





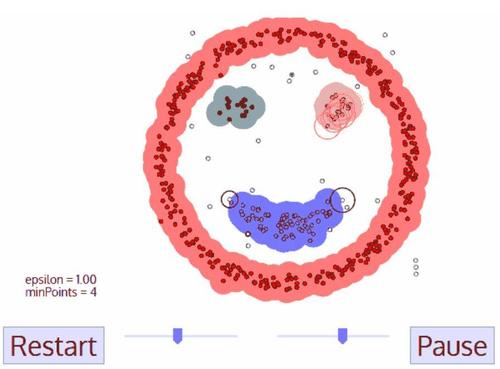
上期Lab介绍了DBSCAN算法优势、概念原理、案例讲解。本篇文章将分为两部分:第一部分基于sklearn实现DBSCAN算法;第二部分将介绍DBSCAN算法的改进模型。
sklearn (Scikit-learn) 是机器学习中常用的第三方模块,对常用的机器学习方法进行了封装,包括回归(Regression)、降维(Dimensionality Reduction)、分类(Classfication)、聚类(Clustering)等方法。
1. 基于sklearn实现DBSCAN算法
- ·第一步:导入相关包
import ·第二步:创建数据集并作可视化处理
%matplotlib inline #(使图形在jupyter notebook网页中显示)
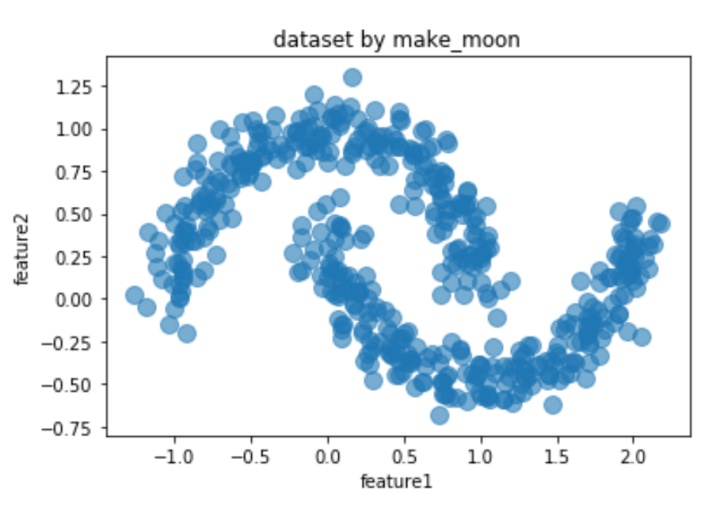
data,_ = datasets.make_moons(500,noise = 0.1,random_state=1) #创建数据集
df = pd.DataFrame(data,columns = ['feature1','feature2']) #将数据集转换为dataframe
#绘制样本点,s为样本点大小,aplha为透明度,设置图形名称
df.plot.scatter('feature1','feature2', s = 100,alpha = 0.6, title = 'dataset by make_moon')得到样本数据的散点图:
- ·第三步:DBSCAN实现
# eps为邻域半径,min_samples为最少点数目
core_samples,cluster_ids = dbscan(data, eps = 0.2, min_samples=20)
# cluster_id=k,k为非负整数时,表示对应的点属于第k簇,k为簇的编号,当k=-1时,表示对应的点为噪音点
# np.c_用于合并按行两个矩阵,要求两个矩阵行数相等,这里表示将样本数据特征与对应的簇编号连接
df = pd.DataFrame(np.c_[data,cluster_ids],columns = ['feature1','feature2','cluster_id'])
# astype函数用于将pandas对象强制转换类型,这里将浮点数转换为整数类型
df['cluster_id'] = df['cluster_id'].astype('int')
# 绘图,c = list(df['cluster_id'])表示样本点颜色按其簇的编号绘制
# cmap=rainbow_r表示颜色从绿到黄,colorbar = False表示删去显示色阶的颜色栏
df.plot.scatter('feature1','feature2', s = 100,
