





目录:
1.「Markov」
2.「RNN/LSTM」
3.「VAE」
- 3.1 模型结构
- 3.2 文本生成
4.问题与难点
通俗来讲,自然语言处理有两个分支:自然语言生成(NLG)以及自然语言理解(NLU)。自然语言生成是比较官方学术的说法。实际上,常见的“对话系统生成”、“文本自动摘要”、“智能写作”等,都含有NLG的相关技术。
早期的NLG通过设定句法模版或构建语法结构树,期望生成的文本可以符合句法规则。然而,用这些方式生成的自然文本非常简单,且通常缺少语义信息,不够自然、平滑。本文将从统计语言模型Markov模型开始到RNN/LSTM,VAE,介绍如何使用常见的文本生成器自动生成自然流畅的短文本。
一、「Markov」
在统计自然语言处理领域,通常使用统计语言模型对句子进行建模。语言模型将句子视为序列字符串,对句子中单词的概率分布进行建模。若用表示由单词组成的句子,句长为,则句子出现的概率可表示为:
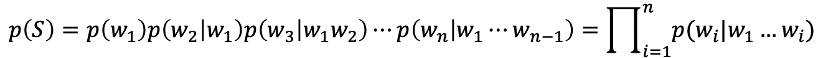
因此,若想自动生成高质量的文本,需要对训练样本集的语言模型获得良好的估计。
Markov模型的模型如下,其主要思想为:当过程时刻状态已知时,过程时刻所处状态的概率特性仅与时刻所处的状态相关,具有无后效性。
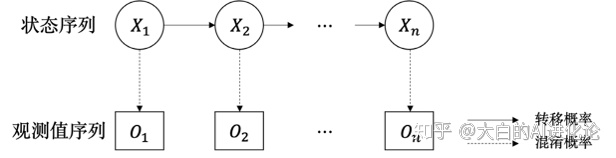
使用Markov进行文本自动生成的过程十分简单。由于文本序列生成的过程中,与上文联系紧密。若仅联系前一时刻进行生成,会造成生成文本混乱,语义不够连贯的问题。对此,可以结合n-gram的思想,使用tri-gram模型,使t时刻生成的文本联系结合t-1,t-2时刻的生成。若采用英文语料集,其具体步骤为(中文语料集多了分词的步骤):
(1)将语料集中单句样本进行tri-gram划分;
(2)构建词典,以前两个词作为key,后一个单词作为value,统计相同的key可接的value值,并将value依据降序排序;
(3)设定起始词,采用贪心策略,根据起始词自动依据key选择出现概率最大的value作为当前的输出。
值得注意的是,使用Markov作为文本生成器进行文本生成速度较慢,即便是使用GPU资源进行加速,仍不能得到较好的训练速度;若给予相同的起始词,生成的语句样本相同(在选择value时,可随机选取排序后前n个词中的一个,即可暂时解决这个问题)。
二、「RNN/LSTM」
char-RNN,是Andrej Karpathy在The Unreasonable Effectiveness of Recurrent Neural Networks提出的字符级循环神经网络。char-RNN以RNN的变体LSTM作为基础单元,在处理序列时,依据序列中数据前后存在的相关性,从字符的维度上,通过已经观测到的字符,推测下一个字符出现的概率,使机器能够生成文本。
char-RNN的原理如下图,其输入与输出都是以字符为单位。图中所示若希望模型学习写出“hello”,在输入为h时,其对应输出应为e;输入为e时,其对应输出应为l,以此类推。输入层使用独热编码表示字符,输出层对生成字符进行预测。通过当前输入得到的输出向量中,最大置信度所在维度置1,其他维度置0,来寻找输出的字符。通过不断增大target所在维度的置信度(output_layer中绿色字体)降低output所在维度的置信度(output_layer中红色字体),对模型进行训练。
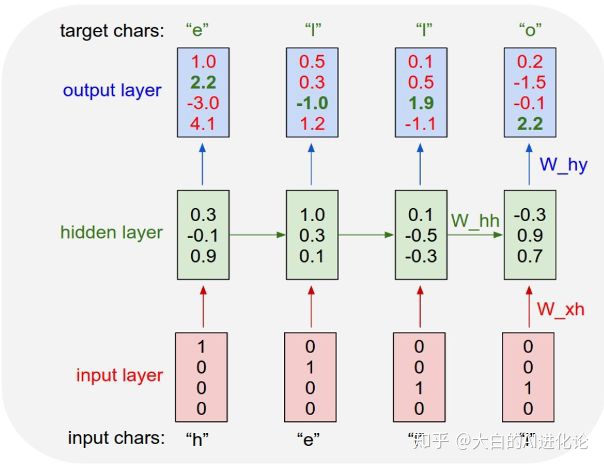
在英文语料集中,我们分别将字母作为字符和将单词作为字符,使用char-RNN,进行训练。得到的结果实际上是没有太大差别的,都可以生成高质量的自然文本。如下


