





最近碰见一些同学在咨询小乔,照片墙叠加的合成效果是怎么做的
这里就给大家具体讲解一下操作过程,其实特别的简单,几乎没有涉及什么困难的知识点
唯一要注意的就是处理图像时参数的调整,排布
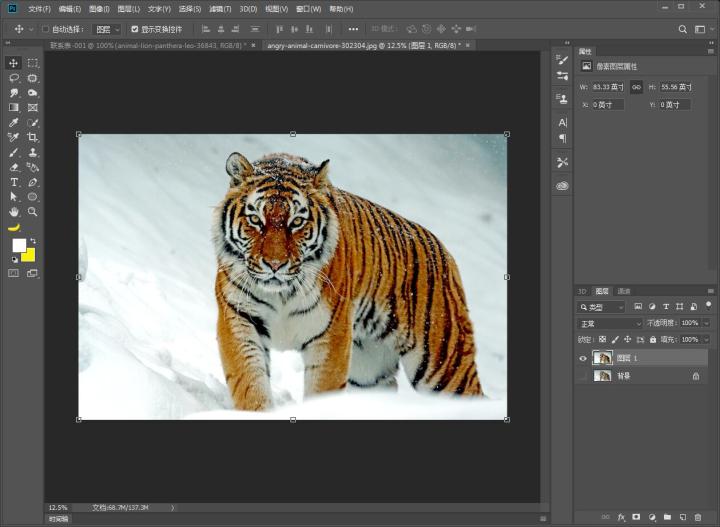
好啦我们还是先看看效果图

操作的时候我们还是老规矩,总结一下:
1、运用ps当中的动作命令改变图像大小
2、运用联系表功能排布
3、把处理好的图像设定为图案
4、添加图案
步骤虽然很少,但是小乔还是会仔细把每一个步骤都给大家讲到,相信同学们一定可以学会哟~
步骤一:我们在菜单栏中找到:窗口→动作
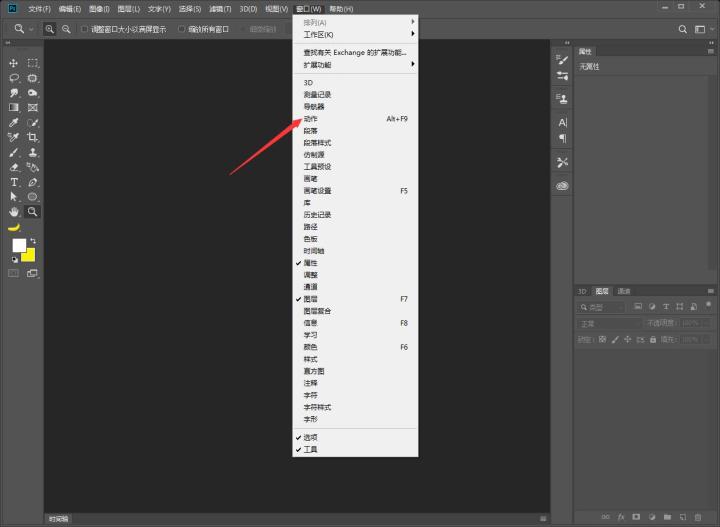
步骤二:新建立一个步骤指令,ps:建立之后就已经开始录制了
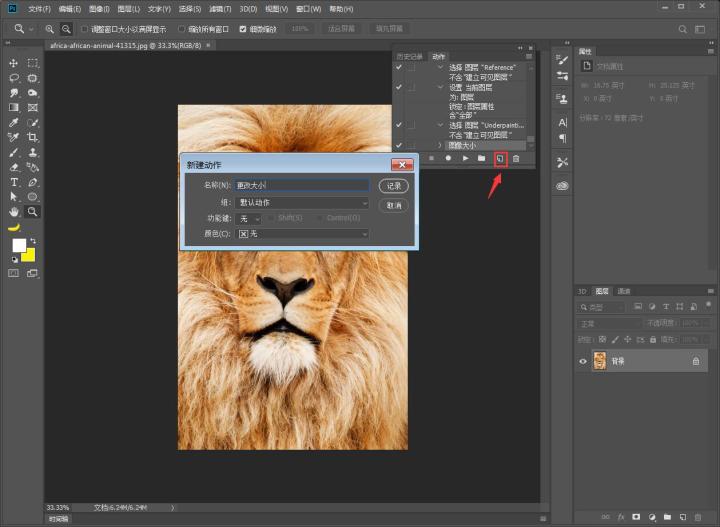