c = list(df['cluster_id']),cmap = 'rainbow_r',colorbar = False,
alpha = 0.6,title = 'DBSCAN cluster result')输出聚类后的散点图:
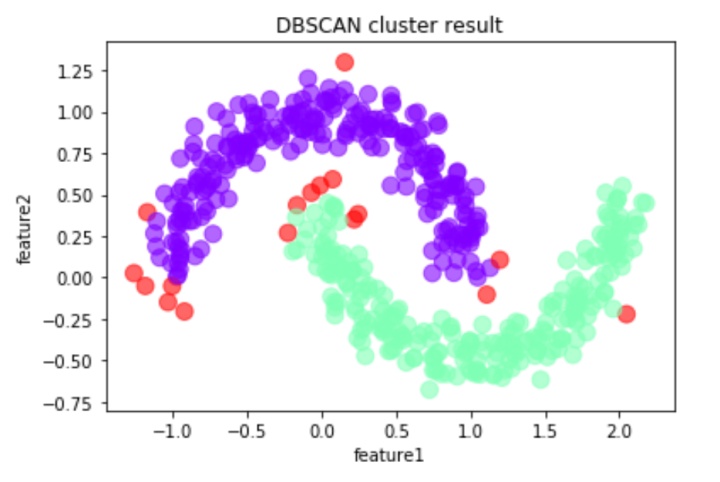
绿色点构成簇1,紫色点构成簇2,红色点为噪音点
2. WS-DBSCAN 算法
DBSCAN 算法在交通领域应用广泛,仍以出行行为分析为例,该算法的确可以从乘客历史出行链中提取空间出行分布特征。然而,DBSCAN算法的主要缺点在于其欧氏距离计算的复杂性,这一问题限制了大城市公共交通运营部门以日为单位更新乘客的出行模式。为提高该算法的效率,同时保证聚类的精度, Kieu 等人提出了 WS-DBSCAN(Weighted-Stop Density-Based Scanning Algorithm with Noise) 算法。
与典型的 DBSCAN 算法相比,WS-DBSCAN 算法有如下特征:
- DBSCAN在分析数据时,属于一次性分析,每组不同的数据需要重新分析;而WS-DBSCAN会充分利用现存(旧)数据的特征分析新数据。
- DBSCAN会对所有点的邻近区域搜索,从而确定该点类别;而WS-DBSCAN只在必要时才对该点邻近区域实施搜索。
- WS-DBSCAN在聚类时,会给予点属性,以该点邻近区域所有点属性值之和是否超过MinPts,作为判断是否为核心点的标准。
Kieu等人在DBSCAN算法定义的基础上,定义了
点p的权重ε邻域(weighted ε-neighborhood):
是p的邻近区域点q的权重,是点p的权重。
以站点为聚类对象,Kieu 对个体出行行为进行研究。将某一乘客在站点p的乘车(下车)次数记为该站点的权重。并分两个 level 分别对 origin stops 和 detination stops 进行聚类分析,并将与经典的 DBSCAN 对比。
作者提出只有当起讫点均为常规点时,该出行链才可被归为常规出行模式。如下图,O1-D1,O1-D2。:
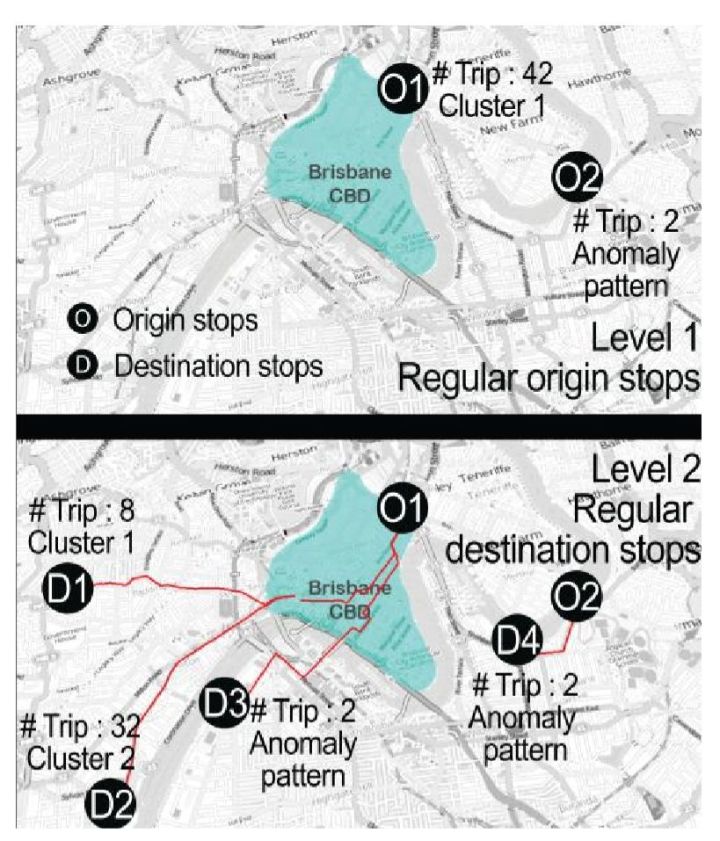
以Level 1: 起始站点聚类分析为例,WS-DBSCAN聚类算法流程如下:
- 历史站点数据集如下
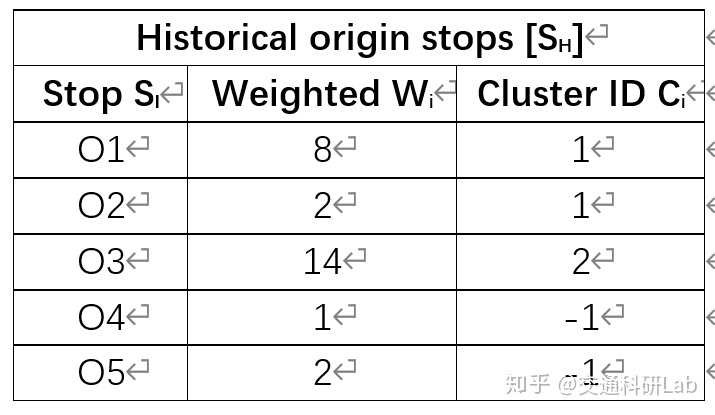
Cluster ID Ci = -1:该点为噪音点
Cluster ID Ci = k (k为非负整数):该点归属于簇k
- 研究站点如下

