





1.背景介绍
数据集是由kaggle平台提供的2013年9月欧洲持卡人通过信用卡进行的交易。
https://www.kaggle.com/mlg-ulb/creditcardfraudwww.kaggle.com此数据集显示了两天内发生的交易,在284,807笔交易中,有492起欺诈。数据集高度不平衡,“欺诈”占所有交易的0.172%。 由于机密性问题,无法提供有关数据的更多背景信息。特征V1,V2,…,V28是使用PCA获得的主要特征,尚未通过PCA转换的特征是“Time”和“Amount”。 特征“Time”包含数据集中每个交易和第一个交易之间经过的秒数。 特征“Amount”是交易金额。 特征“Class”是响应变量,在发生欺诈时其值为1,否则为0。
2.提出问题
如何准确快速识别是否发生信用卡欺诈盗刷?如何通过所获得的数据构建逻辑回归模型和随机森林模型来判断是否发生信用卡欺诈?
3.理解数据
#导入相应的包与模块
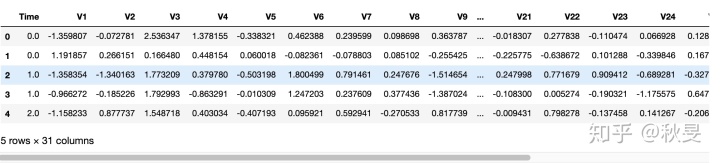
#查看数据集信息
从以上的数据探索中,我们可以看到这个数据集一共有30个特征,有28个变量由于敏感原因,数据提供商已经将变量的具体描述性名称和定义去掉,没有发现空值
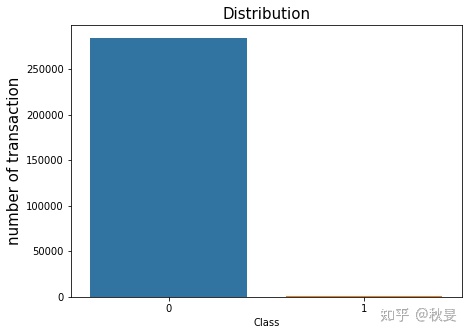
#我们首先看一下正常交易和盗刷之间的比例
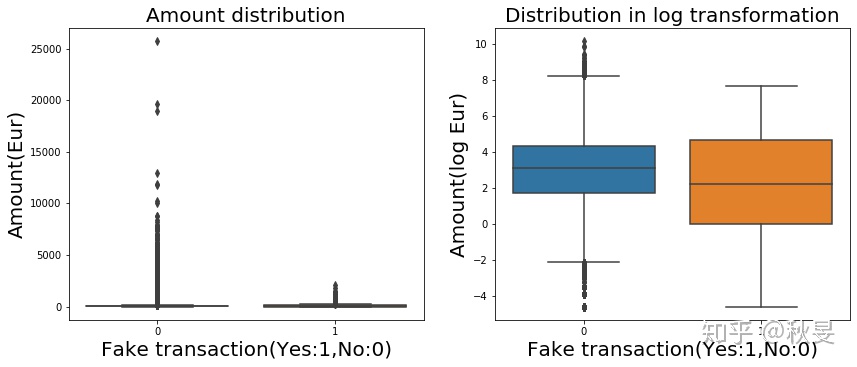
#我们看一下正常交易和盗刷之间的交易金额的统计结果
从分布可以看出,盗刷的卡在25%到75%分位点的分布其实比较宽,而正常交易其实有很强的长尾效应,我们做一些可视化的展示。
