





原创文章,转载请注明出处
作者:汪岩
1. GPGPU编程简介
GPU最初的设计目的是做图形渲染,使得计算屏幕的图形显示速度更快,渲染效果更好。好的图形渲染效果通常是通过像素点并行渲染实现,要求内核有高吞吐率。因此,GPU内部有大量可执行并行计算的内核,这赋予了GPU巨大的算力提升潜力,使其经过架构设计改进,可用于气象、洋流、高分子等要求高峰值算力的科学计算,以及随后兴起的人工智能、区块链等并行的计算密集型程序,从而形成GPGPU(General-purpose computing on GPU)的概念。计算密集型程序的大部分计算涉及的操作数保存在寄存器中。因为寄存器靠近处理器,存取数据和计算速度都非常块,可以达到很高的吞吐率。而且GPGPU采用SIMD(Single Instruction Multiple Data)架构,内部有数百到数千内核。区块链、卷积神经网络这类计算可分解为若干互相独立的简单任务,这种特性很符合GPGPU的应用场景。
初期的GPU不能通过软件编程,图形数据只能按照固定的通路执行,因此也被称为固定管线。随后出现了针对GPU的汇编语言和高级编程语言,通常被称为着色语言(Shading Language)。传统GPU的图形计算编程模型主要有Direct3D 和OpenGL。程序员可借助这些编程模型API完成非图形类并行计算任务。GPGPU的并行计算架构主要有 NVIDIA的CUDA(Compute Unified Device Architecture,又称统一计算架构)和苹果等业界众多著名厂商共同支持的OpenCL。本文结合CUDA和OpenCL的程序流程,介绍GPGPU的软硬件接口和协同设计。
2. CUDA和OpenCL程序流程
OpenCL主机端(host)和设备端(device)代码保存在不同文件中,OpenCL 主机端程序流程总结如下:
a. 获取OpenCL平台及其ID:clGetPlatformIDs(…);
b. 建立OpenCL context:clCreateContextFromType(…);
c. 获得设备列表:clGetContextInfo(…) ;
d. 获得设备名称:clGetDeviceInfo(…);
e. 建立 Command Queue: clCreateCommandQueue(…);
f. 初始化测试数据;
g. 设置OpenCL设备内存,并将主机内存数据拷贝到设备内存:clCreateBuffer(…);
h. 读入并编译OpenCL核(kernel)程序:
clCreateProgramWithSource(…);
clBuildProgram(…);
i. 获得核程序中函数的进入点:clCreateKernel(…);
j. 设置函数参数:clSetKernelArg(…);
k. 通过Command Queue执行OpenCL核程序,调用核程序中的函数:
clEnqueueNDRangeKernel(…);
l. 通过Command Queue将函数返回值数据从OpenCL设备内存拷贝到主机内存:
clEnqueueReadBuffer(…);
OpenCL设备端代码:
__kernel void adder(__global const float* a, __global const float* b, __global float* result) {
int idx = get_global_id(0);
result[idx] = a[idx] + b[idx];
}
CUDA主机端和设备端代码保存在同一文件中,CUDA主机端程序流程总结如下:
a. 分配主机端内存,并进行数据初始化;
b. 分配设备端内存,并从主机端将数据拷贝到设备端:
cudaMalloc(…)
cudaMemcpy(…, cudaMemcpyHostToDevice)
c. 调用CUDA的核函数在设备端完成指定的运算:
kernel_function<<<grid, block>>>(…);
d. 将设备端的运算结果拷贝到host上;
cudaMemcpy(…, cudaMemcpyDeviceToHost)
e. 释放设备端和主机端分配的内存。
cudaFree(…)
free(…)
设备端代码如下:
__global__ void
vectorAdd(const float *A, const float *B, float *C, int numElements) {
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < numElements) {