St的Cluster ID有三种可能:
- 归属于现存的簇,分配其对应的簇编号;
- 与已知点形成新的簇,分配其新的簇编号(编号为正整数);
- 该点为噪音点,分配编号为-1。
- 流程图
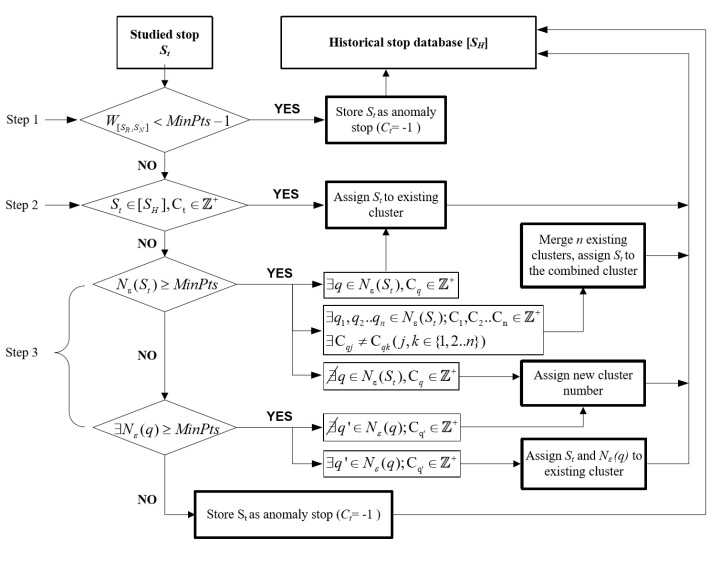
Step1:判断该点是否有继续研究的必要。如果Historical origin stops的权重之和小于MinPts-1,说明该点一定为噪音点;如果不是,执行Step2;
Step2:判断该点是否属于已知站点;如果不是,执行Step3
Step3:判断该点是否为a core stop:如果是,判断其属于哪个簇(从上到下依次为归属于一个已知簇,归属于多个已知簇,不属于任何已知簇);如果不是,判断其是否为a border stop,如果是,判断其属于哪个簇,如果不是,则将其归为噪音点。
- 数据实验
数据由城市智能卡的AFC数据提炼获得,分为两部分:历史数据集为2012年6月份前三周工作日的出行链数据;测试数据集为该月份最后一周数据。
数据字段包括卡ID,上下车时间,上下站地点等必要信息。
- 实验结果表明:
1) 当DBSCAN 与WS-DBSCAN 邻域参数相同时(ε=1000m, MinPts=8),二者处理得到的聚类结果相同,但 WS-DBSCAN 计算时间约为 DBSCAN 的0.46%。

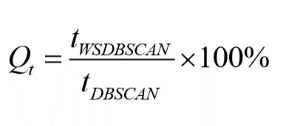
2) WS-DBSCAN 的计算速度受历史数据集的OD对数、出行次数的影响。OD对数越小,出行次数越多,WS-DBSCAN 的计算速度越快。
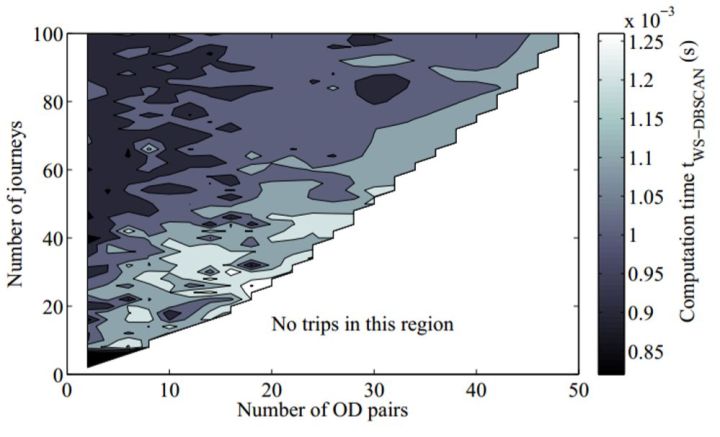
从图中可以看到,在OD对数量接近出行次数时,WS-DBSCAN 的计算速度有部分增加,但该部分乘客不到总乘客数量的3%。
DBSCAN算法就到此结束啦,如果内容对您有益,请点赞、转发、关注我们,您的鼓励和支持是我们创作的最大动力!
欢迎关注【交通科研Lab】公众号,所有文章均在公众号第一时间发布!
参考文献:Kieu L M, Bhaskar A, Chung E. A modified density-based scanning algorithm with noise for spatial travel pattern analysis from smart card AFC data[J]. Transportation Research Part C: Emerging Technologies, 2015, 58: 193-207.















 682
682











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









