





Bert是去年google发布的新模型,打破了11项纪录,关于模型基础部分就不在这篇文章里多说了。这次想和大家一起读的是huggingface的pytorch-pretrained-BERT代码examples里的文本分类任务run_classifier。
关于源代码可以在huggingface的github中找到。
huggingface/pytorch-pretrained-BERTgithub.com
在前三篇文章中我分别介绍了数据预处理部分和部分的模型:
周剑:一起读Bert文本分类代码 (pytorch篇 一)zhuanlan.zhihu.com
我们可以看到BertForSequenceClassification类中调用关系如下图所示。本篇文章中,我会和大家一起读BertEncoder类中调用的BertLayer,BertAttention,BertSelfAttention和BertSelfOutput这几个类的代码。

打开pytorch_pretrained_bert.modeling.py,找到BertLayer类,代码如下:
class BertLayer(nn.Module):
def __init__(self, config):
super(BertLayer, self).__init__()
self.attention = BertAttention(config)
self.intermediate = BertIntermediate(config)
self.output = BertOutput(config)
def forward(self, hidden_states, attention_mask):
attention_output = self.attention(hidden_states, attention_mask)
intermediate_output = self.intermediate(attention_output)
layer_output = self.output(intermediate_output, attention_output)
return layer_output从forward开始看,依次进入BertAttention,BertIntermediate和BertOutput这三个类。
我们先找到BertAttention这个类,代码如下:
class BertAttention(nn.Module):
def __init__(self, config):
super(BertAttention, self).__init__()
self.self = BertSelfAttention(config)
self.output = BertSelfOutput(config)
def forward(self, input_tensor, attention_mask):
self_output = self.self(input_tensor, attention_mask)
attention_output = self.output(self_output, input_tensor)
return attention_output可以看到BertAttention类是由BertSelfAttention和BertSelfOutput组成的。
我们再找到BertSelfAttention这个类,代码如下:
class BertSelfAttention(nn.Module):
def __init__(self, config):
super(BertSelfAttention, self).__init__()
if config.hidden_size % config.num_attention_heads != 0:
raise ValueError(
"The hidden size (%d) is not a multiple of the number of attention "
"heads (%d)" % (config.hidden_size, config.num_attention_heads))
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(config.hidden_size, self.all_head_size)
self.key = nn.Linear(config.hidden_size, self.all_head_size)
self.value = nn.Linear(config.hidden_size, self.all_head_size)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(self, hidden_states, attention_mask):
mixed_query_layer = self.query(hidden_states)
mixed_key_layer = self.key(hidden_states)
mixed_value_layer = self.value(hidden_states)
query_layer = self.transpose_for_scores(mixed_query_layer)
key_layer = self.transpose_for_scores(mixed_key_layer)
value_layer = self.transpose_for_scores(mixed_value_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