C[i] = A[i] + B[i];
}
}
3. GPGPU架构
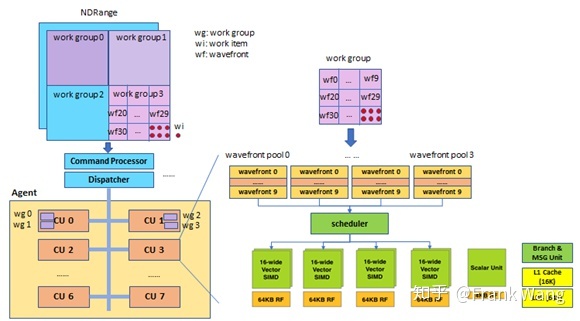
本节以AMD GCN为例说明GPGPU架构。异构计算软件指令的kernel(shader)是被GPGPU处理器执行的程序,从主机内存中获得数据,处理后将结果写主机回内存。kernel以NDRang的形式从主机侧通过command queue送给device。NDRang可以进一步切分为若干work group,每个work group又可以且分为若干wavefront,wavefront由work item组成,也就是软件的线程(thread)。概念上来说,kernel在每个work item上独立执行,但实际上GPGPU处理器将若干个work item组织成一个wavefront,将kernel指令在这64个work item上同时执行。每一个work item以其在网格中唯一个地址(序号)初始化。根据这个序号,work item计算出需要操作的数据地址,以及如何处理结果。

在GPGPU中,计算单元(Compute Unit, CU)是构建整个GPU的基础模块,是最小的独立功能单元。一个CU包括4个SIMD,一个硬件调度器,一个分支单元,一个本地数据存储(LDS),一个标量单元。CU功能结构框图如下图所示:
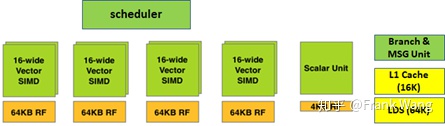
其中,标量单元负责简单ALU不能或效率不高的算术运算,例如条件语句或超越操作。每个CU内部有四组SIMD、每组SIMD阵列由16个ALU矢量(16-wide vector)单元组成(因此每个CU共64个流处理器核心),也就是16个lane,表示一个cycle可以给一个矢量SIMD一条指令和最多16个数据。为了支持分支和条件执行,每个wavefront有一个EXECute掩码,决定某个时刻哪些work item处于活跃状态,哪些work item处于休眠状态。活跃的work item执行矢量指令,休眠的work item则执行NOP。SALU指令可以在任何时候改变EXEC掩码。每组SIMD各自搭配64KB矢量寄存器(VGPR)。
每个CU还有1个标量ALU,标量寄存器(SGPR)只有4KB大小。另外,每个CU有16KB L1 cache,64KB LDS。
因为最小的工作单元是SIMD,一个CU有四组SIMD,所以一个CU同时可以执行四个不同wavefront。一个wavefront是64操作宽(64线程),每个SIMD在每个cycle可以完成其上的wavefront的1/4操作,四个cycle后可以完成当前指令。
下图中的命令处理器(Command Processor, CP)硬件检查命令队列,当发现有新的命令时,启动命令处理,将命令从内存载入。命令顺序载入后并行执行,因此命令处理结束顺序与其启动顺序可能不同。对于设置状态寄存器的命令,CP会将其转给相应硬件模块处理;对于事件处理命令,CP可视情况自行处理,如向主机端发出中断等;对于较复杂的命令,如计算核函数、DMA搬移等,需要用到状态寄存器中其它信息,如核的参数等,CP将其交由对应硬件模块处理。
这里主要关注的是对kernel的处理。CP处理完计算核命令后,Dispatcher将根据状态寄存器信息分发核的计算任务。这些信息包括OpenCL或CUDA API中定义的参数,如OpenCL的clEnqueueNDRangeKernel API:
cl_int clEnqueueNDRangeKernel(cl_command_queue command_queue,
cl_kernel kernel,
cl_uint work_dim,
const size_t *global_work_offset,
const size_t *global_work_size,
const size_t *local_work_size,
cl_uint num_events_in_wait_list,
const cl_event *event_wait_list,
cl_event *event)相应地,状态寄存器也会有全局work item维度、work group大小等信息。
Dispatcher负责分发与计算kernel相关的NDRange。Dispatcher根据每个CU的能力,包括寄存器大小,计算能力,以work group为单位分发NDRange。比如work group0、work group1分配给CU0,work group2、work group3分配给CU1。