在中文语料集中,字符级别指的就是单字了。我们尝试使用char-RNN生成格律诗,并在其中引入格律诗平仄规则,以期获得更好的效果。如下:

总的来说,依据RNN对序列的友好性,可以通过大量有效样本的训练,得到良好的文本生成效果。
三、「VAE」
VAE (Variational Autoencoders) 是与GAN齐名的无监督学习复杂分布的方法。与GAN类似,它基于一个数学事实:对于一个目标概率分布,给定任何一种概率分布,总存在一个可微的可测函数,将其映射到另一种概率分布,使得这种概率分布与目标的概率分布任意的接近。换句话说,两种方法的目标都是假设服从某些常见的变换,进而得到从隐变量z生成目标数据x的模型,实现分布之间的变换,只是在实现方法有所不同罢了。
在构造X=g(Z)之后,可从g(Z)中进行采样,然而没有合适的度量能够判断z的分布与目标数据集相同。对此,GAN的思路是直接通过神经网络训练出一个合适的度量;而VAE则借助了贝叶斯的思想。接下来,将详细介绍VAE具体的模型实现过程。
1.模型结构
VAE模型的贝叶斯思想体现在,整个模型使用 p(Z|X)(后验分布)是正态分布(独立的、多元的)的假设。也就是说是通过采样出的来还原。值得注意的是,这时候每一个都存在与之对应的正态分布,才便于在后续时刻进行生成器的还原。此时,问题的关键转换成寻找的均值和方差。由于万物皆可用神经网络,在寻找的均值和方差时,同样使用神经网络来进行拟合。简单来说,整个模型可以表示成下图:
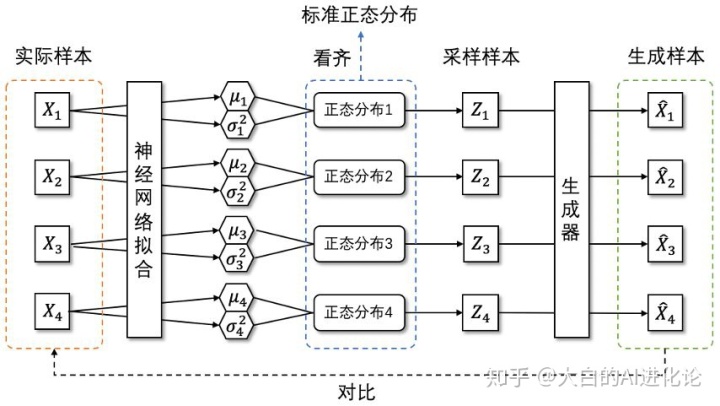
值得注意的是,文章中提及需让向标准正态分布看齐。这样做可以保证了p(Z)(先验分布)是标准正态分布。(感兴趣的朋友可以根据公式证明)
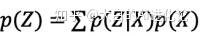
在看齐的过程中,可以通过在重构误差的基础上增加额外误差。额外误差需分两部分进行计算,即计算均值和方差的,将其累加和作为额外的。
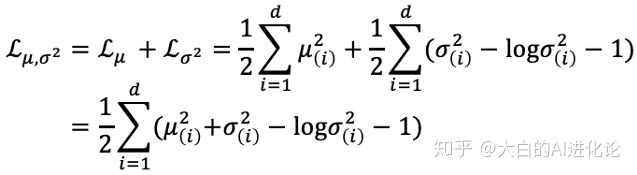
依据KL散度公式,可化为:
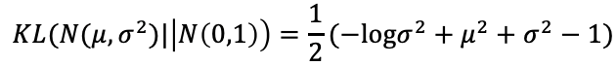
通过最小化KL散度来使逼近标准正态分布。
原文中使用的模型结构图如下:
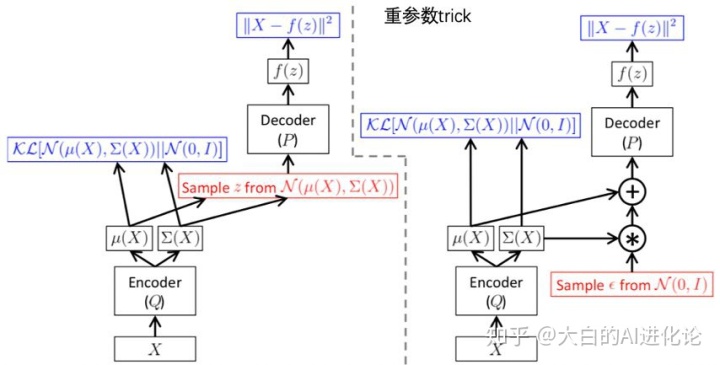
总的来说,整个训练框架可分为一个encoder和一个decoder,encoder使用对实际样本编码为隐变量,而decoder使用P又将隐变量解码成,从而最小化重构误差。学习的目标是学习出encoder和decoder的映射函数。由于整个过程通过寻找映射函数来优化目标,因此叫VAE(变分自编码器)。
重构误差仍然使用KL散度(具体推导过程可见文献[2])。
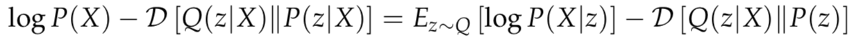
可以看到,图中右边使用了重参数化。这是由于从decoder到优化均值方差的过程没有办法实现梯度反转。因此,可以基于一个数学事实规避这个问题:
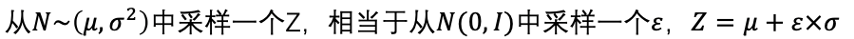
至此,模型结构及参数优化的过程已经介绍完毕。接下来看看VAE在文本生成中的应用方法。
2.文本生成
首先,我们需要明确一个问题:为什么在char-RNN能够得到不错结果的前提下,仍需使用VAE进行文本生成?
回顾一下可以发现,RNN在文本生成的过程中,是根据前一个词和记录着以往状态的隐藏层共同预测下一个词出现的权重。然而,这种方式没有学习到连续潜在的句子表示。
Samuel R. Bowman在Generating Sentences from a Continuous Space中使用VAE进行文本生成。这种方法可以找到两个不想干的句子之间的变换过程。模型结构非常简单,如下图:
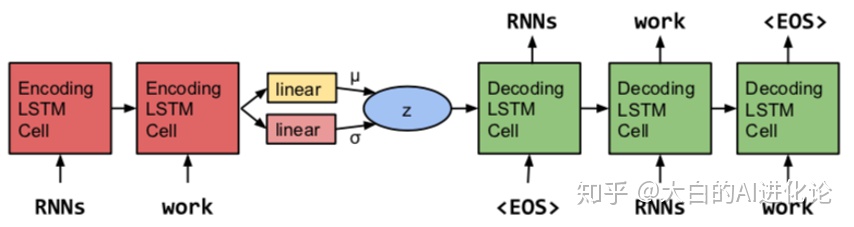
从图中可以看出,Samuel R的模型整体上还是使用VAE,只是将其中的encoder和decoder换成了LSTM,且编码器中接入了两个线性层,得到的结果也从实际样本的均值和方差变为LSTM隐藏分布的均值和方差;然后从中采样得到隐藏变量,并将其作为decoder的初始hidden state;最后,利用decoder完成重构。标准自编码器和VAE均可学习到的空间中,任意两点连线上可以找出间隔均匀的几个点,并解码成句子(一个点代表一个句子)。对比二者的结果,使用VAE的解码的句子明显更加顺畅,也保证了句法一致,语法正确。

