






BERT 是一个强大的语言模型,至少有两个原因:
- 它使用从 BooksCorpus (有 8 亿字)和 Wikipedia(有 25 亿字)中提取的未标记数据进行预训练。
- 顾名思义,它是通过利用编码器堆栈的双向特性进行预训练的。这意味着 BERT 不仅从左到右,而且从右到左从单词序列中学习信息。
BERT 模型需要一系列 tokens (words) 作为输入。在每个token序列中,BERT 期望输入有两个特殊标记:
- [CLS] :这是每个sequence的第一个token,代表分类token。
- [SEP] :这是让BERT知道哪个token属于哪个序列的token。这一特殊表征法主要用于下一个句子预测任务或问答任务。如果我们只有一个sequence,那么这个token将被附加到序列的末尾。
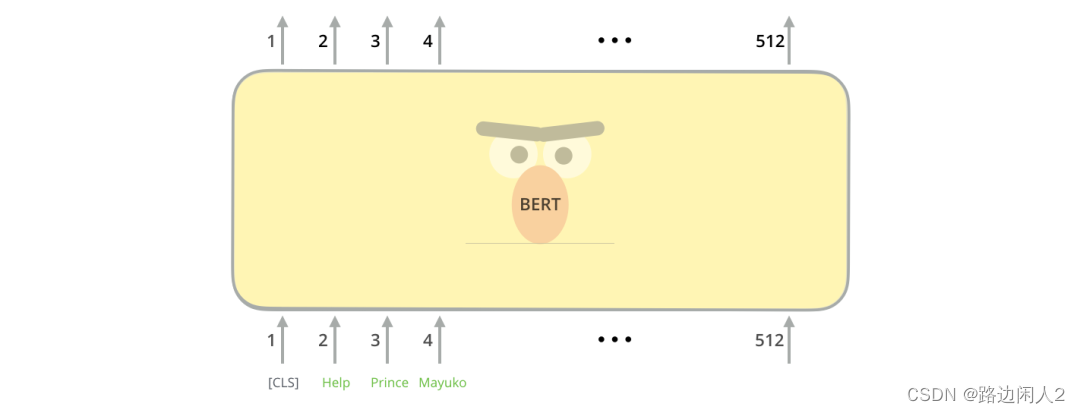
就像Transformer的普通编码器一样,BERT 将一系列单词作为输入,这些单词不断向上流动。每一层都应用自我注意,并将其结果通过前馈网络传递,然后将其传递给下一个编码器。
BERT 输出
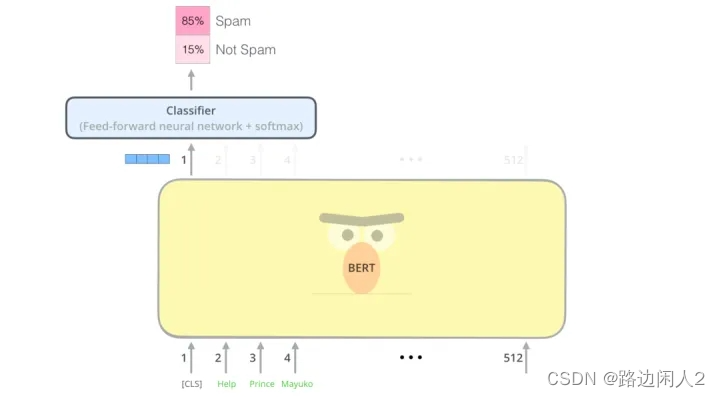
每个位置输出一个大小为 hidden_ size的向量(BERT Base 中为 768)。对于我们在上面看到的句子分类示例,我们只关注第一个位置的输出(将特殊的 [CLS] token 传递到该位置)。
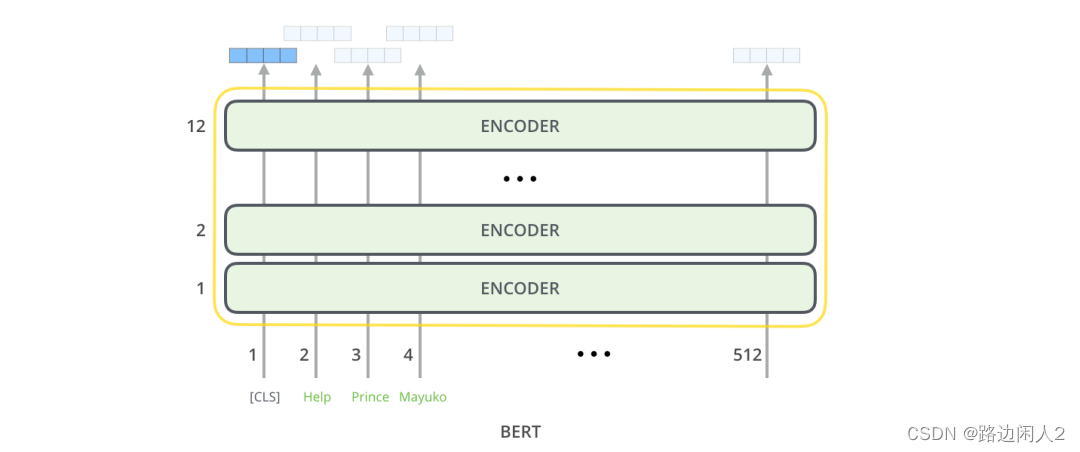
该向量现在可以用作我们选择的分类器的输入。该论文仅使用单层神经网络作为分类器就取得了很好的效果。
使用 BERT 进行文本分类
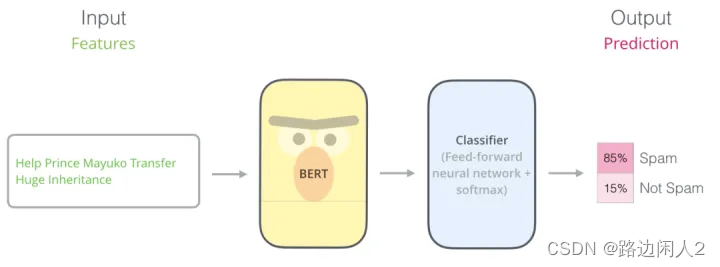
本文的主题是用 BERT 对文本进行分类。
在这篇文章中,我们将使用kaggle上的BBC 新闻分类数据集。
数据集已经是 CSV 格式,它有 2126 个不同的文本,每个文本都标记在 5 个类别中的一个之下:
sport(体育),business(商业),politics(政治),tech(科技),entertainment(娱乐)。
模型下载 https://huggingface.co/bert-base-cased/tree/main
数据集下载 bbc-news https://huggingface.co/datasets/SetFit/bbc-news/tree/main
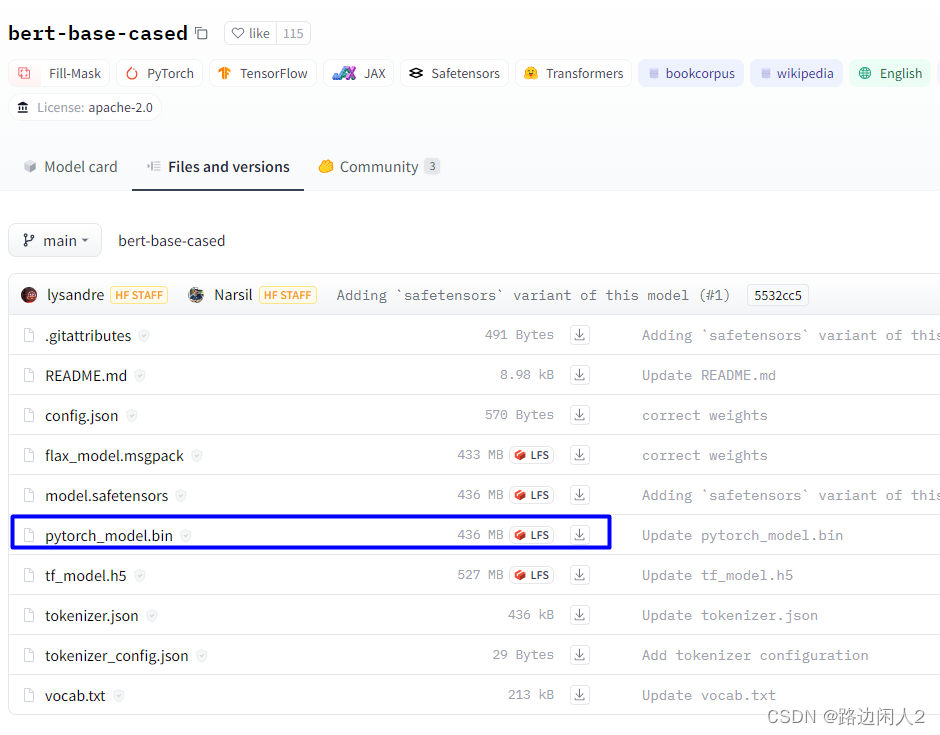
有4个400多MB的文件,pytorch的模型对应的是436MB的那个文件。
需要安装transforms库
pip install transforms 全部的流程代码:
# 全部流程代码
import numpy as np
import torch
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-cased')
labels = {'business':0,
'entertainment':1,
'sport':2,
'tech':3,
'politics':4
}
class Dataset(torch.utils.data.Dataset):
def __init__(self, df):
self.labels = [labels[label] for label in df['category']]