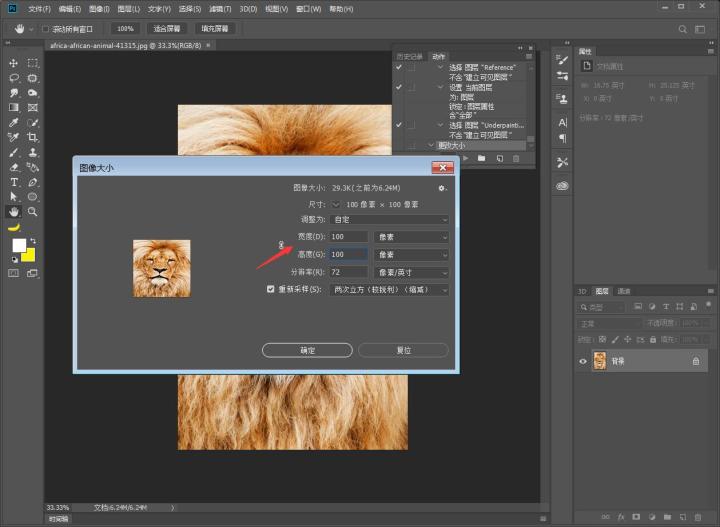
步骤三:我们在菜单栏中:图像→图像大小,设置我们的图像大小(这里的参数仅供参考,因为小乔用了49张图片,打算排布成一个7*7的正方形图像)
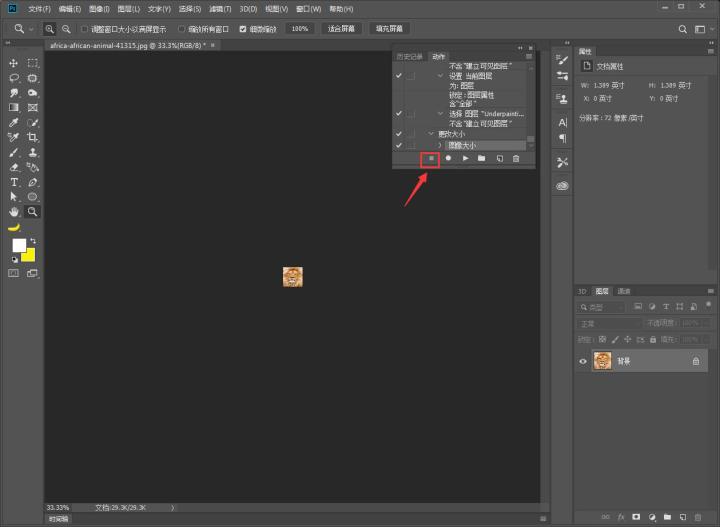
步骤四:停止动作,此时我们的动作录制就完成咯~
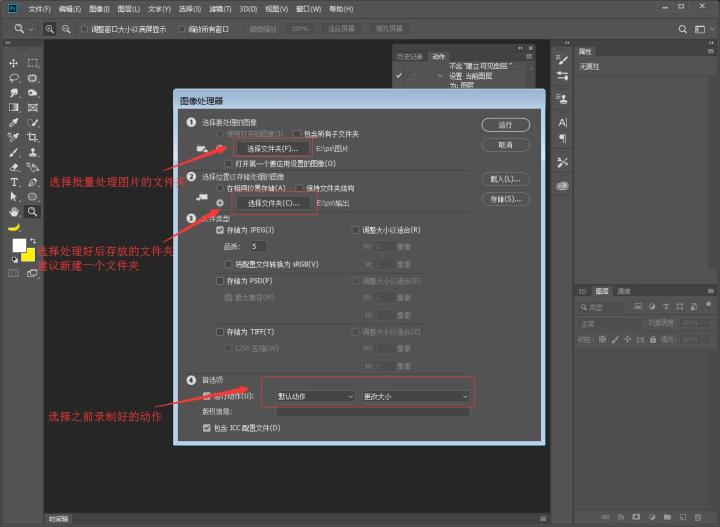
步骤五:我们开始批量处理图像,在菜单栏中:文件→脚本→图像处理 ,弹出对话框之后我们设置,具体操作如下图所示
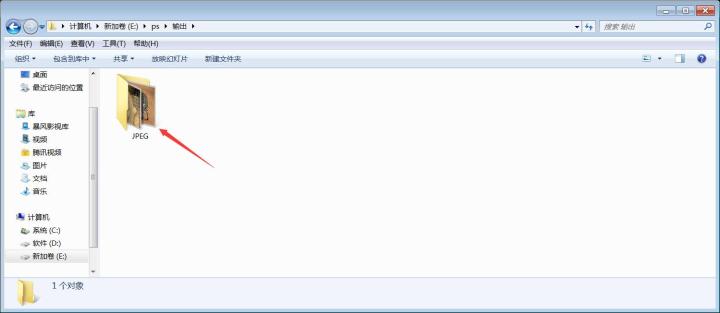
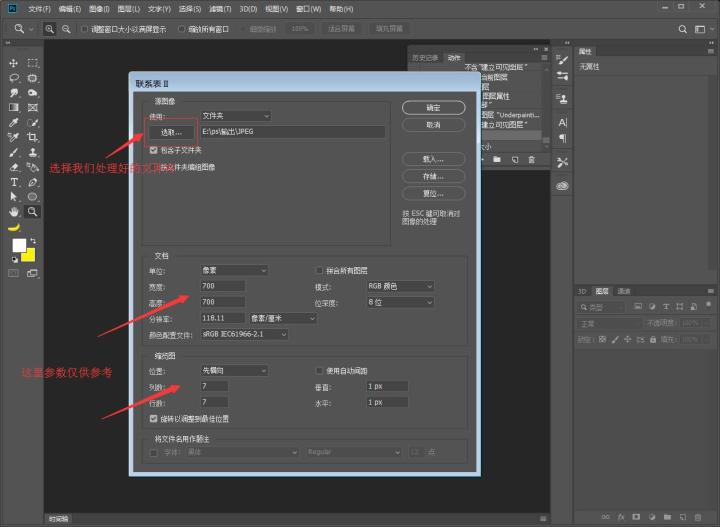