# Apply the attention mask is (precomputed for all layers in BertModel forward() function)
attention_scores = attention_scores + attention_mask
# Normalize the attention scores to probabilities.
attention_probs = nn.Softmax(dim=-1)(attention_scores)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
return context_layer可以看到,BertSelfAttention这个类终于有点真东西了。
从forward开始看。首先是query_layer,key_layer和value_layer分别是三个线形Linear层,对应进入Multi-Head Attention。下图是Transformer的encoder模型,来源于(Attention Is All You Need)这篇论文。
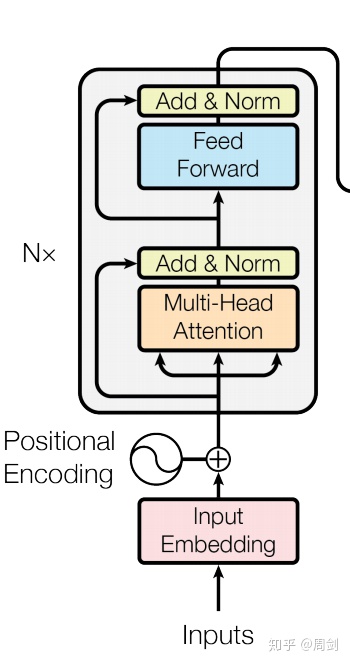
从图中可以看到query_layer,key_layer和value_layer三层进入Multi-Head Attention。而Multi-Head Attention内部如下图:
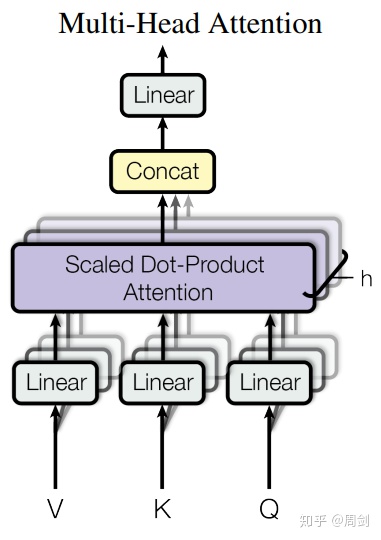
Multi-Head Attention内部的Scaled Dot-Product Attention结构如下图。
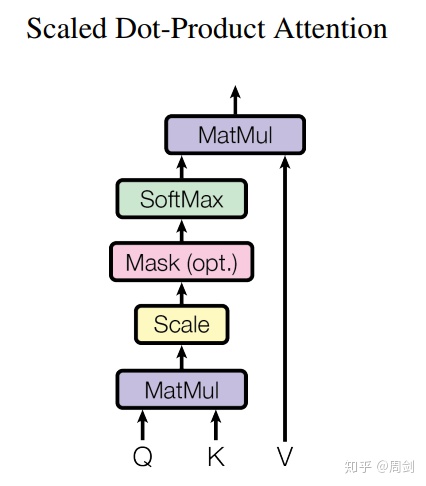
因此,我们可以看到BertSelfAttention类中如下代码是计算Scaled Dot-Product Attention的。
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
# Apply the attention mask is (precomputed for all layers in BertModel forward() function)
attention_scores = attention_scores + attention_mask
# Normalize the attention scores to probabilities.
attention_probs = nn.Softmax(dim=-1)(attention_scores)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
context_layer = torch.matmul(attention_probs, value_layer)再接着BertSelfAttention的forward继续看。剩下下的主要是contact和tensor的shape调整。解释一下其中的一些tensor的函数。
tensor.permute()是shape位置交换函数,例如一个tensor的shape是tensor[(3, 5, 6)], tensor.permute(0, 2, 1)后,shape变为tensor[(3, 6, 5)].
contiguous:view只能用在contiguous的variable上。如果在view之前用了transpose, permute等,需要用contiguous()来返回一个contiguous copy。
在pytorch 0.4.0版本新添加了reshape函数,类似于numpy.reshape()。它大致相当于 tensor.contiguous().view().
关于tensor.view()的解释官方文档如下:
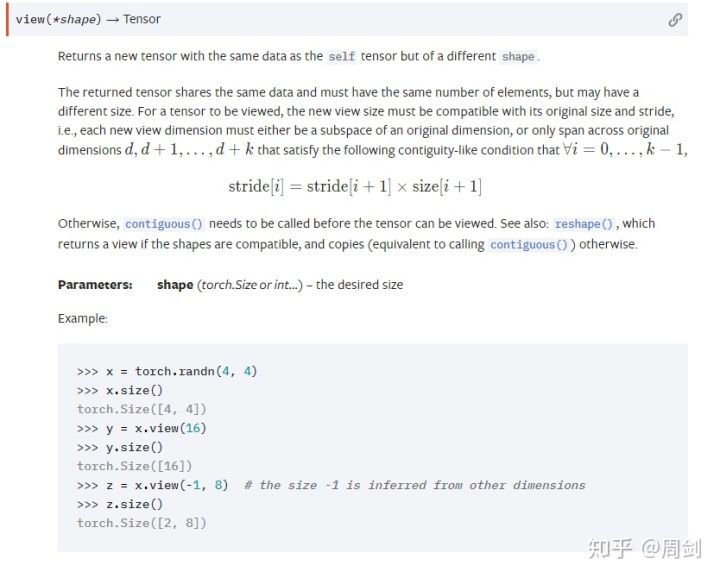
这样我们就读完了BertSelfAttention这个类,我们接下来看BertSelfOutput这个类,它的代码如下:
class BertSelfOutput(nn.Module):
def __init__(self, config):
super(BertSelfOutput, self).__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.LayerNorm = BertLayerNorm(config.hidden_size, eps=1e-12)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states, input_tensor):
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states发现就是一个线形Linear层+dropout+一个LayerNorm。BertSelfAttention和BertSelfOutput,这也就是BertAttention这个类的全部。
下一篇文章中我会带着大家继续读BertLayer类中的BertIntermediate和BertOutput类。
周剑:一起读Bert文本分类代码 (pytorch篇 五)zhuanlan.zhihu.com















 1384
1384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