self.texts = [tokenizer(text,
padding='max_length',
max_length = 512,
truncation=True,
return_tensors="pt")
for text in df['text']]
def classes(self):
return self.labels
def __len__(self):
return len(self.labels)
def get_batch_labels(self, idx):
# Fetch a batch of labels
return np.array(self.labels[idx])
def get_batch_texts(self, idx):
# Fetch a batch of inputs
return self.texts[idx]
def __getitem__(self, idx):
batch_texts = self.get_batch_texts(idx)
batch_y = self.get_batch_labels(idx)
return batch_texts, batch_y
# 数据集准备
# 拆分训练集、验证集和测试集 8:1:1
import pandas as pd
bbc_text_df = pd.read_csv('./bbc-news/bbc-text.csv')
# bbc_text_df.head()
df = pd.DataFrame(bbc_text_df)
np.random.seed(112)
df_train, df_val, df_test = np.split(df.sample(frac=1, random_state=42), [int(.8*len(df)), int(.9*len(df))])
print(len(df_train),len(df_val), len(df_test))
# 1780 222 223
# 构建模型
from torch import nn
from transformers import BertModel
class BertClassifier(nn.Module):
def __init__(self, dropout=0.5):
super(BertClassifier, self).__init__()
self.bert = BertModel.from_pretrained('bert-base-cased')
self.dropout = nn.Dropout(dropout)
self.linear = nn.Linear(768, 5)
self.relu = nn.ReLU()
def forward(self, input_id, mask):
_, pooled_output = self.bert(input_ids= input_id, attention_mask=mask,return_dict=False)
dropout_output = self.dropout(pooled_output)
linear_output = self.linear(dropout_output)
final_layer = self.relu(linear_output)
return final_layer
#从上面的代码可以看出,BERT Classifier 模型输出了两个变量:
#1. 在上面的代码中命名的第一个变量_包含sequence中所有 token 的 Embedding 向量层。