步骤六:我们处理好的图像会在JPEG的文件夹中,我们回到ps,在菜单栏中:文件→自动→联系表Ⅱ,弹出对话框之后设置参数,具体操作如下图所示(这里我们要稍微计划一下制作一个多大的图像,没设置好容易出现留白过多~)
步骤七:排列好之后,我们在菜单栏中:编辑→定义图案,换个名称易于辨认,到这里我们的进度就完成一大半了~

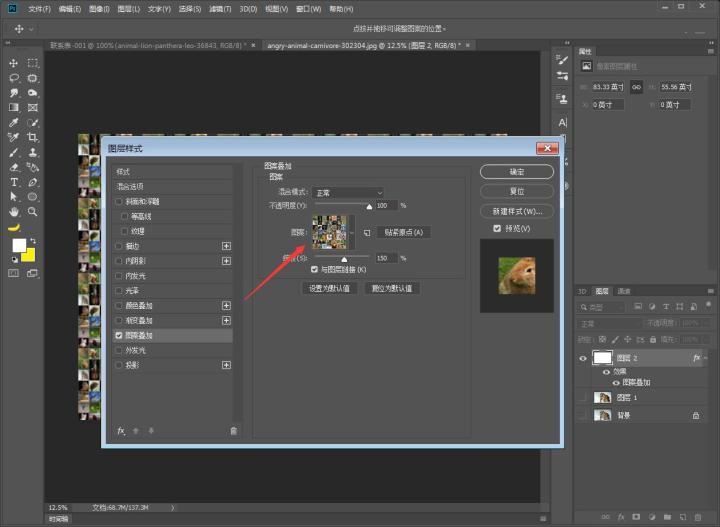
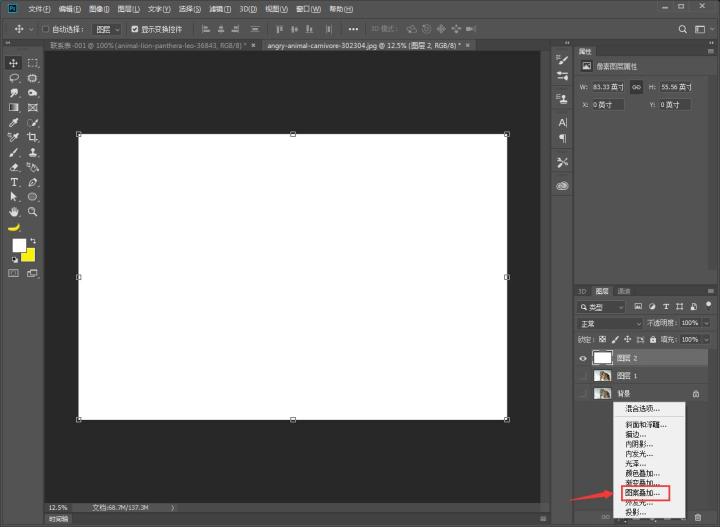
步骤八:导致我们的素材,接着我们新建一个图层填充为白色,点击右下角的添加图层样式→图案添加,添加我们之前做好的图案
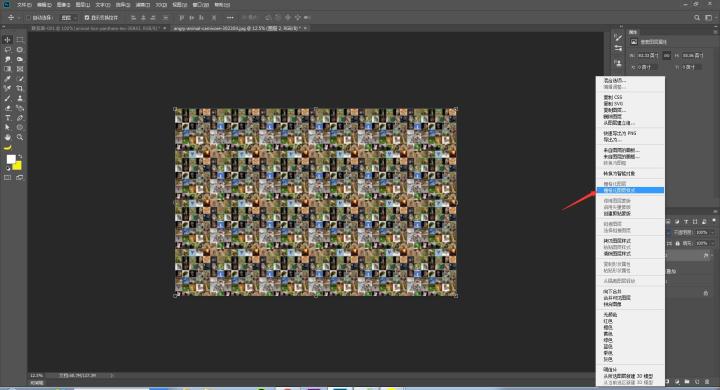
步骤九:鼠标右键→栅格化图层,然后去色(快捷键 Ctrl+Alt+u)
