





本篇主要来自《信用评分工具》一书的8.4相关系数。对于pearson和spearman相关系数不再赘述,以下为洛伦兹曲线、基尼系数和ROC曲线。该章节在书中的标题为“相关系数”,而洛伦兹、基尼和ROC我们一般是作为衡量区分度的指标,可能感觉与标题不太相关,但其内涵是一致的,比如信用评分的区分度越高,其在低分档的违约人群比例要高于高分档,那么实际上信用评分与违约率是存在较高的负相关的,因此这三个指标实际上衡量的也是相关性。
1、洛伦兹曲线
洛伦兹曲线来源于经济学,用于描述社会收入不均衡的现象。将收入降序排列,分别计算收入和人口的累积比例,并将其分别作为y和x绘制曲线。如下图所示:
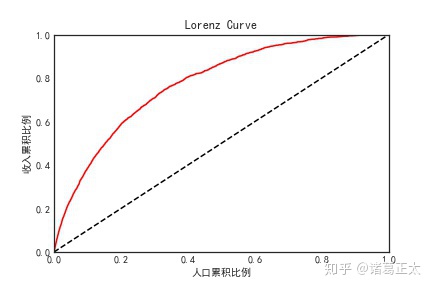
首先,极端的情况下,每个人的收入都是一样的,那么每个人的收入就等于人均收入,则收入累积比例一定会等于收入累积比例,也就是图中的对角线,表示的是绝对的财富均衡。而实际上,我们是按照收入降序来分别计算收入的,头部的高收入群占人口总数较少,但其收入占全体收入的比例却很高,即随着收入的下降,收入累积占比优先于人口累积占比迅速上升,最后增加较少,而人口累积占比在低收入段的增长却会大于收入累积占比,从而表现出上图中向左上凸起的曲线,这条曲线约贴合于y轴,则说明收入越不平等,极端的情况下,1%的人口占了99%的收入,则该曲线基本呈直角的折线。
洛伦兹曲线应用于信用评分,则是将信用评分按照升序排序,x轴仍是统计人数累积占比,而y轴则统计tpr(请参看前面章节内容),其业务指导意义为类似上面,随着信用评分的提高,tpr的增长快于整体样本人数比例,说明更多的违约人群集中在低分段,曲线约贴合y轴,说明对于违约与未违约的区分度越高。python代码如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('seaborn-white')
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
data = pd.read_excel('score.xlsx', index = False, header = 0)
def lorenz_curve(score_df, score, y, path):
'''
绘制洛伦兹曲线
score_df 信用评分表
y 是非违约字段的名称
score 信用评分字段的名称
path 输出路径
'''
total = score_df.shape[0]
total_bad = score_df[y].sum()
score_df = pd.crosstab(index = score_df[score],
columns = score_df[y]).fillna(0).sort_index(ascending = True)
#按照分数升序排列
score_df['total_rate'] = score_df[0] + score_df[1] #计算每个分数下实际违约与未违约人数之和
score_df['total_rate'] = score_df.total_rate.cumsum() / total #计算人数的累积比例
score_df['tpr'] = score_df[1].cumsum() / total_bad #计算tpr
plt.plot(score_df.total_rate, score_df.tpr, c = 'r')
plt.plot([0, 1], [0, 1], c = 'black', linestyle = '--')
plt.xlabel('样本人数累积比例')
plt.ylabel('tpr')
plt.title('Lorenz Curve')
plt.xlim(0, 1)
plt.ylim(0, 1)
plt.savefig(path)
plt.show()
lorenz_curve(data, 'SCORE', '是否违约', '洛伦兹曲线.jpg') 图形输出如下:
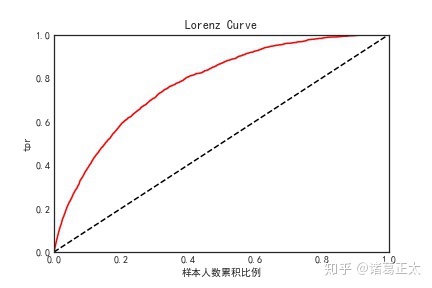
2、ROC曲线
ROC曲线的原理与洛伦兹曲线类似,只不过是将x轴换成了fpr(请参看前面章节内容),其形状也与洛伦兹曲线相似,也是向(1,0)点凸起的一道曲线。其含义也是类似,在低分段,以违约客户为主,tpr自然大于fpr,而随着分数的上升,tpr首先接近于1,而fpr开始快速增加,从而在曲线表现上,低分部分较为陡峭,而在高分部分则会变得平缓,整体向(1,0)点凸起。ROC曲线的绘制亦类似于洛伦兹曲线,具体可参看后面的代码。
ROC曲线从图形直观上展示了模型的区分能力,还会结合AUC(area under the ROC curve)来进一步量化。AUC为ROC曲线下的面积,其越大,则说明模型的区分度越好。其阈值标准一般如下:
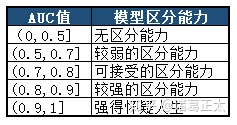
书中指出,AUC值等于1意味着模型完全正确,显然不太可能,另外,小于0.5代表模型基本上是错的,0则意味着预测完全错误。这一点从上述绘制过程即可以理解,因此一般而言其取值为(0.5,1)的开区间内。同时,书中还列出了一个AUC的计算公式,可以进一步帮助我们理解其含义,该公式为:
其中
3、基尼系数
这里有一个可能会产生混淆的地方。一般而言基尼系数应该是洛伦兹曲线与对角线之间的面积与上半三角之间的比值。如下图所示:
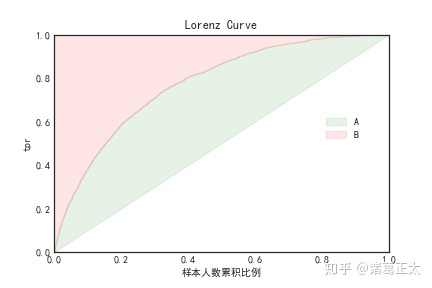
基尼系数为绿色区域的面积与绿色与红色区域面积和的比值,即
那么这个式子是如何推导出的呢。我们知道x轴和y轴都限定在[0,1]的区间内,所以整个坐标区域的面积为1,而对角线刚好把整个坐标区域分为相等的两部分,每个的面积都为0.5。AUC未整个曲线以下的面积,那么如果要求区域A的面积,实际就是AUC-0.5,而上半三角的面积亦为0.5,整个过程如下:
基尼系数也是越大越好,其业务意义可以参照上文对于洛伦兹曲线和ROC曲线的介绍理解。其阈值一般为:
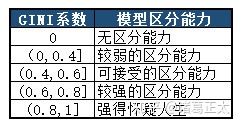
最后,ROC曲线以及AUC值和GINI系数的计算代码:(以下代码从ROC和AUC的逻辑出发进行计算,以方便理解。sklearn中有专门计算AUC值的函数,为sklearn.metrics.roc_curve)
def roc_curve(score_df, score, y, path):
'''
绘制ROC曲线,并返回AUC值和GINI系数
score_df 信用评分表
y 是非违约字段的名称
score 信用评分字段的名称
path 输出路径
'''
total = score_df.shape[0]
total_bad = score_df[y].sum()
total_good = total - total_bad
score_df = pd.crosstab(index = score_df[score],
columns = score_df[y]).fillna(0).sort_index(ascending = True)
#按照分数升序排列
score_df['tpr'] = score_df[1].cumsum() / total_bad #计算tpr
score_df['fpr'] = score_df[0].cumsum() / total_good #计算fpr
auc = np.trapz(score_df.tpr, x = score_df.fpr)
gini = 2 * auc - 1
plt.plot(score_df.fpr, score_df.tpr, c = 'r', label = 'AUC = {:.4f},GINI = {:.4F}'.format(auc, gini))
plt.plot([0, 1], [0, 1], c = 'black', linestyle = '--')
plt.xlabel('fpr')
plt.ylabel('tpr')
plt.title('ROC Curve')
plt.xlim(0, 1)
plt.ylim(0, 1)
plt.legend()
plt.savefig(path)
plt.show()
return auc, gini
roc_curve(data, 'SCORE', '是否违约', 'ROC曲线.jpg') 图形显示如下:
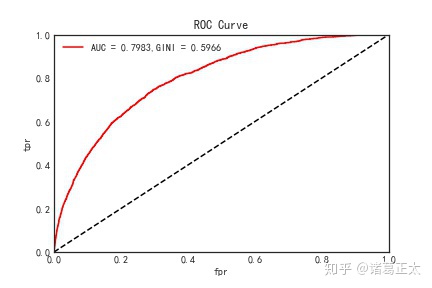
从上图可知AUC为0.7983,GINI系数为0.5966。
最最后,做个实验,看看AUC值是否代表了随机抽取一个未违约客户和一个违约客户,违约客户的分数不大于未违约客户的概率。
good_df = data[data.是否违约 == 0]
bad_df = data[data.是否违约 == 1]
auc_list = []
for i in range(10): #工作10次实验
good_larger = 0 #用于统计未违约客户分数大于违约客户分数的次数
good_equal_bad = 0 #用于统计二者分数相等的次数
for j in range(100000): #每次实验随机抽取10万次
temp_good = np.random.choice(good_df.SCORE, size = 1)[0]
temp_bad = np.random.choice(bad_df.SCORE, size = 1)[0]
if temp_good > temp_bad:
good_larger += 1
elif temp_good == temp_bad:
good_equal_bad += 1
auc_list.append(good_larger / 100000 + 0.5 * good_equal_bad / 100000) #根据书中的公式进行计算
print(auc_list) #查看每次实验的AUC值
print(sum(auc_list) / 10) #计算十次实验的均值结果输出如下:

可以发现,无论是每次实验的AUC值还是十次的均值,都与上面计算的AUC值结果相差不大。















 9550
9550











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