#2. 命名的第二个变量pooled_output包含 [CLS] token 的 Embedding 向量。对于文本分类任务,使用这个 Embedding 作为分类器的输入就足够了。
# 然后将pooled_output变量传递到具有ReLU激活函数的线性层。在线性层中输出一个维度大小为 5 的向量,每个向量对应于标签类别(运动、商业、政治、 娱乐和科技)。
from torch.optim import Adam
from tqdm import tqdm
def train(model, train_data, val_data, learning_rate, epochs):
# 通过Dataset类获取训练和验证集
train, val = Dataset(train_data), Dataset(val_data)
# DataLoader根据batch_size获取数据,训练时选择打乱样本
train_dataloader = torch.utils.data.DataLoader(train, batch_size=2, shuffle=True)
val_dataloader = torch.utils.data.DataLoader(val, batch_size=2)
# 判断是否使用GPU
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=learning_rate)
if use_cuda:
model = model.cuda()
criterion = criterion.cuda()
# 开始进入训练循环
for epoch_num in range(epochs):
# 定义两个变量,用于存储训练集的准确率和损失
total_acc_train = 0
total_loss_train = 0
# 进度条函数tqdm
for train_input, train_label in tqdm(train_dataloader):
train_label = train_label.to(device)
mask = train_input['attention_mask'].to(device)
input_id = train_input['input_ids'].squeeze(1).to(device)
# 通过模型得到输出
output = model(input_id, mask)
# 计算损失
batch_loss = criterion(output, train_label)
total_loss_train += batch_loss.item()
# 计算精度
acc = (output.argmax(dim=1) == train_label).sum().item()
total_acc_train += acc
# 模型更新
model.zero_grad()
batch_loss.backward()
optimizer.step()
# ------ 验证模型 -----------
# 定义两个变量,用于存储验证集的准确率和损失
total_acc_val = 0
total_loss_val = 0
# 不需要计算梯度
with torch.no_grad():
# 循环获取数据集,并用训练好的模型进行验证
for val_input, val_label in val_dataloader:
# 如果有GPU,则使用GPU,接下来的操作同训练
val_label = val_label.to(device)