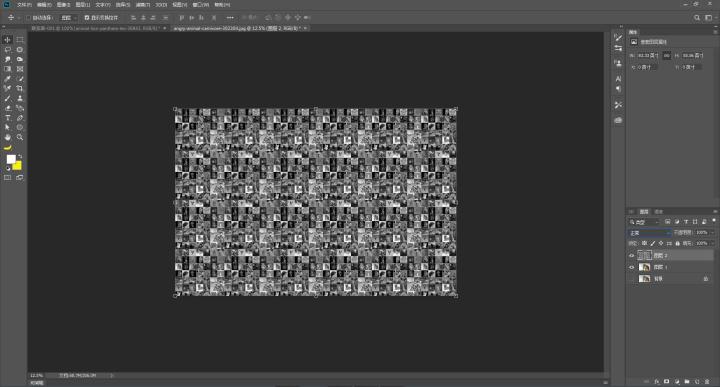
步骤十:我们跟换一下混合模式,这里小乔是用的叠加
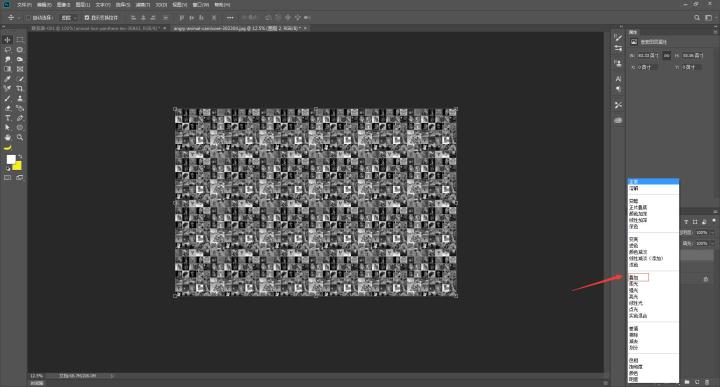
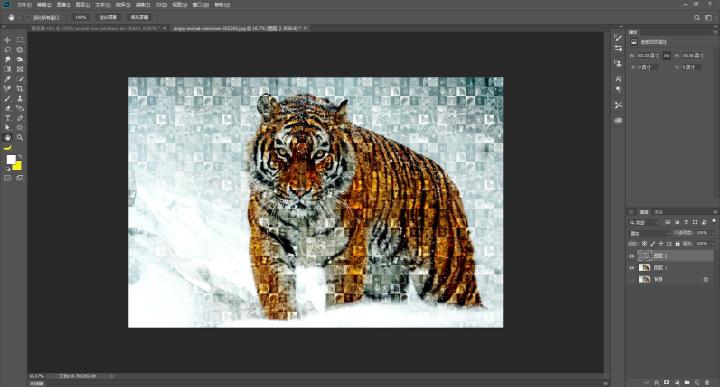
完成~
好啦,今天的多图片排列的合成效果就结束了
不知道给为同学看明白没有? 赶快去亲自试一试吧~
当然有问题或者有更好的方法欢迎在评论区留言~
看完觉得不错的朋友:
1、关注我不迷路,收藏点赞一条龙~
2、我们还建立一个交流群,欢迎大家加入共同学习进步
群内还有软件安装包、素材、学习笔记各种福利,难道你不来看看嘛
















 589
589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









