







身处互联网时代,我们或许每天都在打开浏览器连接https://www.baidu.com/,然后浏览器呈现出百度首页,这一切是那么的正常。但对于爬虫的学习来说,我们必须了解形形色色的网页是如何呈现出来的。在写爬虫程序之前,我们有必要先了解一些基本知识:
- 1、网络连接原理
- 2、爬虫原理及常见流程
- 3、网页构造基础及Chrome浏览器的使用
一、网络连接原理
在这一部分,我们会了解HTTP的基本原理,了解在输入网址URL到获取网页内容之间到底发生了什么。
1、URL
URL的全称为Uniform Resource Locator,即统一资源定位符。通过特定的URL,我们才能从茫茫互联网中定位到我们需要的资源。一般而言,在目前的互联网中,一般的网页链接都是URL,所以在以后的叙述中,URL即通常所说的网页链接。
2、超文本(hypertext)
我们在浏览器中看到的页面就是有超文本解析而来,所谓超文本就是网页源代码HTML,如下图:

3、HTTP和HTTPS
一般,URL总是以http或https开头,这就是访问资源所需要的协议类型。HTTP的全称为Hyper Text Transfer Protocol,即超文本传输协议。HTTP协议是从网络将超文本传到本地浏览器的传送协议,能够保证高效准确地传送超文本。HTTPS是HTTP下进行SSL加密,HTTPS可以简单理解为HTTP的安全版。
4、HTTP网络连接过程
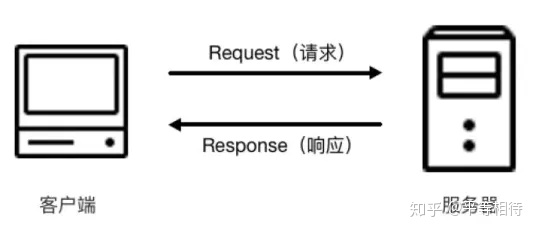
当我们在浏览器中输入url,回车之后即可在浏览器中看到网页内容。这个过程实际上是一个请求和响应的过程,首先是我们的浏览器(客户端)向服务器发起一个Request请求,网站的服务器接收到客户端发送的请求后,进行处理和解析,然后返回相应的响应,并将Response响应传回客户端,客户端浏览器对响应进行解析后将内容呈现出来。对于请求响应过程的一些更底层的东西后面再说。
二、爬虫原理及基本流程
1、爬虫是什么?
如果将互联网想象为一张复杂的蜘蛛网的话,网络爬虫可以理解为一只在网上寻找信息的蜘蛛。简单来讲,网络爬虫就是在互联网上寻找并获取所需数据的自动化程序。
2、爬虫原理
了解网络连接的基本过程后,爬虫的原理也就很好理解了。我们知道浏览器在网络连接过程中的作用是向服务器发送请求和对服务器传回的响应进行解析处理。而爬虫实际上就是对浏览器的模拟,所以一个爬虫程序基本就是做两件事:
(1)模拟浏览器向服务器发送请求
(2)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1358
1358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