mask = val_input['attention_mask'].to(device)
input_id = val_input['input_ids'].squeeze(1).to(device)
output = model(input_id, mask)
batch_loss = criterion(output, val_label)
total_loss_val += batch_loss.item()
acc = (output.argmax(dim=1) == val_label).sum().item()
total_acc_val += acc
print(
f'''Epochs: {epoch_num + 1}
| Train Loss: {total_loss_train / len(train_data): .3f}
| Train Accuracy: {total_acc_train / len(train_data): .3f}
| Val Loss: {total_loss_val / len(val_data): .3f}
| Val Accuracy: {total_acc_val / len(val_data): .3f}''')
#我们对模型进行了 5 个 epoch 的训练,我们使用 Adam 作为优化器,而学习率设置为1e-6。
#因为本案例中是处理多类分类问题,则使用分类交叉熵作为我们的损失函数。
EPOCHS = 5
model = BertClassifier()
LR = 1e-6
train(model, df_train, df_val, LR, EPOCHS)
# 测试模型
def evaluate(model, test_data):
test = Dataset(test_data)
test_dataloader = torch.utils.data.DataLoader(test, batch_size=2)
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
if use_cuda:
model = model.cuda()
total_acc_test = 0
with torch.no_grad():
for test_input, test_label in test_dataloader:
test_label = test_label.to(device)
mask = test_input['attention_mask'].to(device)
input_id = test_input['input_ids'].squeeze(1).to(device)
output = model(input_id, mask)
acc = (output.argmax(dim=1) == test_label).sum().item()
total_acc_test += acc
print(f'Test Accuracy: {total_acc_test / len(test_data): .3f}')
# 用测试数据集进行测试
evaluate(model, df_test)
EPOCHS = 5
model = BertClassifier()
LR = 1e-6
train(model, df_train, df_val, LR, EPOCHS)在训练的这一步会非常耗时间,用GPU加速了,也需要大概39分钟.