Dispatcher将任务分发给Engine及其CU后,CU负责完成取指、译码、执行和写回等执行计算kernel的流程,并在kernel执行完成后报告engine。CU内部以wavefront为单位处理work group。在将wavefront调度到ALU上执行之前会在CU内部的wavefront pool缓存,CU一般有4个wavefront pool,每个pool缓存10个wavefront,wavefront由scheduler调度到vector ALU上执行。每个wavefront有64个work item,SMID每个cycle可以执行16个work item,所以一个wavefront需要4个cycle执行完。每个wavefront对应有一个PC指针,共40个PC指针。
另外,每个wavefront的寄存器值保存在寄存器文件的不同位置,GPU 上下文切换和CPU不同,不需要将寄存器值转存到内存中,而是在寄存器文件中另找空闲空间保存新的wavefront的寄存器值。下图中work group和wavefront仅是示意说明,实际产品设计可能与此不同。
kernel分发主要过程如下:
主机端runtime可以为一个agent生成0个或多个AQL(Architected Queuing Language)队列,用于存放AQL packet。Agent中的packer processor负责检测和分发来自AQL队列的kernel。对于AMD GPU,packer processor包括命令处理器(Command Processor, CP)、异步分发控制器(Asynchronous Dispatch Controller, ADC) 和shader处理器输入控制器(Shader Processor Input controller, SPI)。内核分发过程如下:
a. 由执行内核的agent获取指向AQL队列的指针;
b. 获取指向内核的内核描述符指针;
c. 使用runtime内存分配api为内核参数分配内存;
d. 将内核参数值赋给内核参数内存。对于AMDGPU,内核执行时访问内核参数内存的方式与访问常量存储区(constant memory)相同;
e. AQL队列生成AQL内核分发packet,packet中包含与分发有关的信息,如grid或work group的大小,以及对象文件中关于内核的信息,如段的大小。runtime会在队列中为packet预留空间,队列的任何内容变化都会通知agent;
f. CP配置GPU执行wavefront,确保wavefront开始执行时,内核机器码所需的SGPR和VGPR已经配置完成;
g. 当内核执行完成,CP将内核分发packet中的完成信号置位。
4. 软硬件接口设计
GPGPU后端通常会生成一个标准ELF格式的可重定位(relocatable)对象文件,这个对象文件可以由lld链接产生一个标准ELF共享对象文件,并由GPGPU加载和执行。ELF格式详细解析见参考文献[5]。ELF文件格式提供了两种视图,分别是链接视图和执行视图。链接视图就是在链接时用到的视图,而执行视图则是在执行时用到的视图。链接视图是以节(section)为单位,执行视图是以段(segment)为单位。可重定位ELF文件看作是节头表描述的节的集合,其中有标准节,也可以有自定义节。自定义节中的信息由编译器产生,经过驱动解析后通过CP保存在芯片寄存器中。以AMDGPU backend为例,在其生成的ELF文件的 .note节中 包含Code object V2/3 metadata信息,GPU在执行kernel时会用到这些信息:

WIP
参考文献
[1] http://www.kimicat.com/opencl-1/opencl-jiao-xue-yi
[2] https://github.com/zchee/cuda-sample/blob/master/0_Simple/vectorAdd/vectorAdd.cu
[3] https://zhuanlan.zhihu.com/p/34587739
[4] https://www.anandtech.com/show/4455/amds-graphics-core-next-preview-amd-architects-for-compute
[5] https://paper.seebug.org/papers/Archive/refs/elf/Understanding_ELF.pdf















 1640
1640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