#绘制箱型图
#从其他特征进行探索数据
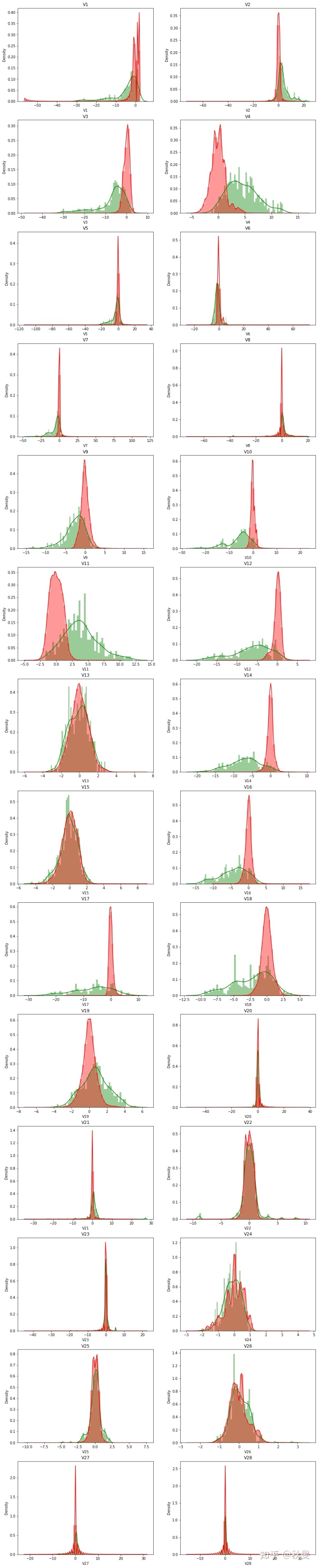
#从交易时间对数据进行探索
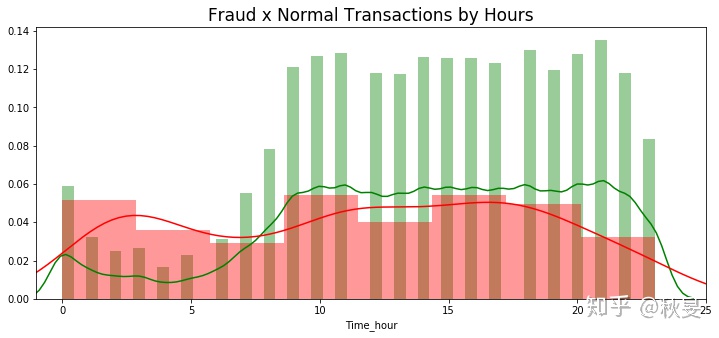
4.逻辑回归和随机森林模型的建立来预测金融欺诈
4.1数据预处理
4.1.1 对特征进行标准化
#数据标准化处理
4.1.2用SMOTE模型进行采样
#由于sklearn函数包不能识别dataframe数据结构,所以需将数据分为x,y分别指数输入变量和预测变量
4.2特征工程
本数据集已经经过PCA降维处理过,故不在做多余处理,直接划分处理后的数据集
#训练集与测试集数据集划分
4.3模型构建
4.3.1逻辑回归模型
#实例化模型
模型评估
print4.3.2随机森林模型
#建立随机森林分类器
模型评估
print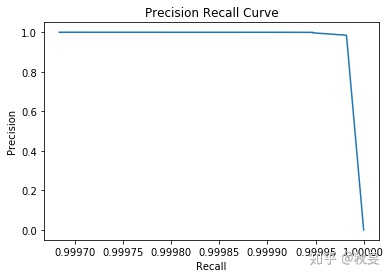
#根据特征重要性按权重绘制图片
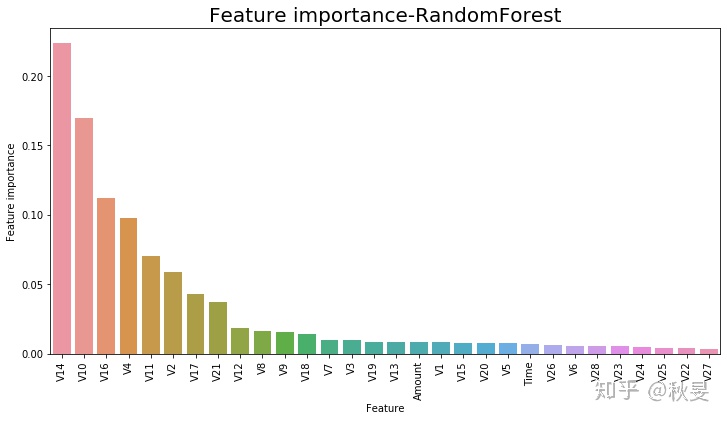
可以看出,排在前8名的分别为V14、V10、V16、V4、V11、V2、V17、V21,其余特征的重要性较弱,可重点关注前八个特征。
结合两个模型的recall和Precision Recall Curve以及roc_auc_score,随机森林的模型更好。















 1094
1094











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