因为BERT模型本身就是一个比较大的模型,参数非常多。
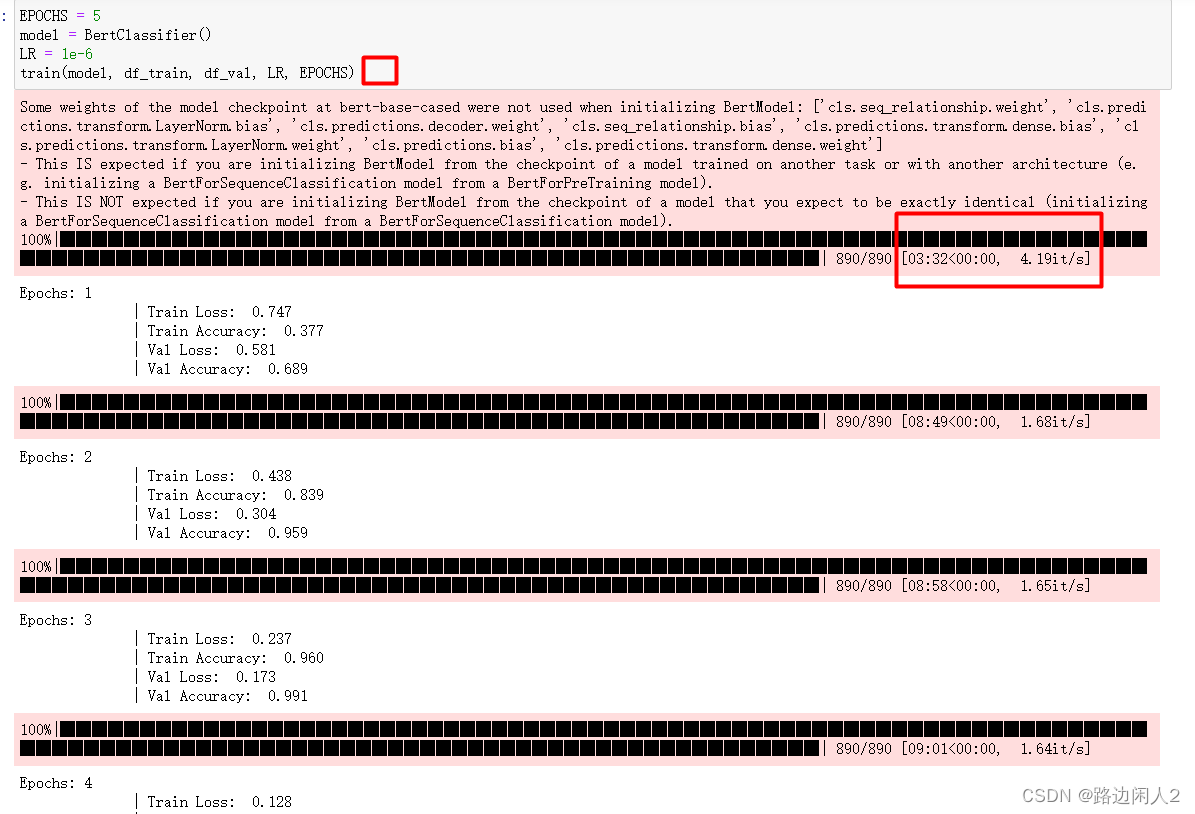
最后一步测试的时候,测试的准确率还是比较高的。达到 99.6%

模型的保存。这个在原文里面是没有提到的。
我们花了很多时间训练的模型如果不保存一下,下次还要重新训练岂不是费时费力?
# 保存模型
torch.save(model.state_dict(),"bertMy.pth")
# load 加载模型
model = BertClassifier()
model.load_state_dict(torch.load("bertMy.pth"))可以用下面的代码查看model里面的模型。
for param_tensor in model.state_dict():