这篇文章有意思的点在于优化时采用的两种策略:
(1)模拟退火(降低KL cost)
(2)word dropout
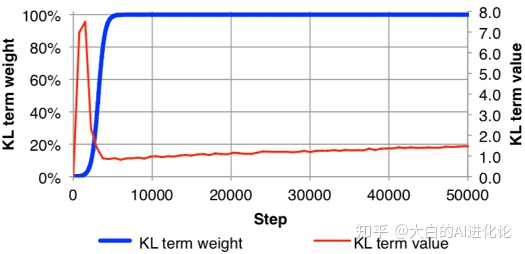
模拟退火技术其实算是一个小技巧。在训练时,对KL项赋予权重系数,为使p(Z|X)能够将x的信息encode到z中,将其初始系数大小设置为0。并随着训练step增加至1。一开始,KL term value急剧增加,VAE模型试图将的信息编码进,但当KL term weight达到100%时,KL项就收到惩罚而下降,最终缓慢增加。
word dropout的用法与nlp其他技术中的用法类似。在训练过程中,为了使decoder不仅仅依靠前面生成的词语来预测下一个词,而是依赖于,对decoder的部分输入词进行替换<unk>,相当于对decoder进行了弱化。
作者通过填空题的实验展示了他们得到的结果。

可以看出,VAE得到的结果比RNN更加通顺且包含更大的信息量。
我们尝试使用VAE模型自动生成自然文本,效果如下:

四、问题与难点
通过人工智能的方法进行长文写作仍是自然语言生成的难点之一。人们在写作过程中会自我衡量文章的逻辑关系和表达是否清楚,而机器看到的仅仅是文字表面。现在的文本生成中有很多控制机器生成与某一主题相关的自然文本,但是掌握控制机器的度很难拿捏。控制的多,生成的文章会死板,缺少趣味性;控制的少,生成的文章又缺少逻辑,主题不明确。若想使机器具备和人一样的写作能力,还需要推理和常识的帮助。不过,相信未来对文本生成的研究是有很大的发展前景的,期待有更好玩的文本生成研究。
参考文献
[1] The Unreasonable Effectiveness of Recurrent Neural Networks, http://karpathy.github.io/2015/05/21/rnn-effectiveness/
[2] Tutorial on Variational Autoencoders, arXiv: 1606, 05908
[3] Generating Sentences from a Continuous Space, arXiv: 1511, 06349















 971
971











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









