Computing with GPUs》。阅读本系列文章需要具备计算机组成原理和并行计算的基础知识。
第一次在知乎写文章,还不太习惯使用知乎编辑器,有非主观错误的地方还请各位看官们指正,如遇杠精则顺手举报。
除本篇以外,后续的坑不定期更新,还将包括以下内容:
- 核函数
- 实现简单的应用:向量加
- 多GPU并行
- CPU+GPU异构并行
- 模板计算:雅各比迭代
- 基本性能优化方法
本系列实验用CUDA版本为10.1,编程语言为C/C++,实验用参考代码托管在我的GitHub:
BenQuickDeNN/CUDA_tutorialgithub.com
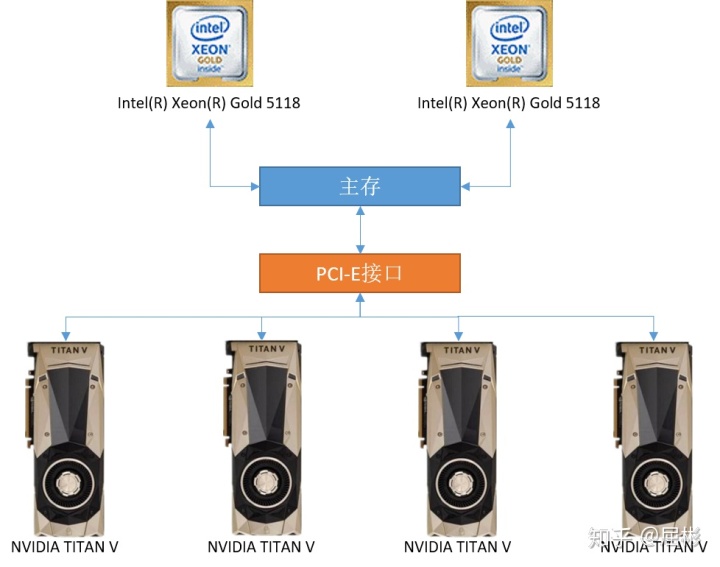
本系列实验用GPU计算节点操作系统为Red Hat Enterprise Linux Server release 7.4,包含2个CPU和4个GPU,通信拓扑如下:
正文
作为一名程序员(计算机操作员),编程的目的就是操作硬件,不要跟我抬杠说“老师说过程序就是数据结构+算法”。如果我们想使用好CUDA,那么需要先了解GPU的硬件架构。我们主要关心SM(Stream Multiprocessor)和SP(Stream Processor)的组成,它们关系到任务分解方案的设计。SM和SP的相关知识繁多,想全面了解GPU硬件架构的同学可参考英伟达最新的Volta架构。
GPU计算卡包含大量的SM,每个SM又包含大量SP。
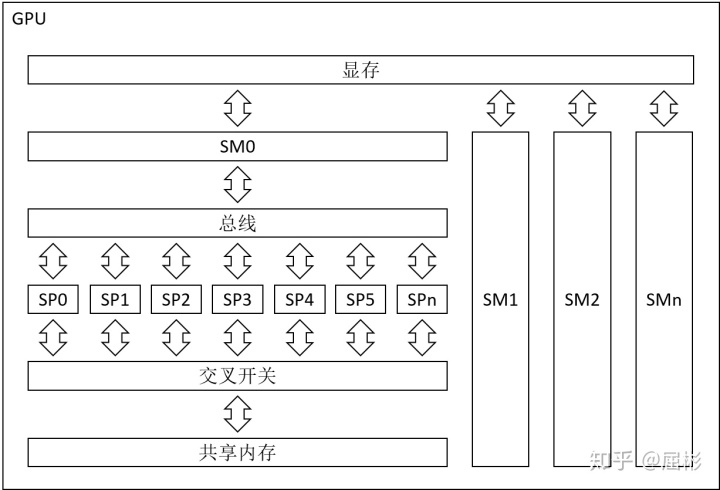
SM是GPU的基本控制指令执行单元,它拥有独立的指令调度电路。一个SM下所有的SP共享同一组控制指令。因此每个独立的计算任务至少要用一个SM执行,如果计算任务的规模无法让SM及其下所有的SP“吃饱”,就会浪费该SM下部分SP的算力。此外,每个SM还拥有一套独立的共享内存。
SP是GPU的基本算术指令执行单元,它没有指令调度电路,但拥有独立的算术电路,包括1个ALU(Arithmetic logic unit)和1个FPU(Float Point Unit)。每个SP负责处理固定数量的线程,注意这里的“线程”与CPU上的线程不同,它们共享同一组算术指令,处理不同的数据,这种并行方式又叫作SIMD(Single Instruction Multiple Data)。SP内部没有任何除寄存器和缓冲队列外的独立存储系统。
我们不妨做一些实验来调查GPU中SM和SP的相关信息,通过编译和运行下列代码来显示实验节点0号GPU的相关信息。
/*********************************************************************
控制台输出信息如下:
----------------GPU----------------
GPU name: TITAN V
number of SMs: 80
warp size: 32
max number of thread per SM: 2048
number of warp per SM: 64从控制台输出的信息中,我们得知GPU的名称为“TITAN V”,SM的个数为80,每个SM中可使用的最大线程数为2048。
注意这里出现了一个新词“warp”,warp是CUDA中的逻辑概念,翻译为“线程束”。每个warp对应一个SP,“warp size”等于SP中可使用的线程个数。那么根据控制台输出信息,TITAN V的每个SP中可使用的线程个数为32,每个SM包含64个SP。
另外,在一般的设计中,SM内部的共享内存和GPU显存是分层次的,这是为了利用数据的局部性原理。按存储层次可分为寄存器文件、cache、DRAM等,它们的容量递增,但读写速度递减。由于GPU的存储系统普遍分层,充分利用数据的局部性是后续优化工作中的一种重要思路。
下期预告:
核函数















 1927
1927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