print(param_tensor, "\t", model.state_dict()[param_tensor].size())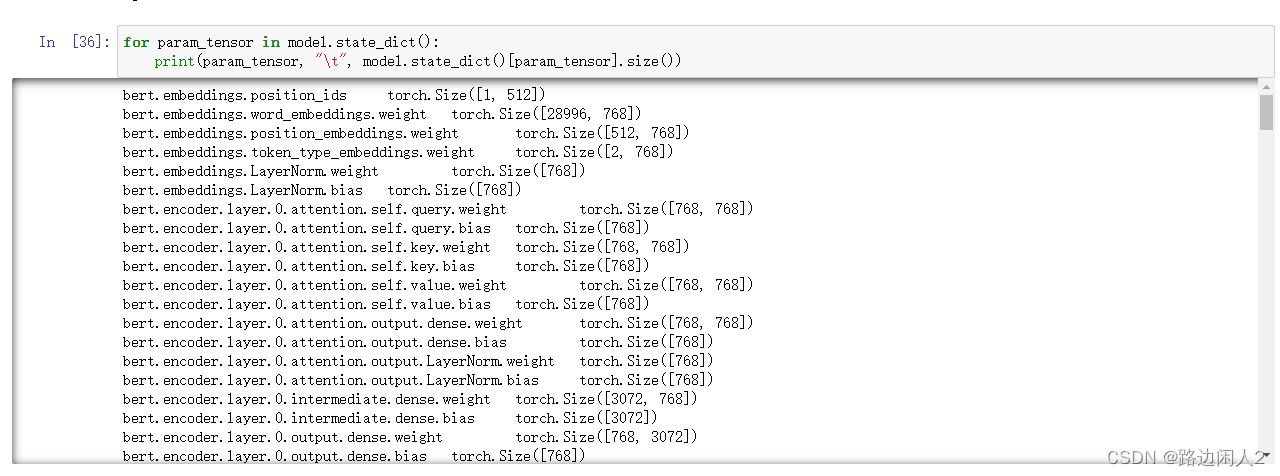
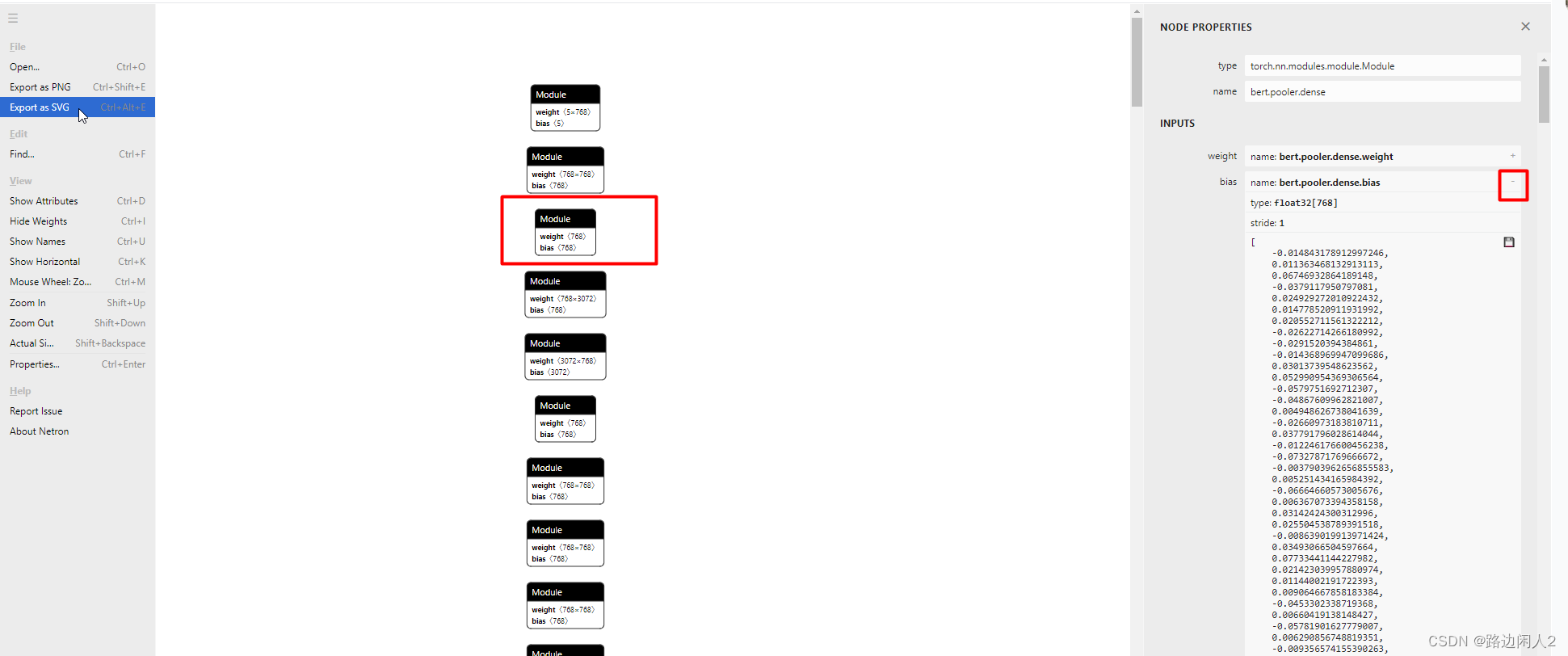
也可以将保存的模型文件 bertMy.pth上传到netron网站进行模型可视化。Netronhttps://netron.app/
原文位于这个地址,但是原文中的代码缺了读csv那一段 :
















 1341
1341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











