






#求Sigmoid函数def Sigmoid(z): g = 1 / (1 + np.exp(-z)) return g#将z = X * theta 带入Sigmoid函数def model(X, theta): return Sigmoid(X * theta)#求J(theta)def computCost(X, y, theta): m = X.shape[0] inner = float(y.T * np.log(model(X, theta)) + (1 - y).T * np.log(1 - model(X, theta))) return (- 1 / m) * (inner)#求J(theta(j))的偏导def gradient(X, y, theta): m = X.shape[0] J = theta.shape[0] grad = np.zeros(theta.shape) for j in range(J): term = ((model(X, theta) - y).T * X[ : , j]) grad[j, 0] = term / m return grad#批量梯度下降def BGD(X, y, theta, alpha, liters): cost = [computCost(X, y, theta)] m = X.shape[0] for k in range(liters): theta = theta - (alpha * gradient(X, y, theta)) cost.append(computCost(X, y, theta)) return theta, cost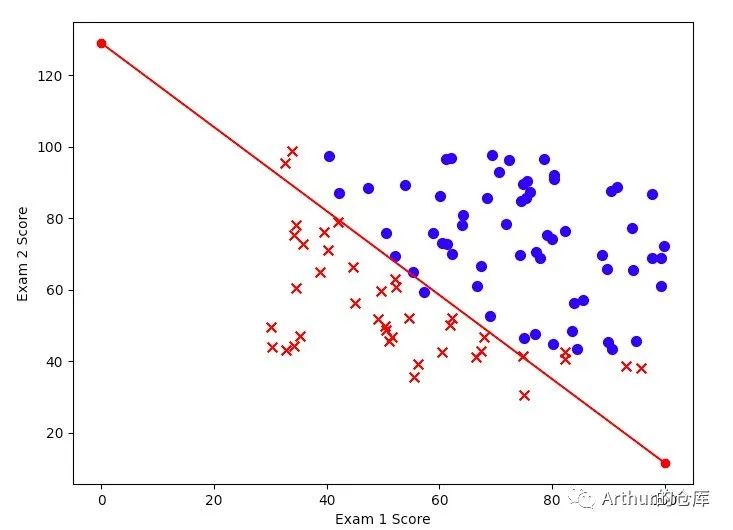
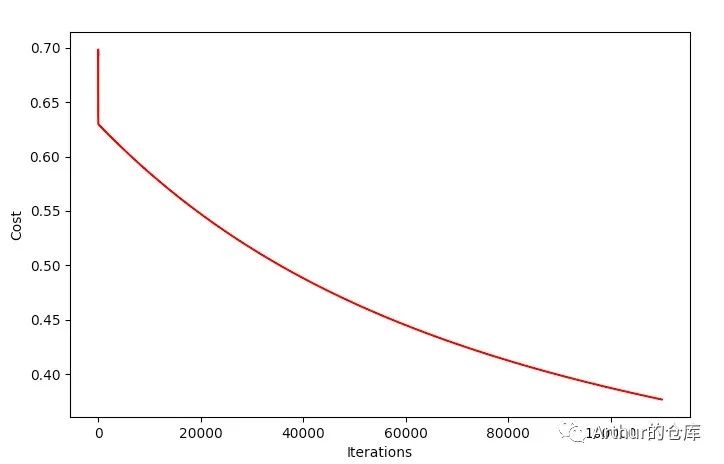
批量梯度下降需要迭代110000万次
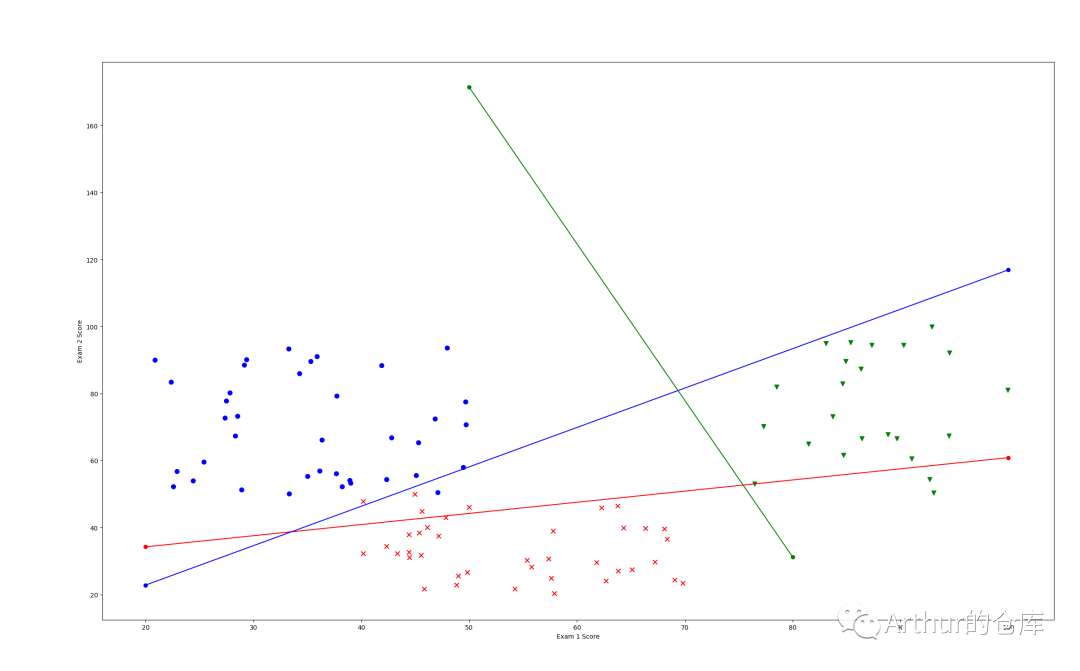
多分类:
代价函数求导:
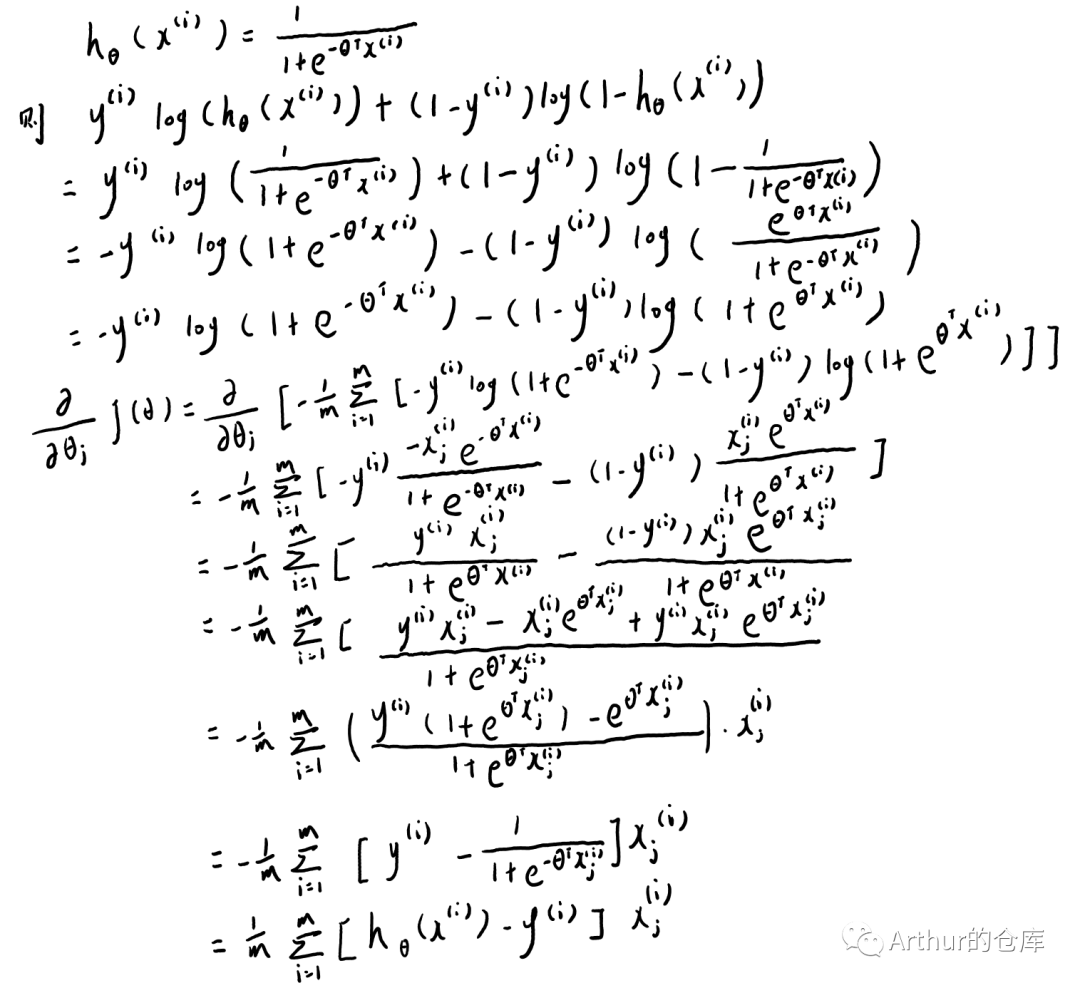
代价函数为平方时非凸:
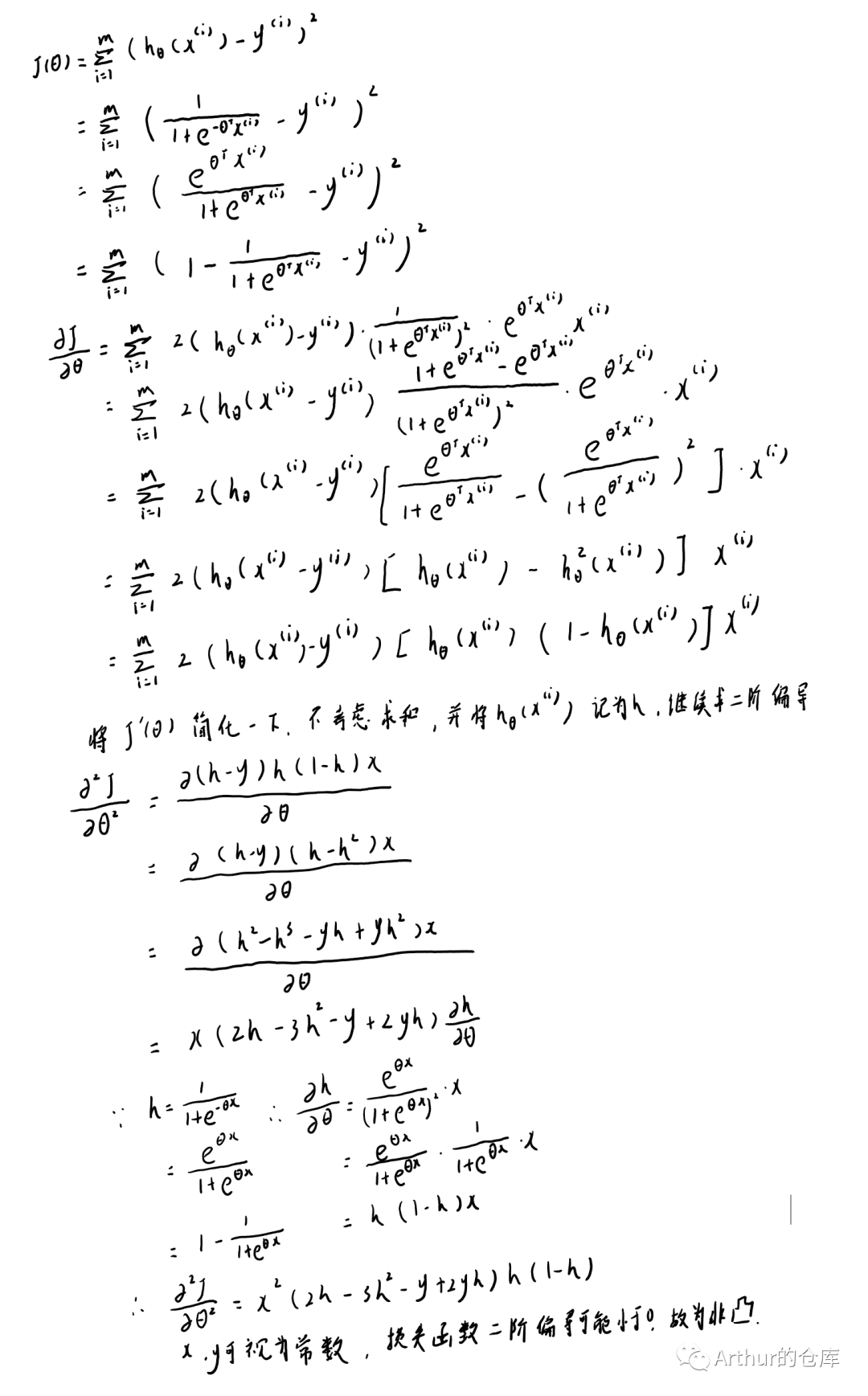
#特征映射def feature_mapping(X1, X2, power): data = {} for i in range(power + 1): for j in range(i + 1): data['F{}{}'.format(i - j, j)] = np.power(X1, i - j) * np.power(X2, j) return pd.DataFrame(data)#正则化逻辑回归代价函数J(theta)def computCost(X, y, theta, lamda): m = X.shape[0] left = (- 1 / m) * float(y.T * np.log(model(X, theta)) + (1 - y).T * np.log(1 - model(X, theta))) right = np.sum(np.power(theta[1:],2)) * (lamda / (2 * m)) return left + right#求J(theta(j))的偏导def gradient(X, y, theta): m = X.shape[0] J = theta.shape[0] grad = np.zeros(theta.shape) for j in range(J): term = ((model(X, theta) - y).T * X[ : , j]) grad[j, 0] = term / m return grad#正则化逻辑回归批量梯度下降def BGD(X, y, theta, alpha, liters, lamda): cost = [computCost(X, y, theta, lamda)] for k in range(liters): reg = theta[1:] * (lamda / X.shape[0]) reg = np.insert(reg,0,values=0,axis=0) theta = theta - (alpha * gradient(X, y, theta)) - reg cost.append(computCost(X, y, theta, lamda)) return theta, cost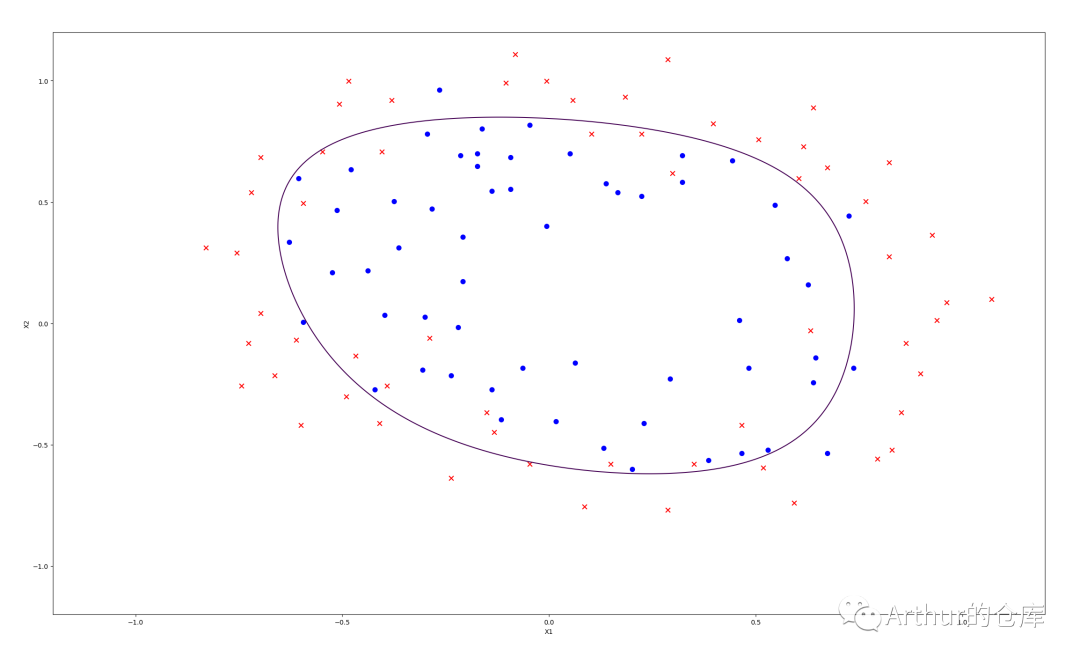
#线性回归正则化计算损失函数def regularized_Cost(X, y, theta, lamda): m = X.shape[0] cost = np.power((X * theta - y), 2) reg = lamda * np.power(theta[1 : ], 2) return (np.sum(cost) + np.sum(reg)) / (2 * m)#求梯度def gradient(X, y, theta): m = X.shape[0] J = theta.shape[0] grad = np.matrix(np.zeros(theta.shape)) for j in range(J): term = (((X * theta) - y).T * X[ : , j]) grad[j, 0] = term / m return grad#正则化梯度def regularized_gradient(X, y, theta, lamda): m = X.shape[0] regularized_term = theta.copy() regularized_term[0] = 0 regularized_term = (lamda / m) * regularized_term return gradient(X, y, theta) + regularized_term














 3338
3338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









